This article is taken from the book Wicket in Action by Martijn Dashorst and Eelco Hillenius and
published by Manning Publications. This segment covers Wicket labels and links. For the table
of contents, the Author Forum, and other resources, go to http://www.manning.com/dashorst/.
Apache Wicket is an open source Java component oriented web framework. With Wicket you build web applications
using just Java and HTML. This article is an excerpt from the Wicket in Action book where we take a closer look at two
types of components that are provided by the Wicket framework. First we'll look at components that render text:
labels. Next we'll look at components that allow you to provide navigation in your application: links. If you want to
learn more about Wicket or Wicket in Action see the list of resources at the end of this article. Let's take a closer look
at displaying text with labels.
Displaying text with label components
Displaying text with label components} As we mentioned earlier, the first incarnation of the web was static: all pages
consisted of hard-coded text, with links between the pages. Soon people wanted to show dynamic text on their
websites, such as visitor counters, the current date, news headlines, product data from a database, and so forth. In
this section, you'll see different components that display dynamic text. The first component is one you've seen already
on numerous occasions: the Label.
Using the Label component to render text
The Label component is used to display text. The text can be anything: for example, the name of a customer, a
description of a cheese, the weight of a cheese, the number of items in a shopping cart, or a fully marked up
Wikipedia article. In previous chapters, we've presented many examples that show the Label in action. For instance,
the front page of our cheese store contains many labels. Figure 1 identifies the labels on a screenshot of that page.

Figure 1: Identifying Label components on the front page of chapter 3's cheese store.
Each label is responsible for displaying asingle aspect: the cheese's name, description, or price.
As a reminder of how labels work in code, let's return to the Hello World example shown in listing A
Listing A: Rendering the Hello World example with a Label component
<!-- markup file -->
<span wicket:id="message">text goes here</span>
// java code
add(new Label("message", "Hello, World!"));
<!-- final rendered markup -->
<span wicket:id="message">Hello, World!</span>
The Label component is bound to the span tags in our markup using the component identifier message. The
contents of the span tags are replaced by the text we provide in the Java code, as evidenced by the final markup. In
this example, we provide the label directly with a string, but this isn't the only way for a label to obtain the text to
display. You can pass in any model implementation? for example you could use the compound property model which
would use the component identifier to give the label access to the display text (see also section 4.2.3). When the
model value isn't a String, Wicket will convert the model value to a String using the registered convertors. When
no convertor could be found Wicket will call the model value's toString method to convert the model value to a
String. See chapter 12 for more information on convertors.
In our examples, we often use the span tag to create a label, but labels aren't limited to the span tag. You can
add a label to almost any tag in your markup. The only caveat is that the markup must have a content body. For
instance, it doesn't make much sense to attach a Label component to img tags. Listing B shows some possible
markup choices for a Label component.
Listing B: Examples of markup with a Label component attached
<!-- markup -->
<span wicket:id="label1">Will be replaced</span>
<td wicket:id="label2">[name]</td>
<h1 wicket:id="label3">title goes here</h1>
Name: <span wicket:id="name"></span>
<div wicket:id="label4"></div>
/* Java code */
add(new Label("label1", "Hello, World!"));
add(new Label("label2", new PropertyModel(person, "name")));
add(new Label("label3", "Wicket in Action"));
add(new Label("name"));
add(new Label("label4", new ResourceModel("key", "default"))); #A
<!-- output -->
<span wicket:id="label1">Hello, World!</span>
<td wicket:id="label2">John Doe</td>
<h1 wicket:id="label3">title goes here</h1>
Name: <span wicket:id="name">Parmesan</span>
<div wicket:id="label4">standaard waarde</div> #B
#A Internationalized text
#B Dutch for "default"
As you can see, the label works the same way even when attached to different markup tags. The Label component
replaces anything inside it with the text that comes from the provided model (in this example, the provided strings).
Listing B also shows several ways to provide the text to display: a static string, a property model, a compound
property model, and a resource model (used to provide internationalized messages, as discussed in chapter 12).
NOTE: You can nest example markup for preview purposes within a label's tags, but you can't nest Wicket components
inside a label. If you do, it will result in an exception. At render time, the label replaces everything between the
start and end tags, including any markup if present.
A Label component is great for displaying short amounts of text such as names, weights, dates, and prices. But how
do you display longer text, such as descriptions, and preserve multiple lines?
Displaying multiple lines using a MultiLineLabel
Often, you'll get text from a user (for instance, through a comment form on a blog) that contains basic formatting
created using newlines. As you may know, HTML ignores most whitespace if it isn't contained in <pre> tags. How can
you display strings that aren't HTML but that contain basic formatting in the form of newline characters? Listing C
shows a page that exhibits this problem.
Listing C: Displaying a preformatted message that spans multiple lines
/* java code */
public MyPage extends Webpage {
public MyPage() {
add(new Label("message", "Hello,\nWorld!\nI'm super!"));
}
}
<!-- markup -->
<html>
<body>
<span wicket:id="message">Text goes here</span>
<body>
<html>
In this example, we want to display the text "Hello, World! I'm super!" across three lines.
If you run the example, you'll see that this doesn't happen. Your browser reformats the text and puts
it all on the same line. To solve this problem, Wicket has a special Label component that
takes into account multiple text lines: the MultiLineLabel.
The MultiLineLabel inserts line breaks (br tags) for single-line breaks in your text and paragraph tags (p tags)
for multiline breaks in your text. In our example, the code renders as follows:
<span wicket:id="message"><p>Hello,<br/>World!<br/>I'm super!<br/></p></span>
This gives the desired result, as shown in figure 2, which displays the output of a normal label
and a multiline label next to each other.

Figure 2: Comparing the output of a normal label and a multiline label when using Java formatting inside the model text
Now that you know how to render plain text containing basic formatting, how can you render text that needs to be
bold or italic, or a heading inside a label?
Displaying formatted text using labels
Sometimes, you want to display more than just the name of a cheese. You may want to stress part of your message
or display user-generated formatting. Because you're working in a web environment, and the lingua franca for
controlling formatting is HTML, it's logical to provide the label with HTML markup inside the text.
What happens when you give the label some markup in its model? Look at the following snippet:
<!-- markup -->
<span wicket:id="markup"></span>
/* Java code */
add(new Label("markup", "<h1>Hello!</h1>"));
Using this code, we expect the text "Hello!" to be displayed in big, bold letters.
But this isn't the case. Figure 3 shows the undesired result together with the desired output.

Figure 3: Label with and without escaped markup.
Using setEscapeModelStrings, you can tell Wicket not to escape markup tags
and to display formatted HTML the way it was intended.
The left screenshot isn't what we expect: instead of big, bold text, we get the cryptic markup we put in the label. The
tags we put into the label have been escaped, presenting us with the verbatim contents instead of the properly
formatted value. In the following, you can see how Wicket has rendered the contents in the final markup:
<span wicket:id="markup"><h1>Hello!</h1></span>
Wicket has escaped the < and > characters and replaced them with their corresponding XML entities (< and >
respectively). By setting a flag on the component, you can tell Wicket to render the contents without escaping. Look at
the next Java snippet:
add(new Label("markup", "<h1>Hello!</h1>").setEscapeModelStrings(false));
The call to setEscapeModelStrings tells Wicket not to escape the contents of the provided string, and to render
the contents into the resulting markup. This did the trick, as you can see in the right screenshot in figure 5.4. Note
that this setting is available on all Wicket components, but it's primarily useful on labels.
Beware of script injection attacks
When you give your users the ability to enter HTML markup into your application, through either a text input field or
a text area, and you render this directly back to the client, the users can play dirty tricks by injecting JavaScript into
your pages. Such tricks can range from opening pages on other websites (spam) to more dangerous exploits like key
loggers recording credit-card information and passwords. Most browsers prevent cross-site scripting (XSS), but you
can't be careful enough when it comes to security.
As an example, if we change the model of our label to the following, and escaping is turned off, clicking the message
results in a pop-up:
"<h1 onclick='alert(\"clicked!\");'>Click me</h1>"
Be careful when you open up this possibility, and filter the markup to remove any scripting before you store it.
Displaying text on the web is rewarding in its own, but if your users are unable to navigate to the page that contains
the text, it's virtually useless. Let's return to table 5.1 and continue with the next category of components:
navigational links.
Navigating using links
Taking a stroll down memory lane, the internet was once called the information superhighway (yes, we're that old). If we
use that term, it isn't hard to imagine that the exits are formed by links. On a normal highway, an exit takes you off
the highway to places where you stop to do things: shop, work, relax, or see a movie. The same holds for links: they
may take users to our cheese store, where they can buy cheese for lasagna; to an administrative system that will help
them work; or to YouTube for some Friday afternoon entertainment.
Wicket provides several abstractions for links. There are links suited to perform an action (and navigate afterward),
links that navigate only to another part of an application, and links that navigate to another website. In this section,
we'll take a closer look at the navigation links listed in table 5.1. Let's first discuss static links to external websites.
Linking to documents using static links
In plain markup, you typically link between pages using the <a href> tag. This tag contains the URL of the document
you're linking to. For instance, Wicket is an example of a link to
the Wicket home page. You can use this type of link directly in your Wicket pages.
Static links can be useful in web applications or websites. Perhaps you want to link to the Wicket website by
displaying a 'Powered by Wicket' logo, or provide a link to your corporate intranet site or another web application. As
long as the link is static, in the sense that you don't need to retrieve the link from a database or construct it using
Java code, you can add the link directly to the markup of your page. Let's see how that looks on our Hello World page
by adding a Powered by Wicket link. Listing D shows the corresponding markup.
Listing D: An example of a static link in the markup of a Wicket page
<!-- markup -->
<html>
<body>
<h1 wicket:id="message">[text goes here]</h1>
<a href="http://wicket.apache.org">Powered by Wicket</a>
</body>
</html>
/* Java code */
public HelloWorldPage extends WebPage {
public HelloWorldPage() {
add(new Label("message", "Hello, World!"));
}
}
As you can see, the <a href> tag doesn't contain a Wicket component identifier, and it's seen by Wicket as static
markup. The Java code for this page only adds the Label component: there is no Java counterpart for the static link.
This is fine when you know the exact URL up front and the URL remains static, but how can you create links to an
external site when the URL comes from an external data source (such as a database)?
Using ExternalLink to render links programmatically
To enable our plan for world cheese domination, wouldn't it be nice to link to recipes using each cheese? This would
definitely increase sales, because our customers could immediately see ways to use a particular cheese. Say we find a
partner that already has a recipe website with many recipes containing cheese. All we need to do is link our cheeses to
the recipes. We add a recipe concept to our domain model, including a name and the URL to the recipe.
Now that we have a way to store a URL to the recipe, how can we render it into our page? Using the
ExternalLink component, we can link to any URL on the web and have the URL come from anywhere. The next
snippet shows how to link to recipe that uses a cheese:
add(new ExternalLink("link", recipe.getUrl(), recipe.getName()));
In this example, we generate the URL and the contents of the link. For a good lasagna recipe, this would generate the
following:
<a href="http://recipes.com/lasagna">lasagna</a>
If you don't provide contents for the link, it keeps what is in the original markup template. It's also possible to use
models with the external link for both the URL and contents:
add(new ExternalLink("link", new PropertyModel(recipe, "link"),
new PropertyModel(recipe, "name"));
The external link is an easy way to create links to external content from within your Java code. Static links are handy
to link to externally available resources, but how do you link to pages inside your Wicket application? Several
possibilities exist for navigating between pages, including BookmarkablePageLinks.
Linking to Wicket pages with BookmarkablePageLinks
Imagine a highway on which you can create your own exits – exits that take you directly to your destination, without
detours. The links you've seen thus far give you access to predefined locations, usually outside your control. With the
BookmarkablePageLink component, you can give others direct access to locations inside our application.
When you create a BookmarkablePageLink to point to a Wicket page, it renders a link that enables Wicket to
create the page later, without having any previous knowledge of where the user has been. The link can be shared with
other people and can be retrieved at any time, even when the user hasn't visited the site in a long time. For example,
your home page, the details page for a cheese, a blog entry, and a news article are all prime examples of good pages
to link to. Basically, anything your customers want to share with one another?typically by sending a link over e-mail?
or want to remember for future reference is a good candidate to be accessed through a BookmarkablePageLink.
Generating a link to a page for use in emails
When you want to send a user a link to a page in your application you can use the urlFor method to generate the
URL to the page. The next snippet generates a link to a registration confirmation page:
String url = urlFor(ConfirmRegistrationPage.class, new PageParameters("id=" + registrationId));
String msg = "Click on the following link:\n\n" + url + "\n\nto confirm your registration.";
The urlFor method is also used to generate URLs to event listeners or resource listeners. It is a method on the
Component class so you can use it almost anywhere.
As an example, we'll add a details link to each cheese on the front page. The link will point to a details page for each
cheese; this page will show information about the linked cheese. Using this example, we'll show the various ways of
creating links to Wicket pages.
We need a link tag in our markup file and a corresponding BookmarkablePageLink component in our Java file.
Listing E shows how to create a bookmarkable link to the details page.
Listing E: Creating a bookmarkable link
<!-- markup -->
<a href="#" wicket:id="link">more information</a>
/* java code */
add(new BookmarkablePageLink("link", CheeseDetailsPage.class));
The <a href> tag has an href attribute containing #. This is done to show a proper link in the document when we
preview it in the browser; Wicket will replace it with the URL of the page the link is pointing to. The Java code adds the
link to the component hierarchy and tells Wicket to create the CheeseDetailsPage page when the link is clicked.
Figure 4 shows how our front page looks after we've added the More Information link

Figure 4: Adding a bookmarkable link to the front page of our cheese store.
It links to a details page for each cheese. The screen on the
right shows the details page after we clicked the link.
Our current implementation of the link has one problem: we haven't specified the cheese for which we want to show
details! When the cheese details page is created, how do we know which cheese's details should be shown? We need
to provide the details page with more information. The link generates a URL that contains all the information needed
to create the page. URLs can contain request parameters that are passed to the page, so the page can react to that
information. Wicket encapsulates those request parameters in PageParameters.
Adding parameters to a bookmarkable page link
First we need to consider what you can put into URL parameters. According to internet standard RFC-1738, a URL may
consist only of alphanumerics: 0-9, a-z, and A-Z. Special characters and whitespace must be escaped. This means
that we have to convert Java objects into string representations before we can use them as URL parameters.
Given the URL's limitations, we can't just put a cheese object into the URL. Even if it were possible to pack all the
details of the cheese into the URL, doing so wouldn't be appropriate, considering that the URL can be bookmarked and
stored for a long time. If someone bookmarks a cheese with a discount price of, say, $1 and then opens the bookmark
two months later when the price has returned to $2.50, that would be a bummer. Plus, a malicious user could attempt
to modify the URL and change the price directly. Instead of storing the whole object into the URL, you can store a
unique property based on which you can reconstitute the object. The object identifier is a good candidate, as is a more
businesslike key such as a customer number or, in our case, the name of the cheese.
Let's assume we can load a cheese based on its name. We add the parameter to the URL in the following code:
PageParameters pars = new PageParameters();
pars.add("name", cheese.getName());
add(new BookmarkablePageLink("link", CheeseDetailsPage.class, pars));
Because the parameters are stored and rendered as strings, you can only add string values to the parameters. You
can add as many parameters to the link as you want, as long as you don't exceed the maximum URL length
(depending on the browser, about 2,000 characters for Internet Explorer and 4,000 for other browsers).
Without any specific configuration, Wicket generates the URL shown in figure 5.

Figure 5: The URL as generated by the bookmarkable link. The URL contains all the information
needed to create the details page and retrieve the cheese object based on its name.
This is by many standards an ugly URL. It looks complicated, it's long, and it shows information we'd rather hide from
our users, such as the package name. In chapter 14, we'll look at ways to generate prettier URLs.
Now that we have the link side covered, what happens when someone clicks the link? As you can see in figure 5.5,
the class name of the page is contained within the URL. Wicket tries to create that page. For this to work, the page
needs to be bookmarkable.
Getting your page to work with BookmarkablePageLinks
A page is considered bookmarkable if
- It has a constructor that has no arguments (also known as a default constructor), or
- It has a constructor that takes a PageParameters instance as the only argument
These are the only two constructors Wicket can invoke on its own. A page can have both constructors and
additional constructors with other parameters. But when called upon to
instantiate a page, Wicket prefers the constructor with PageParameters if it's available.
The next example shows a page with three constructors where two fall into the bookmarkable category:
public class CheeseDetailsPage extends WebPage {
public CheeseDetailsPage() { #1
}
public CheeseDetailsPage(PageParameters parameters) { #2
}
public CheeseDetailsPage(Cheese cheese) { #3
}
}
#1 Bookmarkable constructor
#2 Bookmarkable preferred constructor
#3 Non-bookmarkable type-safe constructor
In this example, Wicket doesn't use the default constructor #1, because Wicket always prefers the constructor with
PageParameters #2. But the default constructor is still useful inside your code, because it makes it (a bit) easier to
create the page yourself. As long as the page has either of these two constructors, it can be used successfully in a
bookmarkable link.
If the page had only the constructor with a Cheese parameter #3, it wouldn't be possible to reference it in a
bookmarkable link or, to be more precise, Wicket wouldn't know how to create a new instance of the page with only
the Cheese constructor, and would generate an error. This is the case because Wicket can't determine which cheese
needs to be passed in as a parameter. You can still use this constructor if you know how to get a cheese instance
based the page parameters. Listing F shows how to parse PageParameters and use the type-safe constructor.
Listing F: Parsing page parameters to retrieve a Cheese objectA
public class CheeseDetailsPage extends WebPage {
// bookmarkable constructor
public CheeseDetailsPage (PageParameters parameters) { #1
super(parameters);
Cheese cheese = null;
if (parameters.containsKey("name") { #2
String name = parameters.getString("name");
CheeseDao dao = ...;
cheese = dao.getCheeseByName(name);
}
createComponents(cheese);
}
// non-bookmarkable constructor
public CheeseDetailsPage (Cheese cheese) { #3
createComponents(cheese);
}
private void createComponents (Cheese cheese) {
// do cheesy stuff with the cheese
}
}
#1 Bookmarkable constructor
#2 Retrieve cheese using name
#3 Non-bookmarkable type-safe constructor
When the CheeseDetailsPage is created using the constructor with PageParameters #1 we parse the parameters
and retrieve the value for the parameter name #2. We call the createComponents method to create the component
hierarchy. This method is also called in our non-bookmarkable constructor #3 to avoid code duplication.
Parsing PageParameters
The PageParameters class lets you get converted parameters from the URL. For example, PageParameters
has a getInteger(key) method that looks up the key in the URL and tries to convert its value to an integer. If
this fails, it throws a conversion error.
People like to modify the URLs in their browser bar, so you may get strange requests to your pages. Wicket shows a
default error page if it encounters such malice. To show a friendlier page at a local level, you should surround the
querying of the page parameters with a try-catch block. In our example, we could show a page that proposes,
"Sorry we couldn't find the cheese you were looking for, but how about this Beenleigh Blue for just $10?
We've covered a lot of ground and let many concepts and components pass by. Let's take a break and let Wicket do all
the heavy lifting for us. All the links we've discussed so far require you to add links in both the markup and the Java
file. For simple links to pages and resources, it would be nice to automate this process.
Adding bookmarkable links automatically with wicket:link
Previously, we showed you how to create bookmarkable links to pages in your web application. To make this work,
you have to add the links to the markup and add a BookmarkablePageLink component to the page class. If you
have many pages that are accessible through bookmarkable links, this is a lot of work to do by hand. The special
wicket:link tags in a markup file instruct Wicket to automatically create bookmarkable link components for the
links inside the tags.
Let's see how this works with auto-linking to two pages. First, look at the markup file in the next example:
<html>
<body>
<wicket:link> |#A
<ul>
<li><a href="package1/Page1.html">Page1</a></li> |#B
<li><a href="package2/Page2.html">Page2</a></li> |#C
</ul>
</wicket:link>
</body>
</html>
#A Auto-link block
#B Links to com.wia.package1.Page1
#C Links to com.wia.package2.Page2
Wicket automatically creates components for these links when they point to existing pages based on the value of the
"href" attribute. In this example, Wicket auto-creates two bookmarkable links one to com.wia.package1.Page1
and the other to com.wia.package2.Page2 when the current page is in package com.wia.
Note that a link is rendered as disabled when it would point to the current page.
Figure 6 shows how this might look in your browser.
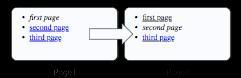
Figure 6 Auto-linking in action. The link to the current page is rendered as disabled by replacing
the link tag with a span, and rendering the text using an em-tag (this is configurable).
You can also use this auto-link facility to add links to packaged resources such as style sheets and JavaScript files (you
can learn more about this subject in chapter 9).
wicket:link saves manual labor: you don't have to add the bookmarkable links yourself. Note that
wicket:link is not refactoring safe: when you move pages between packages, you should modify the links inside
the wicket:link section in your markup as well. wicket:link is merely a convenience rather than an all
encompassing solution to your linking problems – especially when the links have to respond to user actions.
In this article, we looked at a some Wicket components: the basic ingredients that enable you to build web
applications using Wicket. You learned how to render plain text, formatted text, and text containing HTML to the
browser. Although rendering text containing HTML is handy and gives you and your users great power, you shouldn't
ignore the safety concerns that stem from this approach. Your site won't be the first to fall prey to insertion attacks.
Displaying content is important for any web application, but an application is more than a set of pages without
relationships. Using links, you can navigate to other websites with ExternalLinks or within your own application.
With BookmarkablePageLinks, you let users store a bookmark to a particular spot of interest in the application or
site (for instance, an article).
We hope that this article has interested you into learning more about Wicket and its components.
You can learn more about Wicket by reading the first chapter of Wicket in Action for free,
and by using the links provided in the resources.
Resources