In a previous article,
we took a first look at the authentication aspect of JAAS; now we'll look at authorization.
Before we start, it's important to understand the basics of the Java security model.
By default applications run (get interpreted) without a security manager, which means that there
are no restrictions in what the code is allowed to do. There are a number of issues in giving
untrusted programs full control of the JVM, as the following examples show.
Applets are downloaded from a remote site, but run on the client. If we give the applet code
full permissions then it is free to open a file and start appending junk data to it,
until finally that leads to a disk full errors. Or it can transfer confidential files elsewhere
over the network.
Denial of service attacks are another example. Suppose a web hosting company provides web
application server space for lease. If the server does not run with a security manager then
we can easily have a servlet call System.exit(0), which would bring the server down
any time we access the servlet.
From this discussion it should be clear why security functions are an integral part of Java.
This is a challenge for any portable language (this discussion also applies to Flash/Flex and
JavaScript), so the Java language designers have taken great care in handling the security aspects.
So how does a security manager help prevent these kinds of attacks?
First, let's have a look at Java permissions and policy files. The developer generally
documents the permissions required by his code to work properly (when running on a JVM with
a security manager enabled). It is quite likely that the freshly developed code will run on
someone else's JVM. So the person running the program must to go through the documentation
and grant the code with the required permissions (assuming that a security manager is used,
which we shall assume). Only then will the program be able to run. If the program is run
without granting proper permissions (using the policy file) and a security manager enabled,
then a variety of scary-looking security exceptions will be thrown. The policy file is used
to grant the required permissions to a piece of code. This is the core of JAAS authorization,
and we will dig deeper into it later in this article.
What is a Principal?
A Principal is a representation of a subject in our system. It's basically an implementation
of Principal interface. E.g., one could have a DepartmentName principal which represents the
department of an authenticated subject. So when the subject (e.g., an employee) is authenticated,
one might want to create a department principal which represents the respective department and
associate it that with that subject. This is the core of JAAS authorization. One can grant
various permissions to principals using a policy file. This is described in the next section.
But what if we want our code to be run only by a certain set of users? In this case
authorization enters the picture. JAAS authorization combines the permission domain of a
piece of code along with the permissions of a user before running the code. The previous
section explained the permission domain of the code, but what is the permissions domain
of the user? How do we grant permissions to individual users? This is done using a principal.
We grant principals with various permissions using the policy file (this is the same policy
file which we used to grant various permissions to our code). After the user is authenticated,
we populate the Subject with the principal. JAAS thus extends code based security to user
based security. Now only authenticated users having the required principal can invoke a
particular code/operation (because the principal in turn has the required permissions to
run that operation). But where is the actual code that associates the subject with the
access control context and runs the code? For that, we need to run our code in the following
manner, which takes care of associating the subject with the access control context.
For that we use the doAsPriviledged method of the Subject, and pass the authenticated
Subject as the first parameter, and as the second parameter the PrivilegedAction,
which is the code that should be run in the context of the newly created protection domain.
The third parameter is null, as we want an empty context to be used:
Subject.doAsPrivileged (subject, new PrivilegedAction() {
public Object run() {
System.setProperty("file.encoding", "ASCII");
return null;
}
}, null);
To understand the above piece of code, let's examine the basics of Java security again.
Firstly, the AccessController class, which performs security checks. Java has a method stack
(outside the heap space) where the currently executing methods live. Each stack can be considered
as an independent thread of execution. The AccessController checks whether the current stack
of methods has all the required permissions to invoke an operation or not. Some of its
important methods are:
static void checkPermission (Permission)
Used to determine whether the code has the required permissions mentioned in the parameter.
If it does, then the method returns quietly, otherwise, it throws a runtime exception.
Not only should the current call have the permission but the callers beneath it should
also have the required permission for this method to succeed.
public static Object doPrivileged (PrivilegedAction)
A caller can be marked as Privileged, which indicates that one does not want the
permission check to proceed further down the stack. In that case -if the caller has the
required permission- then it returns quietly without any exception. It will not go further
down the stack to find out whether all the methods beneath this method in the stack have
the required permissions as well. There's also an overloaded method that takes a
PrivilegedExceptionAction instead of a PrivilegedAction. This can be used in case the
operation throws a checked exception.
I would recommend to read the class level javadoc for the AccessController class.
It includes a good example of how to use it.
Now lets take a look at the authorization related methods defined in Subject.
There are two sets of interesting methods - doAs and doAsPrivileged.
The main purpose of these is to associate the authenticated subject with the the current
AccessControlContext. The only difference between these sets of methods is that, in the latter,
you can provide a AccessControlContext to use, while the former uses the current thread's
AccessControlContext. If the AccessControlContext is null when calling doAsPrivileged,
then it doesn't use the current thread's context, instead it creates an empty context
(which has not protection domain) and merges it with the subject. So eventually it's
only the protection domain of the subject, which in turn is used for the authorization.
Running the examples
Make sure that jaas.config, policy.config and the jaas-example.jar file are in the same directory.
(There are also Ant targets named runCase1, runCase2, runcase3 and runCase4 that will execute these
test program with the specified parameters.) The complete, ready-to-run code can be
downloaded here.
The example does nothing fancier than changing the default encoding that is used for writing files.
The Java code for that is System.setProperty("file.encoding", "ASCII"), and you can find
it in the TestJaasAuthorization class. It's a simple example, but since this property
has an impact on a wide range of I/O actions, it's protection-worthy nonetheless.
The login module for all examples is written so that authentication is successful if the
username matches the password (a bit simplistic, but since the subject here is authorization
-and not secure authentication- it's quite sufficient) and a principal with the username
can be be created and attached to the already authenticated subject. Then the authorization
is performed. You can run the example by invoking ant runCase1 which executes the
following command:
In this case the authentication would succeed and principal RanchPrincipal would be attached
to the authenticated subject.Through the policy file we have granted RanchPrincipal with the
required permission only to user "rahul". The code runs properly to the end and will successfully
change the value of the file.encoding property to ASCII regardless of the current value.
While user bob is successfully authenticated (username and password are identical),
we're still using the policy config file that gives the critical permission to user "rahul" only.
So in this case the authentication would succeed, but the authorization would fail and the
subject will not be able to invoke the operation.
The third case fixes that. Again, the authentication succeeds, and the principal RanchPrincipal
is with parameter "bob" is created and attached to the authenticated subject. Since we're now
using a different policy config file (which gives the permission to all authenticated users
– that's what the "*" after RanchPrincipal means), the code proceeds smoothly.
The fourth case demonstrates authentication failure. In this case the subject will not be
populated with any Principal. In fact, a null subject would be returned from the LoginContext.
And since only authenticated users are allowed to run the code, the execution is denied.
This is just to make sure that authentication still works (without which proper handling
of authorization wouldn't be worth much):
Have you ever wondered how some websites are able to determine where you visited from? It all begins with the IP address that you belong to when you connect to the internet. Every time you log onto the internet your ISP assigns an IP address to you. This IP address belongs to a specific range that is allotted to regions around the world.
So how do you find out which IP address belongs to a particular location? There are a couple of ways to do this. Solutions include commercial web services as well as free databases which you can download, import and use.
A number of commercial offerings are available, but I am not in favor of any solution that involves calling a web service or requesting for the data through some other means remotely. This adds an additional latency to the call, and it also means that your service depends on the service of your vendor and for some websites a downtime of such a service is simply not acceptable. On the positive side, you don't have to worry about how you maintain the data if you are making remote calls to get the location data. There are also commercial solutions that offer the entire database to you for a fee. You can then import this data to your favorite database and make calls as necessary. In this article I will
concentrate on a free solution instead.
A free solution
It involves downloading a CSV (comma separated value) file, and then
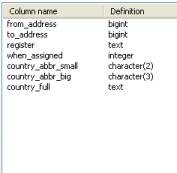
loading this data into a persistent store, say a database. This is comparable to commercial products that offer the same. The free CSV is updated on a daily basis, which is good news. Depending on the accuracy of the data that you need, you will have to refresh the data in your tables daily, weekly or monthly. How much data will be added depends on how many organizations/people register new IP addresses. Lets have a look at the format of this CSV file (the download link is available in the references section)
CSV File format
From
To
Registered with
When
Country (2)
Country (3)
Country (full)
50331648
67108863
ARIN
57257
US
USA
UNITED STATES
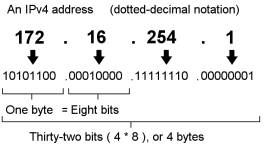
From and To: Hmm? Now what's with these From and To values? An IP address can be converted to a single number. With the IPV4 addressing system, the maximum value of any given value x in x.y.z.a is 255. Let's say we have an IP address 1.2.3.4. To convert this to a number we do the following
The IPV4 system is a 32 bit representation of an IP address. Here is an example illustration of an IP address and its associated bits:
This is what the numbers in the From and To columns represent.
Registered with: The registry that the IP range is associated with. Here are some examples –
APCNIC, ARIN, LACNIC, RIPENCC and AFRINIC, IANA
When: Date when this range was assigned in milliseconds.
Country: Two letter and three letter abbreviations as well as the full country name.
Now lets import this data into a database, e.g. PostgreSQL. You can do this with the following command
copy ip_location from 'd:/temp/IpToCountry_withoutID.csv' WITH CSV
This command says to copy the data in the CSV file to the ip_location table (which we have already defined, the structure is available in the reference section).
Note that copy is not a SQL standard command – it is specific to PostgreSQL. (Other databases have similar ETL tools available; check the documentation of the one you're using.) Once we have the data, we can write a small program to return the location result, given a IP address. Lets have a look at a code snippet. Here is a utility function to get a location given an IP address.
public void findLocation (String[] args) {
BigInteger base = new BigInteger("256");
if (args.length > 0 && args[0] != null && !args[0].equals("")) {
String ip = args[0];
String[] numberTokens = ip.split("\\.");
int power = 3;
BigInteger bigResult = new BigInteger("0");
for (String number : numberTokens) {
BigInteger bigNumber = new BigInteger(number);
BigInteger raise = raiseToPow(base, power--);
bigNumber = bigNumber.multiply(raise);
bigResult = bigResult.add(bigNumber);
}
System.out.println("Calculated result for " + ip + " is " + bigResult);
printLocationData(bigResult);
} else {
System.out.println("USAGE: java LocationFinder x.y.z.a");
}
}
The method printLocationData() connects to the database and fetches the right values to display. The method raiseToPow() is a utility method that simply raises a number to a given power and returns the result. The code splits the IP address into string tokens containing the numbers that we are interested in. It then generates a result which is looked up in the database using the following query:
select * from ip_location where ? > from_address and ? < to_address
The "?" is parameterized with the IP address number that we calculated. If the number falls within a particular range, we have what we want. Here is a sample output that the program threw for a given IP address
Calculated result for 66.92.21.32 is 1113330976
Registered with: ARIN
Country: UNITED STATES
So there you have it – free IP to location conversion at your service.
There is plenty of content around that discuss the performance of the relative Java Collections classes,
mostly in terms of adding and retrieving items and some of the specifics under the cover such as the effect of the
initial capacity. HashMaps and HashSets are special cases that make heavy use of the Object.hashCode()
contract and as such are particularly sensitive to the behaviour of that method.
This article was inspired by a couple of classes in the application I support at work. It has a couple of very large
HashMaps, one containing several thousand properties and settings, and the other containing tens of thousands of translations.
Since they are so pervasive their performance has a direct impact on the application, and since they are so large it was worth
taking the time to see how they performed. From this I took a tangent to specifics affecting HashMap performance and the article below.
Firstly a recommendation: If you haven't read Joshua Bloch's Effective Java, you should.
Much of the information below follows on from concepts in his book, but there is no replacement for the wealth contained in the book.
While looking at HashMaps, we will of course look at the effects on loading and retrieving data, but we'll
also address the time to iterate the contents and combine the effects of the initial capacity at the same time. Having read the API,
you are of course aware that the HashSet class is backed by a HashMap, which is why we cover one and not the other.
HashMaps With String Keys
Our HashMaps are keyed against either a String or Integer value, so I thought I would start with Strings.
Loading the Strings
I created three lists of random Strings containing 1,000 10,000 and 100,000 items. The Strings were from 5 to 10 characters long and all upper case.
The Strings values were loaded into an Array and the time taken to load them from the Array into the HashMap was measured for a variety of initial capacities and timed using something like this...
These results are non-threatening and may even be a little faster than expected. It is certainly the case that you wouldn't think twice
about putting 100,000 records in a HashMap if you knew it was going to take a tenth of a second to load.
Retrieving the Strings
Now that we have the data loaded, it isn't much good unless we can get it back out. Since HashMaps are renouned for their ability to return data quickly, we will start with that.
Note that to make sure the time spent selecting an item doesn't affect our results, we will pick the first item from our initial list and load it repeatedly like this...
String searchKey = array[0]; long start = System.nanoTime(); for (int i = 0; i < LOOP_SIZE; i++) {
map.get(searchKey);
}
System.out.println("Took " + (System.nanoTime() - start) / 1000000
+ " ms");
Key Size
Initial Capacity
Reads
Read time (ms)
1000
10
100 million
~2400
1000
100
100 million
~2400
1000
1000
100 million
~2400
1000
10,000
100 million
~2400
1000
100,000
100 million
~2400
1000
1,000,000
100 million
~2400
10,000
10
100 million
~2400
10,000
100
100 million
~2400
10,000
1000
100 million
~2400
10,000
10,000
100 million
~2400
10,000
100,000
100 million
~2400
10,000
1,000,000
100 million
~2400
100,000
10
100 million
~2400
100,000
100
100 million
~2400
100,000
1000
100 million
~2400
100,000
10,000
100 million
~2400
100,000
100,000
100 million
~2400
100,000
1,000,000
100 million
~2400
Table 2 - String key read times
Once again I hope these results are non-threatening and pretty much as expected. Regardless of the size of the HashMap and the number of items it
contains, the time taken to retrieve an item does not change.
Note that 100 million reads is a fair amount of work for our HashMap to do, and is almost one operation for every millisecond in the day.
Iterating the Strings
The final piece of work to build our basic results is to test the amount of time taken to iterate the results.
To get values that are visible, we iterate each set of keys depending on the number of items it contains, like this...
long start = System.nanoTime(); for (int i = 0; i < ITERATE_COUNT; i++) { for (String string : map.keySet()) {
// This operation should be 'free', and the compiler
// should not be able to compile it out of the byte code.
string.hashCode();
}
}
System.out.println("Took " + (System.nanoTime() - start) / 1000000
+ " ms");
Key Size
Initial Capacity
Iterations
Iteration Time (ms)
1000
10
10,000 (x 1000)
~510
1000
100
10,000 (x 1000)
~510
1000
1000
10,000 (x 1000)
~550
1000
10,000
10,000 (x 1000)
1,100
1000
100,000
10,000 (x 1000)
6,200
1000
1,000,000
10,000 (x 1000)
50,000
10,000
10
1,000 (x 10,000)
~520
10,000
100
1,000 (x 10,000)
~520
10,000
1000
1,000 (x 10,000)
~520
10,000
10,000
1,000 (x 10,000)
~550
10,000
100,000
1,000 (x 10,000)
1,200
10,000
1,000,000
1,000 (x 10,000)
100,000
10
100 (x 100,000)
1800
100,000
100
100 (x 100,000)
1800
100,000
1000
100 (x 100,000)
1800
100,000
10,000
100 (x 100,000)
1800
100,000
100,000
100 (x 100,000)
1800
100,000
1,000,000
100 (x 100,000)
Table 3 - String key iteration times
Summarising Strings as Keys
Now that we have our baseline results using String as our keys, we can summarise:
It is very fast to load String keys into a HashMap
While the javadoc warns against making the initial capacity too small due to rehashing costs, this wasn't apparent in the results above.
The 'read time' appears constant regardless of the number of items in the map or the current capacity. This is described in the HashMap API.
The iteration time appears fairly constant unless the capacity is very large. This is described in the HashMap API too.
To be fair, the String class is a first class citizen in Java, and is able to make use of skilled design and specific treatment by the compiler.
The largest help is that the String classes hashCode() method is lazy loaded and therefore cached.
This was used in the iteration example since the hash code value had already been calculated and can therefore be reused without being recalculated,
but it is also critical to the results we have seen so far, as we are about to discover.
HashMaps With Exotic Keys
While Strings and Integers are common choices as keys, it is often necessary to use classes that are more complicated, and the complicated nature of
the class could relate directly to the behaviour of the HashMap utilising the class. Without trying to go overboard creating a class that incurs a
cost while calculating its hash code, we will create a class that contains an array of primitive ints and provides a hash code based on the array contents.
The LargeHash Class
// This class is only designed to illustrate the cost of hashing.
// It is not for production use! public class LargeHash {
private final int[] intValues;
public LargeHash (final int intValue) {
intValues = new int[1000]; for (int i = 0; i < intValues.length; i++) {
intValues[i] = intValue + i;
}
}
@Override public int hashCode() { final int prime = 31; int result = 17;
result = prime * result + Arrays.hashCode(intValues); return result;
}
@Override public boolean equals (Object obj) { if (this == obj ) return true; if (obj == null) return false; if (getClass() != obj.getClass()) return false; final LargeHash other = (LargeHash) obj; if (!Arrays.equals(intValues, other.intValues)) return false; return true;
}
}
The class is designed to be a HashMap key, and once an instance is created it has only limited functionality.
The hashCode() and equals() methods were initially generated by Eclipse, and use methods from the Arrays helper class.
We will be performing the same operations of loading, reading and iterating a HashMap containing a large number of instances as keys, and the results are...
Key Size
Initial Capacity
Load Time (ms)
Reads
Read Time (ms)
Iterations
Iteration Time (ms)
1000
10
5
100 million
275,000 *
10,000 (x 1000)
500
1000
100
5
100 million
280,000 *
10,000 (x 1000)
500
1000
1000
4
100 million
275,000 *
10,000 (x 1000)
500
1000
10,000
5
100 million
280,000 *
10,000 (x 1000)
1100
1000
100,000
5
100 million
275,000 *
10,000 (x 1000)
6200 **
1000
1,000,000
4
100 million
275,000 *
10,000 (x 1000)
50,000 **
10,000
10
40
100 million
280,000 *
1000 (x 10,000)
500
10,000
100
40
100 million
280,000 *
1000 (x 10,000)
500
10,000
1000
40
100 million
280,000 *
1000 (x 10,000)
520
10,000
10,000
42
100 million
290,000 *
1000 (x 10,000)
520
10,000
100,000
43
100 million
290,000 *
1000 (x 10,000)
1100 **
10,000
1,000,000
42
100 million
280,000 *
1000 (x 10,000)
5800 **
100,000
10
350
100 million
280,000 *
100 (x 100,000)
2100
100,000
100
350
100 million
280,000 *
100 (x 100,000)
2100
100,000
1000
350
100 million
280,000 *
100 (x 100,000)
2100
100,000
10,000
350
100 million
280,000 *
100 (x 100,000)
2100
100,000
100,000
330
100 million
280,000 *
100 (x 100,000)
2000 **
100,000
1,000,000
330
100 million
280,000 *
100 (x 100,000)
2400 **
* values are interpreted from repeated runs of 1 million reads ** See the afterthoughts...
Table 4 - Simple LargeHash times
The LargeHash Behaviour
Firstly, the load time was larger but still not really noticeable. It took possibly twice as long, but twice 'not a hell of a lot' is still 'not much'.
Interestingly, the API recommends setting the initial size to some realistic value to prevent incurring the cost of rehashing, but that cost doesn't appear in the results.
It is possible that the initial capacity made a difference when we use 100,000 items in our Map, but not enough to provide any conclusive results.
The read time was obviously worse, to the extent that I decided to extrapolate the results rather than wait several minutes for each run to complete.
This shows us that the hashCode() method is too important when used in HashMaps to be taken lightly, and consideration should be taken when choosing or designing a class that will be used as a hashed key.
There is nothing incredibly wrong with the class itself, but when put under pressure it fails to perform and can cause a drag on the code.
Building a Responsible Key
The lesson to learn from the String class is that lazy loading and caching the hash value can have a dramatic effect on the read times, since this is crucial to the HashMap performance.
This is particularly true when you have high high usage HashMaps like the ones in the introduction.
Is important to not that the hash code cannot be cached if the instance state can change in a way that alters the hash code, which implies that the key should first be made immutable before the hash code can be lazy loaded.
The LargeHash class is almost immutable, since it doesn't require defensive copies of data coming in and no data is exposed. This means we are only required to make the class final to fulfil the immutable contract.
There a few options for lazy loading and caching the hash code, but we will copy the approach used in the String class.
Since no synchronization is used it could lead to a race condition in which the hash code is set to different values, but immutable internal state protects us from this happening in this case.
It is still possible for the hash code to be generated by more than thread, but once the value is set then it will be defined forever and we no longer worry about the value changing and do not suffer the cost of synchronization that is no longer required.
It is also important to note that the local variable 'h' is used throughout the method to ensure thread safety. Otherwise another thread could see the hash variable in an intermediate (non zero) state and return the incorrect value.
The updated method looks like this...
@Override
// Style copied from String.hashCode() public int hashCode() { int h = hash; if (h == 0) { final int prime = 31;
h = 17;
h = prime * h + Arrays.hashCode(intValues);
hash = h;
} return h;
}
...and now has performance comparable to the String key while being all the more exotic in nature.
Key Size
Initial Capacity
Load Time (ms)
Reads
Read Time (ms)
Iterations
Iteration Time (ms)
1000
10
5
100 million
2400
10,000 (x 1000)
500
1000
100
5
100 million
2400
10,000 (x 1000)
500
1000
1000
5
100 million
2400
10,000 (x 1000)
500
1000
10,000
4
100 million
2400
10,000 (x 1000)
1100
1000
100,000
5
100 million
2400
10,000 (x 1000)
6200 **
1000
1,000,000
5
100 million
2400
10,000 (x 1000)
50,000 **
10,000
10
40
100 million
2400
1000 (x 10,000)
500
10,000
100
40
100 million
2400
1000 (x 10,000)
500
10,000
1000
42
100 million
2400
1000 (x 10,000)
500
10,000
10,000
40
100 million
2400
1000 (x 10,000)
500
10,000
100,000
40
100 million
2400
1000 (x 10,000)
1000 **
10,000
1,000,000
40
100 million
2400
1000 (x 10,000)
5800 **
100,000
10
350
100 million
2400
100 (x 100,000)
2000
100,000
100
350
100 million
2400
100 (x 100,000)
2000
100,000
1000
440 *
100 million
2400
100 (x 100,000)
1800 *
100,000
10,000
350
100 million
2400
100 (x 100,000)
2000
100,000
100,000
350
100 million
2400
100 (x 100,000)
2000 **
100,000
1,000,000
350
100 million
2400
100 (x 100,000)
2400 **
* These values were a repeatable aberration ** See the afterthoughts...
Table 5 - Optimised LargeHash times
In Conclusion
The hasCode() method matters. In fact I would extend that to state that all aspects of all contract methods matter.
Joshua Bloch has plenty to say about the hashCode(), equals() and comparable() contracts,
but when you consider that these methods are the backbone of large parts of the Java programming language, it may not be sufficient just to get the right.
In critical places, the default hashing algorithm may not be enough.
While the API warns that making the initial size too small can incur an overhead due to rehashing when the capacity increases, this was not apparent in the tables above.
The cost to iteration due to large capacities is easier to see. Therefore the data suggests that HashMaps should be initialised to a smaller size and definitely not overly large.
Afterthoughts
Unusual Iteration Times
Tables 4 and 5 show that the iteration time increases as the capacity increases, and we expected this result.
What was unexpected were times that decreased when the Maps contained more entries.
I don't have much more to say about this than "gosh".
Actual Size
An interesting diversion is to look at the actual capacity of the HashMap.
The internal size is always kept as a power of two, presumably for performance purposes, but it is also important to note that the 'power of two' property is
enforced under the covers and certainly not exposed via the API. Therefore as a rule you should ignore it in your own code. One thing this means is that you
shouldn't try to initialise HashMaps to an appropriate 'power of two' value as it is already done for you, but in doing so you may be actively harming yourself
if the particulars are changed in later implementations.
The actual capacity is the smallest power of two that is greater than the initial capacity and greater than the number of items divided by the load factor.
This second point is the reason that an initial capacity of 1000 would set the actual capacity to 1024 (is 2^10) but once this was 75% full (load factor 0.75)
the capacity would be altered to 2048 (ie 2^11) as seen in Table 6.
While the actual capacity is not exposed directly, there are many ways to inspect the value and I found it easiest to attach a debugger to interrogate the HashMap instance.
Key Size
Initial Capacity
Actual Capacity
1000
10
2^11
1000
100
2^11
1000
1000
2^11
1000
10,000
2^14
1000
100,000
2^17
1000
1,000,000
2^20
10,000
10
2^14
10,000
100
2^14
10,000
1000
2^14
10,000
10,000
2^14
10,000
100,000
2^17
10,000
1,000,000
2^20
100,000
10
2^17
100,000
100
2^17
100,000
1000
2^17
100,000
10,000
2^17
100,000
100,000
2^17
100,000
1,000,000
2^20
Table 6 - Actual capacities in the previous tests
Iterating Map.Entry Sets
As a final aside, there are many articles that recommend iterating the Map.Entry set from HashMaps in preference to iterating the keys and then using the key to obtain the value.
We already have the time required to iterate in the data above, and have also shown that the time to retrieve the value is constant, but we already knew that from the API.
long start = System.nanoTime(); for (int i = 0; i < ITERATE_COUNT; i++) { for (Map.Entry<String,String> entry : map.entrySet()) {
entry.getKey().hashCode();
}
}
System.out.println("Took " + (System.nanoTime() - start) / 1000000
+ " ms");
While potentially faster, this code is less readable and would therefore need to be quite a bit faster to warrant adoption, so lets run the tests one last time...
Key Size
Initial Capacity
Iterations
Get then Read * (ms)
Map.Entry (ms)
1000
10,000
10,000 (x 1000)
1340
1330
1000
100,000
10,000 (x 1000)
6400
6400
1000
1,000,000
10,000 (x 1000)
50,000
50,000
10,000
10,000
1,000 (x 10,000)
740
700
10,000
100,000
1,000 (x 10,000)
1200
1200
10,000
1,000,000
1,000 (x 10,000)
6000
5900
100,000
10,000
100 (x 100,000)
2200
1900
100,000
100,000
100 (x 100,000)
2200
1500
100,000
1,000,000
100 (x 100,000)
2600
1900
* Times were calculated using the data from Tables 5
Table 7 - Map.Entry iteration times
The Map.Entry does show faster iteration times at the extreme end of the test data, but otherwise I'm not so convinced.
The first time I heard the word pagination, I thought "What's that?". Then I googled and
found out that it's a fancy word for splitting search results into bite size pages that the
user can snack into. Pagination depends on some factors. It might even depend on what type of
framework you use to deliver your solution. An off the shelf API that paginates on a web browser
might not work with a Swing application that wants to paginate results. Let's look at some of the
ways to paginate.
Using an off the shelf solution to paginate results
This method has its own pros and cons like the rest. To begin with it's quite easy to find an API
that's out there, and to use its functions to paginate your results. Often all you have to do is to
provide the API, details about the number of results, how many pages to display etc.
The API may even be configurable by the user if it is flexible enough. For example JavaWorld
featured an article quite a while back about using such an API. Given below is the code related
to the pagination tag (a custom tag)
Given the start position, range and total number of results we can let the API do its job and
paginate the results. This kind of solution requires the least work from the developer.
The code is ready made and available. All the developer needs to do is to know how to use
the API and things work by themselves. (DisplayTag is another such tag libray; see the reference
section below for a link.) Although such APIs may reduce development time they may
not be as flexible as we might want them to be. If a client requires changes to the way pagination
occurs in the application we may have to dive down to the guts of the API and find a solution
if it is not available. Worse still, if you don't have the source code to the library
you may be in trouble. The pagination tag is a custom tag that a developer can use to
paginate his/her results. Imagine if you need to change the code contents of the custom tag
because the client wants a change to the way we paginate. Any open solution must be used with caution.
Anything that is free and saves time is welcome as long as it does not complicate the solution
at a later stage in its life.
Writing your own pagination logic
There are 2 ways (mostly) through which you can fetch your data. One would be to fetch all the
results (hence the term greedy) and display it to a user after caching the results.
The other approach is to get a selection of the results each time a user requests the data
from the search query.
Fetching results the greedy way
I am a big fan of patterns. A particular pattern called the ValueListHandler is very useful
when dealing with paginating greedily. This pattern is reusable across several queries and can
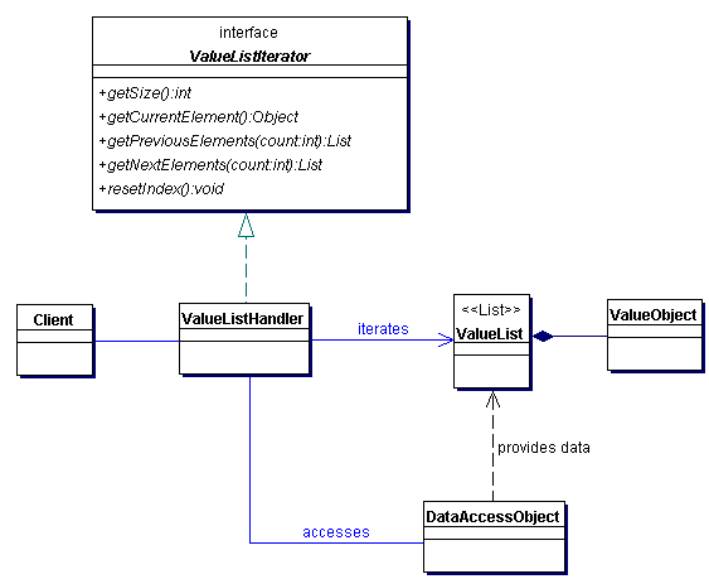
help your pagination process. A class diagram of the ValueListHandler pattern is illustrated below.
Class diagram: ValueListHandler
The idea is that a client uses a ValueListHandler, which accesses a DAO to return a ValueList.
Each value list can contain a couple of value objects (The DAO and VO patterns are mentioned
in the references section if you need to go through them). Every time the user needs results
to be displayed it can be handled gracefully by asking the ValueListHandler a sub list from
the ValueList. Since the ValueList caches the results there is not need to go the database
again to fetch the next set of results when the user clicks "Next". Here is a sequence
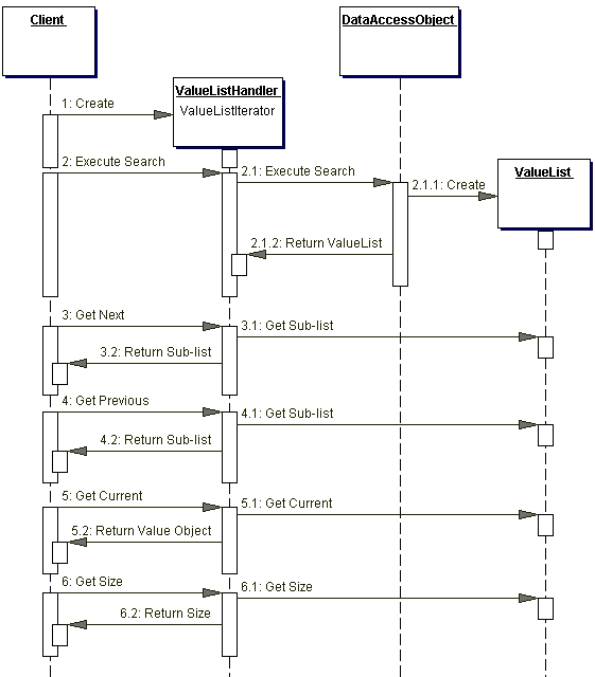
diagram to explain it better.
Sequence diagram: ValueListHandler
Every time the user needs the next (or previous) result set you can ask the ValueListHandler
for the next/previous sub list. If you allow the value list to store a list of Objects you can
use this solution to set any type of VO into the ValueList and apply this pattern across several
searches. You will of course have to cache the ValueListHandler in memory. You will also have to
down cast the list of objects from the ValueList to your VO type everytime you want to display
the data in the object.
Fetching results the not so greedy way
There is a little problem with the solution that was described above. What if your search result
returns 100,000 matches? Your user may have to wait for a long time and be a very unhappy camper indeed.
So it often makes sense to fetch only the number of records the user wants to see.
Different database have different methods to limit the query size. Oracle uses ROWNUM, and Sybase
uses LIMIT. The queries below give you an example of how you can restrict your result set.
Sybase: (Give me rows 0 to 10 of the result)
SELECT * FROM TABLE WHERE {CONDITION} LIMIT 0, 10
Oracle: (Give me the rows between min_row_to_fetch and max_row_to_fetch )
SELECT *
FROM ( SELECT /*+ FIRST_ROWS(n) */ a.*, ROWNUM rnum
FROM ( your_query_goes_here, with order by ) a
WHERE ROWNUM <= :MAX_ROW_TO_FETCH )
WHERE rnum >= :MIN_ROW_TO_FETCH;
Oracle's version of the query limitation is a little different because of the way it treats ROWNUM.
In order to make the SQL more database agnostic, you can paginate by requesting data by using
a sub set of the primary keys that you are interested in. For example if your data list contains
the primary keys {1,34,25,56,333,23,99,101} you can create a sub list {1,34,25,56} and fetch this list.
The next sub list would be {333,23,99,101}. Pagination is then possible with the following SQL:
SELECT * FROM TABLE WHERE PRIMARY_KEY IN (MY_SUB_LIST)
Another drawback with the greedy approach is that the data becomes stale once you cache it.
If your application changes the data in the result set frequently you may have to consider the
accuracy of your results when you choose a solution.
Which technique should I use?
Whichever solution fits your requirements. The solution may not even be one of the 3 listed here.
These are 3 common approaches to paginating and usually fit the bill based on the user's
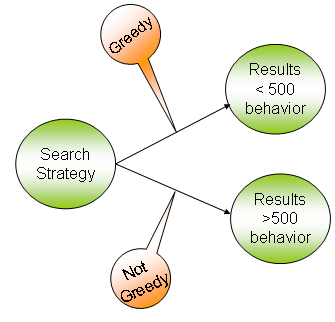
response time requirements. My personal favorite is to add a Strategy pattern on top of this.
If the number of results is less than 500 (say) I use the greedy technique to display the results.
If it is more than 500 I use the non-greedy technique to display the results since the user may
have to wait for a long time. Be sure to consider the drawbacks carefully in each case.
At the risk of dumbing down the Strategy pattern, an illustration for this scenario is given below.
Practically one would switch between various implementations of an interface to achieve this.
Check the reference section below for more information on this. I would recommend the
Head First Design Pattern book or the Gang Of Four design pattern book.
Strategy based on result set size
Conclusion
Each scenario would solve the problem given a certain boundary. You should choose wisely
based on what solution best suits you. In the end it does not matter how we solve the problem
as long as the client's requirements are met and the design of the solution is flexible to
accommodate future changes.
Not all the good stuff is in these Journal articles. The Saloon sees lots of insight and wisdom
all the time, and the staff is continuously reviewing interesting books and blogging about
this, that and the other. Plus, we've got book authors hanging out with us all the time.
So here are a few nuggets you may have missed that should prove interesting to many folks.
Big Moose Saloon
Recognizing that Java isn't the be-all and end-all of languages, and that JVM-based languages are all
the rage nowadays, we've started new forums for Groovy
and Scala.
So head over there with all your questions, and be sure to let your programming buddies know about them.
A rancher wonders when is the right time to commit source code to the repository in
Macro vs Micro commits:
(just about) every time a change is made, or only after major chunks of work have been completed and tested?
A discussion on the various possibilities of generating Swing GUIs ensues in
Designing GUIs.
While the original question concerns using a GUI builder tool like Matisse vs. coding GUIs by hand,
ranchers' opinions also cover building GUIs from XML descriptions, and point to various libraries that may help.
Using JAAS and Single-Sign-On (SSO) are frequently-discussed topics on the ranch. Now a member asks about
a portable JAAS solution for multiple web apps, for which SSO will also be needed. Various options and
approaches are discussed in Understanding JAAS/Web app SSO.
For years the Word Association
thread has been the longest (and longest-running) topic on JavaRanch. Now there's a newcomer with an interesting twist:
Picture Association.
Thanks to fellow rancher Robert Liguori for starting this one – it's an intriguing concept.
Book Reviews
To make it easier to find books we have reviewed, there's now a Book Search.
It allows you to search the library of reviews by title, author, publisher, ISBN, reviewer, review contents
and category. The search criteria can also be combined, and the results bookmarked.
The Code Barn is one of the oldest sections of the ranch,
and maybe one of the lesser-known ones. It collects fully-functioning code snippets that demonstrate how various
Java features (or 3rd party libraries) work. It has been moved to the wiki a while ago -so it is editable by anyone
who's logged into the Saloon-, and we welcome comments and contributions. So if you have a piece you wrote for
a particular purpose, and you think it might help others, let us know about it (or add it yourself, if you feel
strong with the wiki force). Currently, there are sections for applets, servlets/JSP, XML, 3rd party libraries,
and various uncategorized items in beginner, intermediate and advanced coding levels, but we can certainly add
new categories if there's interest and code to start with.
Upcoming Promotions
On August 5, Dan Allen will be answering questions about
Seam in Action
On August 12, Jevgeni Kabanov & Toomas Römer introduce
Java Rebel