What It Means to Mock: Isolating Units for Testing
by Carrie Prebble
I'd like for more of my colleagues to write unit tests. My motives are selfish. Unit tests help me figure out how methods of the unit are supposed to work. Unit tests are documentation too. And if a unit is testable, that makes it pretty good code.
I believe one reason that some of my fellows don't write unit tests is because they're not quite sure how the mock object thing fits in. I'll explain.
Mock objects are for writing unit tests.
Not integration tests, not system tests. But fast, code-covering, automated unit tests. You have to isolate the unit from other objects to make a unit test.
Mocks help us isolate units.
Isolating a unit from other objects means that the test will fail only if the unit fails, not because the network is down or because there's some bug in a library. Besides, how would you know if it's a bug in a library or a bug in the unit? I mean how would you prove it?
Isolating a unit during a test means the test controls the unit. The test controls inputs and helper objects. If my unit creates a new helper GregorianCalendar then it can't test December dates when it's not December. But if the test creates the calendar and passes it to the unit ... (See bonus section.)
If I use mock objects, then I don't have to setup a database with test data. If I use mock objects, then I don't have to setup Tomcat or some other container just to run tests on my unit.
Mock objects, and isolation, help me be a lazier test writer.
Test vs Production
To test a unit, we take it out of the production environment and put it in a test environment. The unit won't know the difference since it will be talking to mock objects that look just like the real implementations.
Production, test; same unit, different environment.
The unit in this picture has two helpers: a dao and a userService. Mock objects impersonate them in the test.
Mock objects are look-alikes. A mock implements the same interface as the real helper object. It has the same method signatures but instead of implementation, a mock has the ability to take notes during a test and report back. Mocks are the henchmen of tests.
A stub differs from a mock object in that a stub object doesn't know how to tell the test about what happened during the test. Stubs don't collude. Not even in a good, testing kind of way.
Units and Tests and Mocks. Where do I start?
Let's back up a little. We want the unit to behave exactly the same in tests as in production. And it's important to have our unit do only what it has been created to do. "I wrote my unit to fetch reports for managers based on a set of given categories." We'll meet this unit soon.
If it needs help with something, like accessing data (which is some other object's specialty), then have the unit expect that helper to already be instantiated and ready to help. The unit calls the helper by calling a getter for the helper, and then the helper's method: getDao().getReport(cat). Some other object creates and destroys and hands out instances of objects that the unit needs. The unit is like the surgeon. Others hand her the tools, she just focuses on the work.
Let some other object do life-cycle management.
Make the unit mock-ready or helper-ready, expecting helper objects to already be there:
unit declares members as their interfaces
private IDao dao;
instead of
private DaoImpl dao;
which means Static objects and Singletons are not mock-able since they are not declared and can't be set to a different implementation
the unit, when it's ready to work, should expect the dao variable to already have a value. The unit uses it by calling its getter: getDao();
The life-cycle manager, which could be a framework or a test, must be able to give your unit a different implementation of the real helper by calling a setter: setDao();
The next three pictures show a mock-ready unit, a test that sets mock helpers and a main method that sets production helpers.
A mock-ready unit:
Test environment sets mock helpers:
Production environment sets production helpers:
The unit is the same whether it's in production or in test. The test injects mock objects in place of the helpers. The main method, the production environment, injects real implementations for the helpers.
Yeah-but Questions
Q: Is this dependency injection?
A: Yes. The unit's dependencies are set, or injected, by somebody outside the unit, a test or a framework.
Q: So I should never use "new" in my unit?
A: You probably don't need to mock a String object, so the unit could create new Strings. Or a new ArrayList. It's the helper objects that the unit shouldn't be creating.
Q: Who sets the real helpers, userService and dao, in production?
A: A container, like Spring Framework or JBoss, a main method or another object that does setup can inject real objects. Spring Framework can inject the unit's dependencies if the unit is mock-ready. The following snippet could be the unit declared in a Spring Framework configuration file. Spring injects the production implementations of the helper objects.
Q: What do you mean Static and Singleton objects keep a unit from being mock-ready?
A: If a unit makes a call that looks like: StaticUtil.methodZ(), there isn't a way to substitute a mock StaticUtil in for the real thing. There isn't a setter in the unit for a test to set it to a different implementation.
Q: Why is it such a big deal to not use a static object in the test?
A:It's important to focus on testing just the unit. If we don't isolate our unit we don't really know who we're talking to during a test. Do the static methods call other static objects? What if there's a bug somewhere in the static method or those other objects? We want to test our unit, not those other objects.
To unit test a unit that has a static object, you have to change how the unit uses it. Make an interface and a wrapper implementation for the Static object and add getters and setters to the unit. The unit uses this new interface and object instead of the static object.
public IStaticUtil getUtil() { return this.util; }
public void setUtil(IStaticUtil util) { this.util = util; }
unit uses util object:
String rtnval = getUtil().methodZ();
test can substitute a different util object:
unit.setUtil((IStaticUtil)mockUtil.proxy());
Q: But static is good, isn't it, since it saves expensive object instantiation?
A: A static helper object comes at the cost of not being able to isolate and unit-test a unit that uses it. You can get the benefits of static-ness and singleton-ness other ways. The Spring Framework provides a singleton-like behavior for its beans, unless directed otherwise.
Let some other object do life-cycle management. Encapsulate that elsewhere. A unit should focus on its work, its reason for being, not on creating its helper objects. Removing object instantiation responsibilities makes the unit more cohesive. A cohesive unit means it's single-minded, it's focused on doing only one thing, which is a worthwhile development principle.
Bullet Points
it's important to isolate a unit for a unit test
isolation means not letting the unit have any conversations with objects not under the control of the test
mock objects help isolate a unit for testing
a test isolates a unit by substituting mock objects in place of the unit's real helper objects
a mock helper object implements the same interface as the real helper, has no real implementation yet can "report back" to the test about what happened during the test
the test does all the setup for the unit
a unit that is mock-ready is easier to unit test
a mock-ready unit's helpers are declared by their interface and set by somebody else
a mock-ready unit calls methods on its helpers by first calling the getter and then the method
removing responsibility for creating its own helper objects from a unit makes it more testable and more cohesive
So now how do I do this? How do I make mocks and how do I apply this to classes I already have?
Take a look at the method you want to test. What does it do? Does it call methods on any helper objects (besides java.lang objects like String and List)? Does it make "new" helpers? Make your unit mock-ready.
Have the unit declare the helper as a class level member and declare it by its interface. If the helper doesn't have an interface then change that if you can; otherwise make an interface and an implementation that forwards calls to the helper.
Make getters and setters for the helper member
Remove any lines that create new helper objects
Change any lines that call helper methods to something like:
getHelper().helperMethod();
We'll use JUnit to help us make tests. And there are tools out there that can help us make mock objects. JMock is one of them.
The tricky thing about a unit test
... is that we're testing only what the unit does. If a unit calls a method on a helper object, that's what we test. That the unit has made that call. We don't care how the helper does its work. We might care about inputs and outputs of the helper. Those are things our unit might work on.
In the getUserReports method in the above unit, the unit makes a call to the userService. We tell that helper mock to expect a particular method call. The mock will tell us if the unit made that call or not. It will also tell us if the arguments and return value were expected.
How do I use JMock?
(Note: these examples are in version 1.2 of JMock)
Import the libraries:
import org.jmock.Mock;
import org.jmock.cglib.MockObjectTestCase; the test class extends this class
Make the Mock:
Mock mockUserService = mock(IUserService.class);
Tell the mock what to expect during the test: "for this test the unit will make a call to 'getCurrentUser' on the UserService object and it will return a User object":
The mock will tell you anyway but you could ask it if the unit met the expectations:
mock.verify();
See the unit test above, and visit jmock.com for more information about JMock
Write More Unit Tests with Mock Objects
By using mock objects, we can isolate and test (and document) the work done by our unit. By using mocks, we don't have to setup databases or containers to test our units. Mock objects can help us be lazy writing our tests, which means we'll write more of them, right?
BONUS: inject a calendar in a unit to test December in January:
unit declares calendar:
private Calendar calendar = null;
make setter:
public void setCalendar(Calendar thisday) {
this.calendar = thisday;
}
make getter (use the calendar if it has been set, else make a new one):
public Calendar getCalendar() {
if (this.calendar != null ) {
return (Calendar)this.calendar.clone();
} else {
return new GregorianCalendar();
}
}
unit uses calendar by calling getter:
Calendar startDate = getCalendar();
Calendar endDate = getCalendar();
test makes December date and sets unit's calendar:
Calendar testdate = new GregorianCalendar();
testdate.set(2007, 11, 31); // 12-31-2007
unit.setCalendar(testdate);
call the method under test and assert things about any return values:
Date rtnSaturdayDate = unit.methodWithDate();
assertEquals(<the following Saturday>, rtnSaturdayDate);
Advices, pointcuts. Obscure words making me wonder what Aspect-Oriented Programming (AOP) is all about. In fact, behind these words lie very simple principles. Once the AOP vocabulary has been tackled, using AOP is a matter of practice. Spring offers different techniques to use AOP, but I think that the variety of choice makes AOP even more confusing. Let's clear this up, and see how AOP can be used in Spring.
Two AOP implementations can be chosen, as well as two coding styles for each. Confusing, isn't it ?
Spring AOP. It is not aimed to provide a full AOP implementation but it will be more than enough in most cases.
using the @AspectJ annotation style
using the XML configuration style
AspectJ. If Spring AOP is not enough, AspectJ, a Java implementation of AOP, can be easily plugged in.
using the AspectJ language syntax
using the @AspectJ annotation style
Annotations can be used with Java5+. I recommend to go through Spring's reference documentation to decide which one to choose. It will mainly depend on requirements and taste. I think that understanding Spring AOP is a priority before thinking of using AspectJ. In this tutorial, we will use Spring AOP only, using both the @AspectJ and XML styles.
Part 1: Introduction to Spring AOP and proxies
Part 2: Spring AOP using @AspectJ Annotation
Part 3: Spring AOP using the XML schema
Part 4: Spring AOP and transactions
It is assumed that you are already comfortable with Spring's dependency injection. If not, you can read this tutorial first. Basic database knowledge will help too.
AOP, what's the big deal ?
AOP is here to help programmers to separate of crosscutting concerns. What's that ? Imagine ordering an item at an online shop. When the item is ordered, several database tables may be updated. If a problem occurs during the ordering process, everything sent to the database should be cancelled (rollback). If the ordering process successfully ends, the ordering should be committed to the databases.
[Before]
public class OrderServiceImpl implements OrderService {
public void orderItem(Item item, int quantity) {
// Insert item into ORDER table
...
// Update ITEM table, decrement the number of remaining items
...
}
...
}
public class OrderItem {
public void orderItem(Item item, int quantity) {
OrderService orderService = ServiceManager.getOrderService();
orderService.orderItem(item, quantity);
}
}
[After]
public class OrderServiceImpl implements OrderService {
public void orderItem(Item item, int quantity) {
// Start transaction
...
// Insert item into ORDER table
...
// Update ITEM table, decrement the number of remaining items
...
// Commit changes
...
}
}
public class OrderItem {
public void orderItem(Item item, int quantity) {
try {
OrderService orderService = ServiceManager.getOrderService();
orderService.orderItem(item, quantity);
} catch( DbException e ) {
// log exception
...
// Rollback transaction
...
}
}
}
All this changes to make one transaction ! And that's just the orderItem() method. All methods that need transactions will look like this. The OrderServiceImpl's primary objective is only to fetch, insert, update or delete users. It doesn't care about transactions after all. If transactions could magically start when needed, without the OrderServiceImpl knowing it. Wouldn't it be great if transactions could be implemented without touching the original object ? That is where AOP comes to the rescue. A transaction is a crosscutting concern. It may be applied anywhere on top of existing code. Spring not only supports AOP, but also offers a very useful transaction management system. But before diving into AOP, let's first see an important concept in Spring AOP: proxies.
Proxy
A proxy is a well-used design pattern. To put it simply, a proxy is an object that looks like another object, but adds special functionality behind the scene. In Spring, any interface can be proxied. Let's see a simple example to illustrate what a proxy really is.
The Saloon interface:
package com.javaranch.journal.spring.aop;
public interface Saloon {
void openSaloon();
}
A simple implementation of the Saloon, the MooseSaloon :
package com.javaranch.journal.spring.aop;
public class MooseSaloon implements Saloon {
/** Welcome message */
private String greeting;
public void setGreeting(String greeting) {
this.greeting = greeting;
}
public void openSaloon() {
System.out.println("Saloon open [" + getClass() + "/" + toString() + "]");
System.out.println(greeting);
}
}
The MooseSaloon declared as a simple bean, and a proxy to the MooseSaloon:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-2.5.xsd">
<bean id="mooseSaloon" class="com.javaranch.journal.spring.aop.MooseSaloon">
<property name="greeting"><value>Welcome to the Big Moose Saloon !!</value></property>
</bean>
<bean id="proxySaloon"
class="org.springframework.aop.framework.ProxyFactoryBean">
<property name="proxyInterfaces"><value>com.javaranch.journal.spring.aop.Saloon</value></property>
<property name="target"><ref local="mooseSaloon"/></property>
</bean>
</beans>
The Main class using both the MooseSaloon and its proxy:
package com.javaranch.journal.spring.aop;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class Main {
public static void main(String[] args) {
ApplicationContext ctx = new ClassPathXmlApplicationContext("aop.xml");
// The mooseSaloon pojo
Saloon mooseSaloon = (Saloon)ctx.getBean("mooseSaloon");
mooseSaloon.openSaloon();
System.out.println("mooseSaloon [" + mooseSaloon.getClass() + "]");
System.out.println("--------");
// The mooseSaloon proxy
Saloon proxySaloon = (Saloon)ctx.getBean("proxySaloon");
proxySaloon.openSaloon();
System.out.println("proxySaloon [" + proxySaloon.getClass() + "]");
}
}
Running this application will produce something similar to the following output :
Saloon open [class com.javaranch.journal.spring.aop.MooseSaloon/
com.javaranch.journal.spring.aop.MooseSaloon@bfea1d]
Welcome to the Big Moose Saloon !!
mooseSaloon [class com.javaranch.journal.spring.aop.MooseSaloon]
--------
Saloon open [class com.javaranch.journal.spring.aop.MooseSaloon/
com.javaranch.journal.spring.aop.MooseSaloon@bfea1d]
Welcome to the Big Moose Saloon !!
proxySaloon [class $Proxy0]
You can notice that both the MooseSaloon and its proxy do the same thing. However, both mooseSaloon and proxySaloon are different classes. The proxy holds a reference to the mooseSaloon and implements the same interface, thus it holds the same methods implemented by MooseSaloon. What you cannot see yet is that the proxy can add some nifty functionality behind the hood. But before getting deeper into AOP, let's see some important terminology.
AOP jargon
The AOP terminology may be boring to get on with, but it is necessary to understand these words before going further.
Join point : a particular execution point. For example a method execution, or the handling of an exception.
Advice : simply said, it is the code to execute. For example, starting a transaction.
Pointcut : represents which join point an advice should be applied to
Aspect : pointcuts and advices form an aspect
Target object : the object being advised by some aspects
Weaving : "applying an aspect"
When an aspect is applied to an object, a particular advice will be applied to any join point matching a pointcut's expression.
Starting a transaction could be expressed the following way :
Aspect : start a transaction in methods which need to run in a transactional context
Join point : method is called
Pointcut : every method starting with "insert", "delete", "update"
Advice : start a transaction
NOTE: In Spring AOP, only the "execute method" join point is supported.
There are different types of advices
Before advice : executes before a join point
After returning advice : executes after a join point completes without throwing exceptions
After throwing advice : executes after a join point has thrown an exception
After (finally) advice : executes after a join point has finished, not matter if it has thrown an exception or not
Around advice : executes before and after a join point is executed
A simple advice
In the MooseSaloon example, let's apply a simple aspect :
Aspect : log every Saloon methods called
Pointcut : every Saloon methods of the MooseSaloon
Advice : log before the method is called
Don't worry about ProxyBeanFactory and MethodBeforeAdvice gorry details. The point here is just to illustrate what a proxy does behind the scene. Here is the advice we will apply to our saloon.
package com.javaranch.journal.spring.aop;
import java.lang.reflect.Method;
import java.util.Date;
import org.springframework.aop.MethodBeforeAdvice;
public class SaloonWatcher implements MethodBeforeAdvice {
public void before(Method method, Object[] args, Object target) throws Throwable {
System.out.println("[" + new Date() + "]" + method.getName() + " called on " + target);
}
}
The MethodBeforeAdvice's before() method will be called before a method of a target bean is called.
That's all. The Main class and the MooseSaloon class do not change. After execution, the printed information will look like this:
Saloon open [class com.javaranch.journal.spring.aop.MooseSaloon/
com.javaranch.journal.spring.aop.MooseSaloon@bfea1d]
Welcome to the Big Moose Saloon !!
mooseSaloon [class com.javaranch.journal.spring.aop.MooseSaloon]
--------
[Mon Mar 24 15:14:42 JST 2008]openSaloon called on com.javaranch.journal.spring.aop.MooseSaloon@2a4983
Saloon open [class com.javaranch.journal.spring.aop.MooseSaloon/
com.javaranch.journal.spring.aop.MooseSaloon@bfea1d]
Welcome to the Big Moose Saloon !!
proxySaloon [class $Proxy0]
Isn't that magic ? Not really, it's called AOP, using a proxy. Although the MooseSaloon class was not changed, we managed to report when a Saloon method is called. Can you now imagine how to manage transactions without modifying the existing code ?
A word on proxying beans
In the above example, there is a MooseSaloon and its proxy. In the main method, the proxy is explicitly instanciated via its name "proxySaloon". Wouldn't it be cool if we could use a proxy without even knowing it ? Actually, Spring uses a powerful feature called autoproxying, which will proxy selected beans behind the scene. There are different ways to achieve this. Here is one using the BeanNameAutoProxyCreator, which automatically create proxies depending on bean names. In part two of this tutorial, we will see how autoproxying is achieved using the @AspectJ annotations. But to illustrate the concept of autoproxying, let's modify the Main class, the bean definition file, and use a BeanNameAutoProxyCreator.
Let's remove the proxy from the Main class.
package com.javaranch.journal.spring.aop;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class Main {
public static void main(String[] args) {
ApplicationContext ctx = new ClassPathXmlApplicationContext("aop.xml");
// The mooseSaloon pojo
Saloon mooseSaloon = (Saloon)ctx.getBean("mooseSaloon");
mooseSaloon.openSaloon();
System.out.println("mooseSaloon [" + mooseSaloon.getClass() + "]");
}
}
And let's remove it from the definition file too. Instead, we will use the BeanNameAutoProxyCreator to create a proxy automatically on the MooseSaloon.
A proxy will be created for every bean whose name ends in "Saloon", just like our "mooseSaloon". After executing this new version, something similar to the following should be printed:
[Mon Mar 24 16:00:56 JST 2008]openSaloon called on com.javaranch.journal.spring.aop.MooseSaloon@5a9de6
Saloon open [class com.javaranch.journal.spring.aop.MooseSaloon/
com.javaranch.journal.spring.aop.MooseSaloon@5a9de6]
Welcome to the Big Moose Saloon !!
mooseSaloon [class $Proxy0]
Amazing, isn't it ? Look at the Main class. Although the "mooseSaloon" bean is obtained from the factory, the log information has been printed out. The class name is not MooseSaloon, but "$Proxy0". This shows that we are working on the proxy, not the bean itself.
You've made it
Congratulations, you've made it ! Don't think too much about MethodBeforeAdvice, ProxyBeanFactory or BeanNameAutoProxyCreator. These were used in Spring 1.2, but there are now other ways to use proxies and AOP since Spring 2.0, which will be the subject of this tutorial's next part. If you have understood what a proxy is, and still remember what the AOP main keywords are, you're fine for now.
(The data in this article is derived from Softletter's 2008 SaaS Report, available directly from
www.softletter.com. The complete table of contents and preview pages can be
viewed here. Further analysis from
the report will be discussed at Softletter's upcoming SaaS University seminar in Waltham, MA, June 18/19;
complete agenda.)
When preparing the latest release of Softletter's SaaS
(Software as a Service) Report we conducted a series of cross-tabs and drill
downs into the results and generated some interesting results we'd like to
share with you. In the 2006 report, only 15.4% of our survey respondents
replied that they were using Open Source in their product lines. The numbers
changed significantly for the 2008 report, with 28% reporting they used Open
Source in their SaaS systems. But our drill downs uncovered even more
interesting trends we'd like to examine.
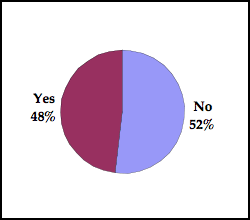
Is your SaaS product based on Open Source software?
Companies Under $1M in Revenue
The question is why are smaller SaaS firms turning to Open
Source in such large numbers? To gain insight into the issue, we contacted
several of our survey respondents and asked them. The answers broke down into
two basic categories: cost savings and time to market, a topic we look at in
greater detail further on in this article.
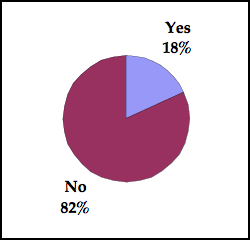
When we looked at the $1 to $5m cohort, the numbers shifted
dramatically down (results for the $5m to $10m and $10m to $99m segments are
similar to those for $1 – $5m):
Companies $1 – $5m in Revenue
Why the sharp drop off in enthusiasm for Open Source amongst
these larger firms? Again, we turned to the phones and E-mail. The most common
thread running through all the conversations we had was that these companies
had made their technology beds at this point and were focused on growing their
customer bases, new releases, and solving various sales and marketing issues.
Another factor was that while Open Source helped companies build prototypes for
proof-of-concept funding and early production systems that helped them reach
customer one, as development continued many firms were choosing to take their
systems proprietary to achieve scalability and performance goals.
When we looked at the last cohort we measured, the 100m+
segment, the numbers shifted again in favor of Open Source, though not quite so
dramatically as with the under $1m segment. When we spoke to management at
several large SaaS firms, a common thread running through our conversations was
that these companies saw Open Source as an infrastructure play, a means of
shaving cost off server management and application serving. The major secondary
reason offered was decreased development and component costs.
Companies $100m+ in Revenue
In order to discover more about the relationship between SaaS development trends and Open Source,
we contacted Wayne Hom, CTO of Augmentum, a major outsourcer
and development house focusing on resources from China. Augmentum recently finished a major development
effort for Etology, a SaaS-based firm that creates a virtual ad marketplace for niche publications
(such as Softletter).
Wayne, our recent Softletter SaaS survey indicated that
almost 50% of SaaS companies under $1M in revenue were basing their products on
Open Source software. What is your take on this trend?
Open Source can definitely assist a startup in getting to
market faster. With SaaS, time to market and reliable delivery of services is
key because of the extended ramp up to profitability.
Where Open Source truly shines is in its ability to function
as a community-driven store of components that can drive a new product's
underlying architecture. In this sense, Open Source replicates, but on a non-proprietary
scale, the platforms being assembled by firms such as Salesforce.com and
Netsuite. A new company looking to get up and running can rummage through a
vast array of Open Source projects and often find valuable resources that can
substantially speed their initial development efforts.
How do you know you'll be able to find what you need from the Open Source parts bin?
Open Source is very dynamic. Our business focus is on China
because of the number of new engineers and architect-level personnel being
turned out by their educational system. In terms of sheer volume, China is 10X
India in the technical resources it's producing. We have a dedicated team at
Augmentum for tracking the Chinese market in terms of Open Source technology;
we're almost always able to find useful components and systems for our clients.
We've discussed Etology; how did you use Open Source to speed up their time to market?
The key technology underlying their entire system is an ad
server. We used phpAdsNew (now OpenX) as the basic server engine. There wasn't
a good proprietary technology we could use and if we'd had to write an ad
server from scratch, it would have taken approximately six months. From the
time the project was spec'd out to launch was 45 days.
Was the product in its original configuration suitable for commercial use?
No, and that's a critical point when considering using Open
Source to get to market more quickly. Open Source can save you time and money
when you're thinking about acquiring customer one, prototyping, or building a
proof-of-concept version of your system for funding efforts. But I have never
seen a single instance where an Open Source technology didn't need substantial
reworking and proprietary extension for commercial use.
For example, phpAdsNew in its original configuration didn't
have strong fraud detection capabilities; we had to rip out that part of the
product and put in something new. Even more significant is that while the
product performed OK, it couldn't scale sufficiently as Etology's business
grew. By the time the company's website was serving two billion ad impressions
per day, we had rewritten the entire system in C++ for performance.
In our experience, while Open Source can get you to market
more quickly, once you're up and running, ongoing maintenance/development costs
are no different from commercial software. Also, when considering using an Open
Source technology for a project, you should remember that while the
functionality may be there and the cost is very attractive, once you crack open
the code, you may find it's not very good. This is not a criticism of the
programmers per se. The group or person involved may have wanted to prove a
concept or arrive at a quick and dirty solution to a problem. If there was no
incentive or reason for them to spend time optimizing their work, you should assume it hasn't been.
This is particularly true of smaller and less well publicized Open Source projects.
What about leveraging the Open Source community as the
product in its original configuration suitable for commercial use?
There are practical problems with this. One is that
companies do not want to contribute back to the community; they want to take,
not give. Interestingly enough, they'd love to pay in many cases for the
technology. Avoiding the GPL is not usually a question of greed; it's driven
more by a desire to focus on business and avoid the distractions and legal
issues the GPL introduces into a business.
The other issue facing community use is that even once you've contributed back,
Open Source development is a meandering process. The community may or may not contribute
and they'll focus on what interests them, not on your business priorities.
Every so often one encounters a file that is in some proprietary format not easily
readable by the standard I/O routines. Well, readable it is, to be sure, line
by line – but making sense of the content of the lines –documented as it may
be– has to be automated, and the format seems to be different than any other
one you've seen so far: not Properties, not CSV, not XML, not even HTML. No,
someone has let their imagination run wild and created something that no class
or library known to you can handle. What to do?
What's needed is a parser for this format, and while it's not hard to program one
for a format for which example files are available, this isn't something
that's fun to develop, and it's an error-prone process, too. Luckily, this is a
recurring problem, and much time and effort has been expended to study it, and
to come up with algorithms and tools to tackle it. It's the realm of lexers
and parsers. Once the domain of the venerable lex
and yacc tools of Unix lore, there is now no shortage
of tools generating Java code. JFlex is the standard lexer, and Antlr,
SableCC and JavaCC are the eminent parsers.
What's the advantage of using these tools? They allow us to specify the format not
by hardcoding a series of if/then statements
(like "if the last character was a '$' then read an integer, otherwise skip 5
bytes and read a string"), but as a set of rules that describe what is expected,
and what should happen if the expected input is indeed read
from the file. This is also much easier to adapt in case the file format ever
gets extended in the future (as these proprietary formats inevitably tend to be).
Arguably, these days XML should be used for these purposes, but it will be a
long time until the existing formats have truly gone away. Until then, lexers
and parsers can make some unpleasant coding tasks much easier to deal with.
This article introduces the JFlex library,
and shows how to use it to read a format well-known to all Java developers: properties files.
It starts out by recognizing just the core "key=value" lines, then we add comment lines,
then continuation lines (where the value is spread out over several lines), and
in the end we add an extension to the format – hierarchical properties that get
mapped to Java objects. It uses a number of ready-to-run examples that can be found
in this file which also contains the JFlex library.
A Basic Lexical Specification
The way lexers work is by creating a lexical specification. This is
essentially a collection of regular expressions mixed with Java code that gets executed
whenever one of the regular expressions matches part of the input file. One
could describe step by step what goes into such a specification, but instead
we'll look at the simplest-possible one that JFlex can use. Have a look at the
PropertiesReader1.flex file.
It eventually gets translated into a Java source file, so parts of it look like regular Java
source code. The basic structure is like this:
Import statements, just like in Java, and copied verbatim to the generated source code
%% – a delimiter
Various declarations that determine specifics of the class about to be
generated, e.g. the class name and visibility modifier.
${ – delimiter that indicates the start of the Java code block
Regular Java code that is copied verbatim to the generated source. In this case
it contains a main method that opens and parses a file.
%} – delimiter that indicates the end of the Java code block
%% – a delimiter
a list of states and their associated regular expressions
#8 is the most interesting one, so let's look at it in detail. It contains only a single rule:
<YYINITIAL> {
. {
readCharacter(yytext());
}
}
YYINITIAL is code for "start the parsing here". The rule
starts by specifying the regular expression that should be matched; in this
case it's the dot which means "match any character". If a character is matched,
the code in the brackets is executed – the readCharacter method is called. A few lines above
you can find its declaration, and you'll see that it takes a string as parameter.
So where does the yytext method
come from, and what does it do? It's a pre-declared method that returns whatever was
matched by the regular expression. So in this case it will always return the
single character matched before, which will then be printed to standard out by
readCharacter.
So let's see what happens. You can run the code by typing "make run1" or
Unfortunately, only parts of the file are displayed, and then an exception occurs: something
about "could not match input". How can that be, given that the dot should match
any given character? Turns out the dot matches all characters but newline (\n). So we need a second rule that
specifically matches a newline. That's what PropertiesReader1a.flex does; it adds this rule:
\n {
readNewline();
}
If you run it via "make run1a",
it'll run to completion and print every character in the properties file.
On To The Properties
Now that we have a program that can parse a file (although not yet in a particularly
interesting way), let's teach it about property keys and values. Take a look at
the end of PropertiesReader2.flex.
It introduces two important features. Firstly, it gives names to particular
regular expressions. Here, "WhiteSpace"
and "LineEnding" are
defined. By defining these we can refer to them by name later on, which is nice
if we want to use them several times. Plus, using a name makes it easier to
figure what's happening compared to looking at the raw expression.
The second important features are states. The previous example only had a
single one –YYINITIAL– and we didn't have to declare it. It is always present,
so that the parser knows what to start with. In this case, two more are defined
– KEY and VALUE. KEY is used for parsing the left side of a property line, and
VALUE for the right side.
So the way to read the specification is the following:
Start in state YYINITIAL
If a white space or line ending is found, ignore it
For anything else, it's the start of a key, so we switch to the state that handles keys.
That's what the yybegin method does.
In state KEY
Read as many characters as possible NOT including an equal sign – that's the value of the key
Then, switch to reading the value.
In state VALUE
Again, read as many characters as possible, not including a line ending – that's the value.
Upon encountering a line ending, switch back to the initial state.
Whew! It takes a bit of time to learn how to read such a specification, but once you
understand the concept of named regular expressions, and how they are used to
switch between different states it becomes much clearer. One feature I didn't
mention, and that's the call to yypushback
in the last rule of YYINITIAL.
That rule matches if something significant was read – the first character of the key.
If we simply switch to the KEY state, that character would be missing from the key, so this method
tells the parser to take that one character and "push it back into the input
stream". That way it will be read again in the next step, and the KEY state has
a chance to see it. This is needed in situations where there is no distinct
separator character between different parts of the input file.
If you run this code ("make run2"
or its equivalent), it'll print out all the key/value bindings in the file, in this case:
{key1=value 1, key2.key3=value 2 and 3}
Comments
PropertiesReader3.flex adds support
for comments to the parser – lines that start with "#". A new state is added
–COMMENT– which reads all available characters until the line ending, and
simply prints it to the console. We also need a new rule in the INITIAL state
that switches to COMMENT upon encountering "#". Note that in this case we don't
need to call yypushback, because
that character isn't part to the comment – it acts as a delimiter only.
Continuation Lines
The last missing piece are continuation lines – property values that span more than
one line. A line that is to be continued has a backslash ("\") at the end. It
signifies that whatever is on the next line is still part of the value. This
can go on for more than a single line, allowing for lengthy values without the
need to include very long lines in the file. PropertiesReader4.flex supports this.
Remarkably, the only change required is one new rule in the VALUE state. In plain
text it says "If there's a backslash in the value, with nothing but white space
following it until the line ending, append the text (without the white space)
to the value, AND stay in state VALUE." That way, the next line read is treated
as part of the current value, and not the start of something new.
Beyond Standard Properties
The last example –PropertiesReader5.flex–
adds support for hierarchical properties, something that's not part of standard properties.
Properties with a numerical suffix like
are stored in a Map with keys "0", "1" and "2". This isn't meant to be tremendously
useful, just an example of how easy it is to extend the parser. All that's
needed is one new rule in the KEY state that especially handles keys ending with a
numerical suffix. Imagine the amount of code needed if you were to program this by hand.
That's All Folks
Reading an uncommonly formatted file (or other textual input) isn't something you need
to do often, but if you do, it's made much easier by using the right tool for the job.
Hand-crafted parsers are tricky to get right, and tend to be brittle during maintenance.
JFlex lexers have been built for C++, Groovy, Java, JavaScript, XML, HPGL, PxM
images, CSV, RTF, Java Properties (just now :-) and probably much else. I've
found JFlex easy to work with, and the generated code easily fast enough for my
purposes. Your mileage may vary, of course, but it certainly merits checking out.
JavaRanch: Thank you for agreeing to answer our questions, Bear. Before we start, I need to read you
your rights. You have right to keep silent, if you don't want to answer some question for whatever reason,
or without reason at all, just skip it. You also have the right to write your own questions and answer them –
it's a "DIY" kind of interview. Remember that everything you say can and will be used against you.
Bear Bibeault: I have read and understand my rights.
JR: Why did you choose JavaScript over real programming?
BB Where's the camera? Shouldn't there be a camera or something? Oh wait, this
is an online interview. Never mind. What was the question?
JR: Why did you choose JavaScript over real programming?
BB: Is my tie on straight?
JR: Sigh, you're not wearing a tie. Are you always this way?
BB: No. Sometimes I tend to wander off the subject.
JR: Why did you choose JavaScript over real programming?
BB: (chuckles) Well, first of all, let's ditch the notion that JavaScript is somehow not a
real language. We have seen a rather interesting phenomenon with JavaScript in that, of all the languages
in broad use today, JavaScript is probably the most widely used, but little understood language.
JavaScript is included in millions and millions of web pages, but most page authors
don't deeply understand the language that they are using. As a functional language,
JavaScript is actually quite interesting, almost fascinating.
Luckily, today's focus on Rich Internet Applications and Ajax has sparked an interest in
JavaScript that's leading more and more page authors to delve into the language itself.
A movement I call "Beyond the Image Roll-over".
I've met a lot of people who claim that they hate JavaScript but I've found that for
the most part they either haven't really taken the time to understand the language and give it a fair shake, or
are reacting to the browser DOM (which is an abomination). Or both!
As to why I chose it... Well, I didn't. It chose me!
JR: How is that?
BB: Anyone who's followed my posts on JavaRanch knows that my core competency is
server-side Java, particularly Servlets and JSP. But as with all serious web developers, I
have to wrap my mind around the myriad alphabet soup technologies that a good web
devo needs in his toolbox. And yes, that includes JavaScript.
I've proposed a few books on server-side technologies, but none of them have gone
anywhere. The general consensus seems to be that "everything that needs to be written
about Servlets and JSP has already been written". I don't happen to believe that that's
true, but I guess that I haven't been all that convincing as of yet.
But RIAs and Ajax are things that people want to read and learn about, so that's what
publishers are interested in. And so the three books I've written to date focus on the
client side of things. You gotta write what people want to read!
But I haven't completely given up on my idea for a book on JSP...
JR: What should server-side Java programmers know about recent developments in JavaScript?
BB: Well, obviously the advent of Ajax has had an impact on how the server side is written.
While the big, full-page refreshes are still alive and well (despite the predictions of their demise),
they are augmented by increasing hoardes of smaller requests made via Ajax to "service" that page
until the time comes for it to be replaced.
Which not only brought the concept of HTML fragments
to the server side (as opposed to the predominance of full HTML pages), it also brought JSON into the mix.
And now, with the addition of the scripting engine and Rhino to Java 1.6, well, that's a
whole 'nuther ball of worms that server-side devos need to figure out how to use to best advantage.
JR: What are the perspectives for JavaScript as a language? Where can it expand to?
BB: Well, as I said, to the server. Netscape flirted with server-side JavaScript in the past, but
that rather went the way of the dodo. But with full Java support and the power of the
Rhino engine behind it, JavaScript's migration to the server is all but assured. Just how
it will be used is anyone's guess at this point. But we're a clever bunch – we'll figure it out.
JR: So many web technologies have come and gone; how has JavaScript managed to survive?
BB: Every shiny new thing that comes along seems to go through a phase where it is going
the be "the killer app" that knocks HTML and JavaScript off the web. It never happens.
HTML and JavaScript are the basic building blocks upon which the web is built. Shiny
new things either build upon these blocks, or compete in a niche.
JavaScript is here to stay. Something is going to have to be very very very shiny in
order to knock it aside. I just don't see it happening anytime in the foreseeable future.
JR: What do you feel is the most powerful aspect of JavaScript?
BB: Its basis in functional programming – the very aspects that most people who use
JavaScript don't really understand.
I try very hard to emphasize these aspects, both in my books, as well as in my posts to
JavaRanch. If more page authors truly understood JavaScript's functional concepts like
closures and function contexts, the state of scripting on the web would be vastly improved.
JR: You mentioned JSON. What's that all about?
BB: JSON, which stands for either
JavaScript Object Notation, or JavaScript Serialized Object Notation, depending
upon who you are talking to, is essentially a way
of describing JavaScript data constructs based upon the syntax of JavaScript object literals.
It's a great data interchange format and is turning out to be very well-suited to moving
data from the server to the client.
JR: Why is that?
BB: It's incredibly easy to digest on the client. XML is a bear (in a bad way) to
digest with its rather heavyweight API. JSON only requires a simple call to eval() and
you're done!
It's also easy to generate and lots of server-side tools for dealing with it are cropping up. It's
not going to push XML off its data interchange throne anytime soon, but as far as Ajax is concerned, XML can no
longer claim to be King of the Hill.
Do you remember that board game, King of the Hill? It had this plastic mountain with a crown at
its peak...
JR: You mentioned wanting to write a book on JSP. Why do you think we need one more?
BB: ... and it had marbles as playing pieces ....
JR: Why do you think we need one more JSP book?
BB: ... and all these traps you could fall into.
JR: Focus! Book! On JSP.
BB: JSP underwent a major revolution with JSP 2.0 and no one seems to have noticed.
Oh, people are starting to use the JSTL and the EL (Expression Language) more and more – but a lot
of them are still writing web apps the same old way that they used to with JSP 1.x. They're just
trying to replace scriptlets line-by-line with JSTL/EL and finding out that that's not really where it's at.
Or worse: mixing scriptlets with JSTL/EL. (shudders)
To really take advantage of the "new JSP way", people need to change some of the ways that
they think about using JSP pages. Not a whole lot – but more than I've been seeing happen.
There are also some neat tips and tricks that I've learned along the way, some of which
I've written about in previous Journal articles, that I'd like to share with a wider audience.
JR: OK, back to the books you have written. The three books are
Prototype and Scriptaculous in Action in March 2007,
Ajax in Practice in May 2007 and earlier this year
jQuery in Action came out.
All three are about the latest developments in JavaScript... Does it feel like you are writing one book? If not, how are they different?
BB: Well the Prototype and jQuery books are similar in that they describe popular JavaScript libraries, but
the books are very different because the approach of the libraries themselves is so very different. Prototype makes JavaScript
look a lot like Ruby and adds a lot of names and classes to the global space, as well as modifying
the behavior of existing JavaScript classes and elements. jQuery, on the other hand, promotes
the concept of Unobtrusive JavaScript
and itself makes little incursion into the global namespace (two names, one of which is optional)
by using the Wrapper Pattern to add functionality to JavaScript elements without being invasive.
They really couldn't be more different if they tried. Actually, I guess they did try pretty hard...
These days, I always highly recommend adopting a JavaScript library such as Prototype or jQuery
especially if you're going to be doing any Ajax. There are so may pitfalls and browser quirks that these
libraries handle for you that it's madness to try and write it all yourself. Why hit yourself in the
middle of the forehead with a ball-peen hammer if you don't have to?
Ajax in Practice is very different from the other two books in that it shows how to use Ajax to solve
real-world problems that web developers face every day. It's perfect for either people who already know some
Ajax and want to put it to good use, or people who have heard about Ajax and want to know if it can help them
solve some of the issues that they've been encountering.
Now can I ask you a question?
JR: Ask me a question? No, not really.
BB: What is your main goal when interviewing people?
JR: To make them discover something about themselves, something they didn't know?
BB: I didn't know that I was so boring. Thanks for that!
JR: On your blog, The Bear Den, you talk a lot about cooking. Does your programming
experience influence your cooking style?
BB: Well, when people ask me for a recipe, I give it to them in XML. Does that count?
JR: Can you think about a case when your cooking experience influenced your programming?
BB: Splashing tomato sauce into the keyboard definitely has an effect.
Seriously, I think that one of the reasons that I like cooking so much (besides because I like to eat)
is that it's so completely different from programming. While I feel that programming is
as creative as it is an analytical endeavor (at least for me), the sort of creativity that goes
into cooking is of a different sort. Besides, my other hobbies are digital photography and videography;
both if which involve being plopped in front of a computer. Cooking is the one interest I have that
doesn't involve a keyboard.
Unless you count using the iMac in my kitchen to look up recipes, or enter them into a database.
JR: You have an iMac in your kitchen?
BB: Of course, to look up recipes, surf while waiting for a sauce to reduce, stream
iTunes from my upstairs PowerMac, and moderate JavaRanch first thing in the morning while my
coffee brews. Don't you?
JR: Explain the motorcycle in exactly 42 words.
BB: Riding a motorcycle is as close as you can get to flying while still keeping two wheels to
the ground, riding with the wind in my hair. OK, I have no hair and I always wear a
helmet, but you get the idea.
JR: That was 43 words.
BB: Bill me for the extra word. Make it the I, that's probably the cheapest.
BB: None of those really suit my style. Can't we stick with misdemeanors?
JR: No.
BB: Dang. Then I'd have to pick espionage. Except that I'd be a double agent! That way, I
could still be the good guy and Matt Damon would play me in the movie version.
Though they'd probably have to hold him down while they shaved his head.
JR: What would you most like to say in Russian?
BB: "Just show me the way to the blasted bathroom!"
JR: You've done three big projects with Manning. After all the work, does Manning feel more like a Mother or a Father to you?
BB: Neither actually. But the Publisher, Marjan Bace, often likes to chat with the authors by
phone. These conversations are always engaging and thought-provoking, but somehow,
I always feel like I'm being sent to the Principal's Office when one is scheduled.
JR: Did you get sent to the Principal's Office a lot when you were in school?
BB: Hardly ever! I was a complete goody-two-shoes! I didn't develop my bad boy image
until... wait, I never did develop a bad boy image. I'd better get to work on that...
Authentication can defined as the process to confirm the identity of an user.
This can be achieved in a variety of ways, e.g. by entering a password, swiping an ID card,
or using a biometrical scanner. The user need not be a human being, but can be a computer process.
Authorization can be defined as the process of deciding whether an authenticated
user/system is allowed to access a certain resource or perform a certain action or not. A
system may have many logical sections/modules, and not all users might have
access to all modules. For example, one would not want an employee of a company
to be authorized to get into parts of an application related to the company's
appraisal system or other confidential data. This is where authorization comes
into play. Though the user might have authenticated himself, he might not have
sufficient authorization to access certain particular data items.
Both the above –authentication and authorization– are addressed by JAAS.
What is JAAS?
As the name –Java Authentication
and Authorization Services– suggests, it provides a
framework and an API for the authentication and authorization of users, whether
they're human or automated processes. Both parts provide full-fledged
capabilities and can be used in small-sized applications as well as enterprise
applications, where security is a major concern. JAAS was inspired by PAM
(Pluggable Authentication Module); one might say that JAAS is a Java version of
PAM. It was introduced as an optional package for use with JDK 1.3, but has
been integrated as part of the standard JDK 1.4.
JAAS uses a service provider approach to its authentication features, meaning that it is
possible to configure different login modules for an application without changing any code.
The application remains unaware of the underlying authentication logic. It's
even possible for an application to contain multiple login modules, somewhat
akin to a stack of authentication procedures.
In this article we will discuss the authentication part of JAAS in detail, starting with the various
classes and interfaces which are involved, followed by a ready-to-run example.
Classes and interfaces
LoginModule (javax.security.auth.spi.LoginModule)
Login modules are written by implementing this interface; they contain the actual code for
authentication. It can use various mechanisms to authenticate user credentials. The code could
retrieve a password from a database and compare it to the password supplied to
the module. It could also use a flat file, LDAP or any other means of storing
user information for that purpose. Generally, in enterprise networks all
authentication credentials are stored in one place, which might be accessed through LDAP.
The login context is the core of the JAAS framework which kicks off the authentication
process by creating a Subject.
As the authentication process proceeds, the subject is populated with various principals and
credentials for further processing.
Subject (javax.security.auth.Subject)
A subject represents a single user, entity or system –in other words, a client–
requesting authentication.
Principal (java.security.Principal)
A principal represents the face of a subject. It encapsulates features or properties of a subject.
A subject can contain multiple principals.
Credentials
Credentials are nothing but pieces of information regarding the subject in consideration.
They might be account numbers, passwords, certificates etc. As the credential represents some
important information, the further interfaces might be useful for creating a proper and secure
credential – javax.security.auth.Destroyable and
javax.security.auth.Refreshable.
Suppose that after the successful authentication of the user you populate the subject
with a secret ID (in the form of a credential) with which the subject can
execute some critical services, but the credential should be removed after a specific time.
In that case, one might want to implement the Destroyable interface.
Refreshable might be
useful if a credential has only a limited timespan in which it is valid.
The process of authentication
The authentication process starts with creating an instance of the LoginContext. Various constructors are available; the example uses the LoginContext(String, CallbackHandler) variety. The
first parameter is the name (which acts as the index to the login module stack
configured in the configuration file), and the second parameter is a callback handler used for
passing login information to the LoginModule.
CallbackHandler has a handle method which transfers
the required information to the LoginModule. The
example uses a very simple handler which saves the username and password in an
instance variable, so that it can be passed on during the invocation of the
handle method from the LoginModule. It's also
possible to create callbacks that interact with the user to obtain user credentials, and transfer
that information to the LoginModule for authentication.
An empty Subject is created before the
authentication begins. This is passed to all login modules configured for the application.
If the authentication is successful, the subject is populated with various principals and credentials.
The login method in the LoginContext is used to
start the login process. After its successful completion, the application can
retrieve the Subject from the
LoginContext using the getSubject() method.
The login process has two phases. In the first phase, the individual login module's login method is invoked, but at
this point the principals and credentials are not attached to the subject. The
reason being that if the overall login fails, the principals and credentials
attached to the subject are invalid, and have to be removed.
If the login process is successful the commit methods of
all login modules are invoked, and the individual login modules take care of
attaching the appropriate principals and credentials to the subject. If it
fails then the abort method would
be invoked; that gives the login modules a chance to perform any necessary cleanup.
The login method of the login module
should return true if the
authentication is successful, false if this module should be ignored, and it throws a LoginException if the authentication fails.
JAAS configuration in detail
Let's take a look at a sample JAAS configuration file.
With this configuration, two login modules have been configured
under the name RanchLogin: FirstLoginModule and SecondLoginModule. Each login
module is configured with a flag, which decides its behavior as the
authentication proceeds down the authentication stack. Other dynamic
information related to specific login modules can be passed using key/value
pairs. One parameters is supplied to the first login module (debug, and two to the second (debug and email). These parameter values can
be retrieved from within the module. The possible flags are:
1) Required – This
module must authenticate the user. But if it fails, the authentication
nonetheless continues with the other login modules in the list (if any).
2) Requisite – If the login fails
then the control returns back to the application, and no other login modules will execute.
3) Sufficient – If the login succeeds then
the overall login succeeds, and control returns to the application. If the
login fails then it continues to execute the other login modules in the list.
4) Optional – The authentication process
continues down the list of login modules irrespective of the success of this module.
An example
A login configuration file is needed, which specifies the login module to be used.
The file name is passed as a JVM parameter via a
-Djava.security.auth.login.config="JAAS_CONFIG_FILENAME" switch.
The following code shows a simple example.
The code triggering the authentication (com.javaranch.auth.Login)
CallbackHandler handler = new RanchCallbackHandler(userName, password);
try {
LoginContext loginContext = new LoginContext("RanchLogin", handler);
// starts the actual login
loginContext.login();
} catch (LoginException e) {
// log error (failed to authenticate the user - do something about it)
e.printStackTrace();
}
Login configuration file (loginConfig.jaas). It ties the name "RanchLogin" (used in the previous paragraph)
to the class RanchLoginModule (shown in the next paragraph).
Implementation of LoginModule in the class
RanchLoginModule
public boolean login() throws LoginException {
boolean returnValue = true;
if (callbackHandler == null){
throw new LoginException("No callback handler supplied.");
}
Callback[] callbacks = new Callback[2];
callbacks[0] = new NameCallback("Username");
callbacks[1] = new PasswordCallback("Password", false);
try {
callbackHandler.handle(callbacks);
String userName = ((NameCallback) callbacks[0]).getName();
char [] passwordCharArray = ((PasswordCallback) callbacks[1]).getPassword();
String password = new String(passwordCharArray);
//--> authenticate if username is the same as password (yes, this is a somewhat simplistic approach :-)
returnValue = userName.equals(password);
} catch (IOException ioe) {
ioe.printStackTrace();
throw new LoginException("IOException occured: "+ioex.getMessage());
} catch (UnsupportedCallbackException ucbe) {
ucbe.printStackTrace();
throw new LoginException("UnsupportedCallbackException encountered: "+ucbe.getMessage());
}
System.out.println("logged in");
return returnValue;
}
Authentication with a SecurityManager
There's one problem with this code - if a security manager
is present (as it is likely to be in applications worth protecting) an
exception is thrown. We have to give certain permissions to the code using the policy file:
We have to grant the code AuthPermission
with target createLoginContext,
so that it is allowed to instantiate a LoginContext object.
To run the code with a security manager we also need to pass a -Djava.security.manager parameter to
the JVM, along with the location of login configuration and policy files. Alternatively, it's
also possible to modify the default policy file that comes with the JDK directly.
Running the examples
Make sure that jaas.config, policy.config and the jaas-example.jar file are in the same directory.
(There are also Ant targets named runCase1, runCase2, runCase3 and runCase4 that will execute
these test program with the specified parameters.) The complete, ready-to-run code can be
downloaded here.
Not all the good stuff is in these Journal articles. The Saloon sees lots of insight and wisdom
all the time, and the staff is continuously reviewing interesting books and blogging about
this, that and the other. Plus, we've got book authors hanging out with us all the time.
So here are a few nuggets you may have missed that should prove interesting to many folks.
Big Moose Saloon
A question about how to comment code so it's understandable by other people leads to a discussion
on the various ways to comment Java code -and whether it should be necessary in the first place-
in
How (and why) to comment code.
A rancher is asked to evaluate Maven for a project, and finds it hard to get started with.
Seeing that many people swear by it, he wonders what its benefits might be. Other ranchers
offer lots of insight and reasoned opinions for and against using Maven in
Maven: What's the big deal?.
Contemplating vinyl records and telephones with rotary dials, a rancher wonders what else our
kids just won't understand when they see it. Lots of responses in
What our kids won't understand indicate that we'll have a lot of explaining to do.