Volume 5, Number 3 (July, 2006)
Managing Editor: Ernest Friedman-Hill
Special Time-warp Issue!

|
by Ulf Dittmer No matter how many functions an application has, there are times when a user wants to do something that the original developers have not foreseen, and which is not included in the application. Even worse, it might be something really specialized that only she needs, and which will never be added by the software vendor. One solution might be to export the data, work on it with a different application which has the desired functionality, and then re-import it. Another option would be to extend the application by using its API, if it provides one. One way of doing so is through plugins: chunks of external code that are accessed through the application, and use its API to perform a function that the application itself can't. One application whose plugin API is very successful is Adobe Photoshop, which even spawned a market for commercially available plugins. While Photoshop plugins are written in C, the mechanism is really language-independent, although it is constrained by the language the host application is written in. This article shows how a plugin API can be added to Java applications. (Examples of Java plugins in a broader sense would also be the Applet API in web browsers, and the Servlet API in web servers. These are atypical, though, and what is described here is more like what Photoshop does.) Generally speaking, there are four steps involved in the process.
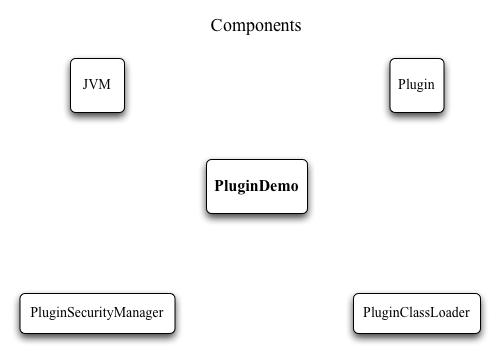
Figure 1 shows the various pieces of code that help implement all of this.
Figure 1: Components of the plugin mechanism; PluginDemo is an example application that shows the various pieces in action Step 1: Defining the APIIn order for the host application to treat all plugins the same way, we define an interface which the plugins need to implement. The methods of the interface can be thought of as ”lifecycle“ methods - operations the host application calls to initialize a plugin, set parameters, execute it, get results and shut it down. In the example, we require plugins to implement the PluginFunction interface. It defines four methods:
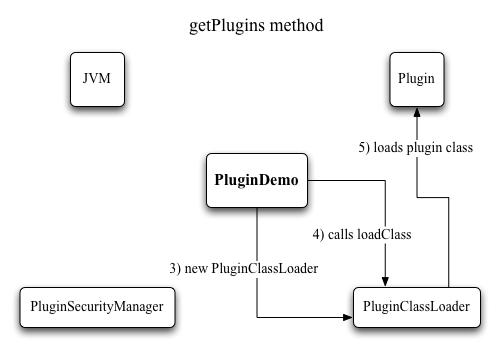
Looking at these calls, it's clear that the plugins are rather limited - there is just a single functional call, which takes an integer parameter and returns an integer result. Real plugins would likely have methods for initialization and cleanup, and probably more than one functional method. A more powerful approach might involve several different interfaces, with differing characteristics and different lifecycle methods. E.g., there could be plugins with and without a GUI, or plugins that receive and return more complex types, or that require a more complicated flow of control. But for the introductory purposes of this article, we limit ourselves to the interface shown above. Step 2: Determine plugin acquisitionWe need to define how a an application acquires or gets to know about plugins. In this example we confine ourselves to loading plugins from a particular directory on the local hard disk, which is a common way for desktop applications. The directory will be called ”plugins“, and is located directly inside the main application directory. One important question to consider is at which time the application scans the directory to discover plugins. The easiest way is to do it just once at startup, at which time the plugins haven't been loaded and run yet. With a bit more work one could allow plugins to be added later, i.e., scan the directory again, and add any plugins that weren't there during the previous scan. A useful feature is to be able to update plugins without the need to stop and restart the host application. For server applications in particular this would be unfeasible, especially in a production setting. The problem with updating plugins -which are essentially Java classes- is that once a class is loaded, it can't be unloaded. In some circumstances it may be possible by discarding the ClassLoader that loaded the class, but if objects of the class are long-lived (perhaps because the application keeps references to them), then even that would not work. Interlude: ClassLoader and SecurityManagerOK then. There's been talk of class loaders, but what do those have to do with plugins? To fully understand the reasons, we need to look at security managers as well. Although those two concepts have been part of the Java API since version 1.0 (that was back in 1995, folks), and are crucial pieces of the Java infrastructure, it's perfectly possible to develop with Java for years, and never have to deal with either of them directly. Class loading is comparable in some way to linking: it deals with how the JVM finds and accesses classes. The system classes that make up the Java API are available automatically to all Java applications, but other classes must be be added in specific ways so that the JVM knows how to find them. E.g., web applications look for additional classes in the WEB-INF/lib and WEB-INF/classes directories, while applets load classes over HTTP from the host they were served from, and desktop applications look at an environment variable called CLASSPATH and a command-line switch named -classpath. So one reason why we need our own class loader is that it needs to look into the plugins directory for additional classes. We could add that directory to the classpath, and thus have the application class loader load those classes just like all other ones, but that would run counter to the second reason: we don't trust plugin classes. Yes, that's right: after all the effort to produce a functional, well-tested, bug-free and useful plugin, the application does not trust it to do the right thing. No way. Remember that the reason we have a plugin mechanism in the first place, is to add functionality to the application by someone other than the application developer. It could be you (who you trust), it could be someone in your company (who you probably trust), it could be your buddy's nephew (who you possibly trust, but maybe not), or someone on the other side of the planet, who you don't trust right away, but whose plugin you still want to use. The solution is to run the plugin code in a sandbox, where it has limited rights, and can do little or no harm. For example, a plugin should most definitely not be able to read the tax return files from your local hard disk and upload them someplace else. The sandbox can be established by using a security manager. Most Java desktop applications are run without one, on the premise that you trust any application that you install and run on your local machine. But plugins violate this premise, so we need to distinguish between trusted code (the Java class libraries) and untrusted code (the plugin), and prevent the untrusted code from doing bad things. Using a class loader helps with the former -it can determine which class loader loaded a particular class-, while a security manager accomplishes the latter - it can define in a very fine-grained way which operations a particular class is or is not allowed to do. For example, access to the local filesystem is right out, as are any network operations, or the ability to call System.exit and thus cause the application to quit. And now, back to the four-step program. Step 3: Creating a ClassLoaderFrom the above it may seem that class loaders are arcane and tricky to develop. Fortunately, that's not the case. When extending java.lang.ClassLoader, there's only a single method to implement. It gets passed a string with the name of the class to load, and hands back a Class object of that class. From that object, the application can then instantiate the runtime objects of the plugin class. Let's look at the source of PluginClassLoader. In its constructor, we tell it which directory the plugins are in. We could have hardcoded that, since there is no way to change it in the application, but this bit of flexibility makes the class more easily reusable. All the interesting action is in the loadClass method. Three cases need to be considered: 1) the class is loaded already, in which case it can be found in the cache that is kept of all loaded classes, 2) the class to be loaded is a system class, in which case the loading is delegated to the system ClassLoader, and 3) if neither of the above, then the plugin directory is examined if it contains a class file with the required name. If it does, then the bytes that physically make up the class are loaded, and handed off to the defineClass method (which java.lang.ClassLoader implements, so we don't need to worry about it). The result is the desired Class object, which can then be returned from the method. We're done! Note that this class loader only deals with class files, not jar or zip files. But support for those can be added simply by more elaborate file I/O, and has little to do with class loading per se, so we won't implement that here (that would be a good exercise for the reader, though).
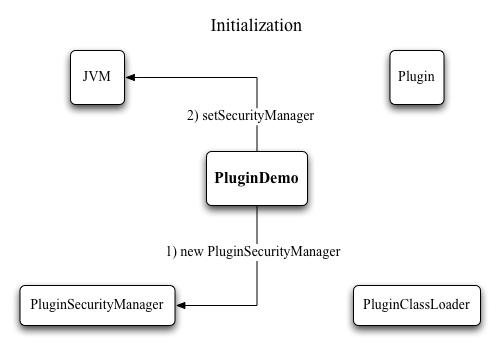
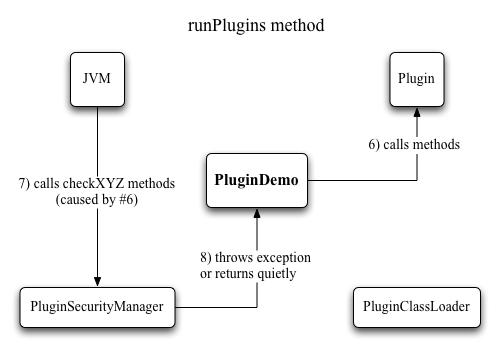
Figure 2: Loading plugins with a class loader Step 4: Creating a SecurityManagerJust like with the class loader, writing the security manager is made easier by the fact that we can extend java.lang.SecurityManager, and only need to override the methods that specify what permissions to grant and which to deny. If you look at the source of PluginSecurityManager, you'll see plenty of methods named checkXYZ. Each one of those checks whether access to some specific system feature should be allowed or denied. There are a few methods dealing with file I/O, a few about network activity, and a number of other ones like printer access, clipboard access, execution of external code, access to system properties and quitting the application. Every single one of these in turn calls the trusted method, which simply checks whether the executing code runs inside a class loader (a different one than the application class loader, that is). If it is -meaning the code currently running is plugin code- an exception is thrown, which signals to the JVM that the requested action should be denied. So, you ask, if everything is denied, then what can the plugins do? Still plenty, actually. It's just that everything they need to have in order to run must already be part of the class, or be passed in through the setParameter method. Going back to the example of Photoshop plugins, even though file import or export of images wouldn't be possible, any kind of filtering of an image would be perfectly possible. It is also possible to differentiate permissions based on what kind of class is executing. If a plugin implements some kind of I/O interface, access to disks could selectively be allowed.
Figure 3: Initialization of the security manager
Figure 4: Running plugins with a security manager ExamplesTo illustrate the technique, we look at a simple example application, PluginDemo. It chiefly consists of two methods: getPlugins, which searches through the plugins directory for classes that implement the PluginFunction interface and loads and instantiates the ones it finds, and runPlugins, which in turn tries to run each plugin by calling its getResult method (after first setting its only parameter by calling setParameter). 1) Unpack the zip file containing the sample code, and run the PluginDemo application by typing ”java -classpath . PluginDemo“ on the command line. The output is: FortyTwo ( 1 ) = 42 PlusOne ( 2 ) = 3 Square ( 3 ) = 9 That means that 3 plugins were found, named ”FortyTwo“, ”PlusOne“ and ”Square“, respectively. To each it passed the parameter shown in parentheses via the setParameter method, and got from it the result shown to the right of the ”=“ sign, via the getResults method. The plugins perform simple tasks: The first one always returns 42 regardless of the parameter, the second adds 1 to the parameter, and the third squares it. If you look at the source of the plugins, you'll notice that they are not in a package named ”plugins“. The fact that they can be loaded and run is thus not due to the classpath being set to the current directory, but to the class loader that looks for classes in a directory named ”plugins“. 2) Now move the Fibonacci.class file from the other directory to the plugins directory and re-run the application. You'll see that there is now another line of output, showing the result of the call to the Fibonacci plugin. Since this one is a tiny bit more involved, it can signal an error (if the parameter is smaller than zero, since the Fibonacci function is defined for positive numbers only). The hasError method implements a simple way for a plugin to signal an error condition to the host application. Keep in mind that this is very basic, merely meant to illustrate the technique. 3) Now move the TryToExit.class file to the plugins directory as well. The other plugins run as they did before, but the new one causes a security exception, which PluginDemo catches. It responds to that by printing a message telling us that something forbidden was prevented. What exactly was that? The plugin is basically a copy of FortyTwo, but it has an additional line calling System.exit, which is not allowed by the security managers checkExit method. As an experiment, make a copy of TryToExit.class, and place it in the same directory as the PluginDemo class. If you rerun it, something strange happens - no result is printed for the plugin. That's because this time, the call to System.exit succeeded, and the application just quit before execution returned to the host application. Why would it do that? Because TryToExit is now part of the regular classpath, and loaded by the application class loader, not the plugin class loader. That means it is run without a security manager, and thus no checks and balances apply to its execution. This demonstrates that particular care must be taken in where to put classes when multiple class loaders are involved, or strange and undesirable things can happen. 4) Now move the last plugin, ReadFile.class, to the plugins directory as well. It reads two numbers from a file called input.txt, and returns their sum as the result (yes, you're right, it's not a very useful function, but it illustrates the principle). The execution of the plugin is prevented -this time because file I/O is not allowed-, but now we want it to succeed, so we'll have to modify the security manager. Take a look at the source of PluginSecurityManager, and search for the checkRead method. You'll find 3 of them, but we're only interested in the one that takes a String parameter. As it is, it ignores which file should be read, and simply calls trusted() to check for the presence of a class loader. If we remove the comment slashes of the two lines before that, we have enabled it to actually look at the file that should be read, and if that is inside the plugins directory, the method simply returns. Thus no security exception is thrown, which signals to the application that the file is allowed to be read. Now compile it with those lines activated, and rerun the application. But no dice - we're still not allowed to access the file. Time to study the javadocs of the file I/O methods we use. The getParentFile method doesn't do anything illegal, but getAbsolutePath is declared to throw a SecurityException if a required system property can't be accessed. This is governed by the checkPropertyAccess method of the security manager. By printing out the property keys that are passed to it, we can determine that it's the user.dir property which is needed here. So we allow it to access that particular property by specifically checking for it, and then skipping the call to trusted. If you recompile the class after commenting in the additional line in that method, and then rerun the application, no exceptions will occur, and the sum of the two numbers in the file will be printed as result of the plugin call. This goes to show that securing an application is a very fine-grained process, where great care must be taken to determine what to allow whom to do. Wrapping upCreating a plugin API is a powerful way to extend an applications usefulness. It is rarely possible to foresee precisely how an application might get used, and letting a user extend what it can do is a good way of dealing with that. In addition to calling more or less passive methods -like the above example does-, we could also let plugins play more active roles. An event interface could be defined that allows a plugin to be called whenever certain system events occur. Furthermore, the parameters passed to the plugin might include application-internal data structures that would allow the plugin to manipulate the host application in very fundamental ways. If you're interested in studying a more complex example of a successful plugin API, I recommend having a look at ImageJ (http://rsb.info.nih.gov/ij/). It's a public domain image processing application and library, so the source is available. Its plugin API allows a user to add custom image processing capabilities, advanced automation techniques, and support for a number of image formats which the application itself does not handle. The plugin support revolves around the ij.plugin.PlugIn interface (for plugins that create windows) and ij.plugin.filter.PlugInFilter (for plugins that operate on existing images). ImageJ employs a particular directory (called plugins) which it searches for classes implementing one of these two interfaces. Those it displays in a menu called Plugins, thus allowing the user to select them to run. Plugins can also be loaded from jar files. Since most ImageJ plugins are distributed with source and are thus open to inspection, the plugin handler does not concern itself with security, and doesn't use class loaders or security managers. A wide variety of plugins are available at http://rsb.info.nih.gov/ij/plugins.html. Before we part, it's time to confess something: creating security managers in the way shown here is considered obsolete, which is why you'll get plenty of obsolescence warnings when compiling PluginSecurityManager. Java 2 introduced a newer method based on declarative security and the Permission class, which is now the preferred way of securing Java code. The problem with the old-style approach is that each time new methods are added to the class library which do something potentially dangerous, new methods need to be added to all security managers: it's programmatic security, not declarative security like the permissions scheme allows. But the approach used here is still fully functional, and adequate for the purposes of a plugin handling mechanism, where the API changes rarely, if ever. Return to Top |
||||||||||||||||||
|
by Ajith Kallambella
Part II of a series
IntroductionThis January Ant celebrated its 6th year birthday. In January of 2000, the Ant tool, which was created by James Duncan Davidson to build his Apache project called Tomcat, was moved out of the Tomcat source and into a separate Apache project. Since then it has brought the words "build" and "manageability" closer than ever. Ant gained popularity because of its simplicity, extensibility and cross platform support and within a short span of time has become the build tool of choice for a large number of commercial and open source projects alike. Although Ant has been extremely successful as an enterprise build management tool, most Ant implementations do not use some of the advanced features provided by the tool. In this article, we'll look at a few advanced techniques that can unleash the true powers of Ant, and turn this mere build tool into an indispensable enterprise asset. Examples are provided where applicable, but lack of detailed code is intentional. It is important to focus on the concepts, not so much on the implementation. Software is a writing. Ideas expressed in software, just like in art, music, plays and other media, can be done in many unique ways. Familiarity with the Ant tool and some experimental spirit is all that you need to turn these techniques into real working code. Automating testsOne of the tenets of Agile development is "test early, test often". It is about implementing common sense testing strategies that make the overall quality of the software that you ship better. By incorporating frequent testing (preferably automated testing) and frequent build/test/deploy cycles, you will detect bugs earlier. To quote Martin Fowler - the key to successful testing is "test to show an application, or parts of it, doesn't work" as opposed to "test to show it works", which is not as rigorous, and hides the real problems till you deploy and start getting support calls. Ant's support for standard testing suites such as JUnit, HTTPUnit, Cactus and a host of other testing software lets you integrate testing cycles with the build process and get into the groove of Test Driven Development. Although TDD has been around for a while, I have personally seen a large number of projects that don't leverage this integration. Running tests manually is a wasteful use of a talented developer, and it is error prone due to the human factor. A well written suite of tests should be a part of every build process. Running automated tests is especially useful for typical software development companies that have globally distributed development teams. If you are in the Ant enthusiasts camp, or simply sitting on the testing fence for a while, here are some strategies worthy of consideration:
Continuous automation and continuous integrationActivities involved in a typical SDLC workflow offers several opportunities for automation, and Ant offers unlimited possibilities. Here we focus on integrating with Source Code Management(SCM) systems. Ant tasks are available to talk to most popular SCM systems, including CVS, Subversion, ClearCase, Continuus/Synergy, Microsoft Visual SourceSafe, Perforce SCM, PVCS, SourceOffSite and StarTeam. With Ant's powerful SCM support, you can hook up parts of the build process to your source control system and perform continuous integration tasks such as check out, check in, baselining etc. Marry that with automated testing, and you can detect bugs as early as the day they got in to the source stream. Once you plumb the verification suite from your build file, you can test after every edit to make sure that nothing breaks. The benefits are substantial. Beyond process maturity and repeatability, a rigorous and portable build process the incorporates elements of continuous integration often results in fewer bugs, higher quality and dollars saved. If you are not yet on the Agile bandwagon, here are some interesting possibilities to tease you into trying this out:
You can even build automated edit analysis scripts that checks for modified source files and submits them for a verified check-in process. Ant project contributors use Ant's own source code analysis tool: ant -f patch.xml to automatically generate a patch file to Ant. With some ingenuous hacking, you can actually make this work for your project too. For the sake of brevity, I am omitting the details, but the patch.xml file distributed with Ant source download should serve as a good starting point. If you still need help, drop me a line. Technique: Stretching AntAnt isn't a silver bullet and there are times when you reach a dead end with its capabilities and you may need to take things into your own hands. For example, your build script may need some authentication information from an internal LDAP or Active Directory server in order to promote code from development to production; or you are required to retrieve a build number from an internal repository for baselining an integration stream in CVS. Such needs often call for functionality that is not available from an out-of-the-box Ant installation. There are two main approaches to extending Ant: invoke an executable or OS command from within Ant, or write a custom task (i.e., a taskdef.) Let's talk more about the second option: writing custom tasks. Custom <taskdef>It helps to know that under the covers, Ant tasks are just Java classes. In theory, any Java class can be cooked into an Ant task simply by extending org.apache.tools.Ant.Task class and implementing an execute() method. Here's where you do the work.
package mytasks;
import org.apache.tools.Ant.BuildException;
import org.apache.tools.Ant.Task;
public class CustomTask extends Task {
public void execute() throws BuildException {
// ...
}
}
And then, you simply include it in a build file using the <taskdef> tag to adds the new task definition to the current project. <target name="run" >
<!-- Define task -->
<taskdef name="customTask"
classname= " mytasks.CustomTask"
classpath="${src.mytasks.dir}"/>
<!-- Invoke task -->
<customTask>
<!-- . . . ?>
</customTask>
</target>
We've glossed over a lot of details here. Although execute() method is where the crux of the work is executed, a lot of things happen before it is invoked. It is important for task writers to understand, among other things, the lifecycle of a custom task, custom datatypes, and the concept of TaskContainer. See http://ant.apache.org/manual/develop.html for more details. Approach task writing with caution - it should not be an everyday affair. With an army of free Ant extensions (distributed as custom tasks) available for use, first search for a tool that meets your needs. Resort to creating your own as a last resort. In order to be a successful task writer, follow these guidelines:
Distributing custom tasksConsider creating an antlib to group all custom tasks and types together. Ant libraries or "antlibs" are JAR files with a special XML descriptor that describes the contents, somewhat analogous to a deployment descriptor in a WAR or an EAR file. The XML file defines custom tasks and types defined in the library, and follow a simple URI-to-package name mapping that makes it easier for the Ant runtime to locate the custom implementation. For instance, an URI reference antlib:com.customtasks:mytask suggests Ant to load com/customtasks/mytask/antlib.xml from the JAR file, also containing the class files that make up the custom tasks and types. Antlibs serve as a practical way to keep custom tasks and types in sync and distribute them in a standard packaged format. Simply drop custom Antlibs in your ANT_HOME/lib directory and Ant will find them, load them and use them. If you'd like to make your custom task available to users as if it were a core Ant task, you can do so by adding the implementing class (org.apache.tools.Ant.Task) to default.properties file in the org.apache.tools.Ant.taskdefs package. This may mean you'll have to build a binary distribution yourself after modifying the default.properties. By the way, default.properties file is a great resource for finding out taskdef implementation classes. Using Ant's Java APISince Ant is also a Java library, it can be used programmatically. It means Ant targets, both core and custom, can be invoked through any Java program. If you have a significant investment in Ant as an enterprise asset and have written custom tasks specific to your software development organization, the Java API allows painlessly reusing them, and increases your return on investment. Lets say you have a custom task that requests a build number from an enterprise repository. You could now write a Java client program that uses the Ant API to invoke the same task externally, and distributed the Java client to Project Managers so that they can request and use the build number in task management artifacts. Technique: Intelligently resolve dependencies using <jarlib-resolve>Let's go back to our hypothetical financial organization (see Part I of this article) one more time and augment the software development organization with a new architecture group. This group is tasked with building common shared artifacts for other application groups to consume. This group is busy producing shared jar files, and new revisions of them. As they research and discover better ways to accomplish things, they roll out revisions to existing libraries - typically shared jar files, for internal consumers. An extended logging tool, a library of XML utilities, a pattern box, a .NET bridge to access company wide Active Directory server etc are all good examples of shared components provisioned by the architecture group. You've probably noticed a problem here. We need to manage change without adding chaos to the equation. How can we ensure that application projects have an option to continue using old (and compatible) jar files until they are ready to move over to new revisions? How can we manage dependencies without shaking up the foundation every time there is a new internal release of a shared component? Enter the Ant core task <jar-lib-resolve> and the concept of expanded tagging. Version 1.3 of the Java 2 Platform introduced support for tagging an expanded set of Jar-file manifest attributes (http://java.sun.com/j2se/1.3/docs/guide/extensions/versioning.html) information to enable accurate downloading of jar files by the Java plug-in tools. The idea is to let the Java plug-in access these attributes before downloading the jar file to determine if a specific optional package matches the vendor and version criteria specified by the client. The pre-download introspection avoids downloading a wrong library and therefore, ensures perfect compatibility even when multiple library versions are available. The following portion of a sample manifest file from ant.jar illustrates some extended attributes as defined by Sun's "Optional Package" specification. Manifest-Version: 1.0 Ant-Version: Apache Ant 1.5.3 Created-By: 1.4.1_01-b01 (Sun Microsystems Inc.) Main-Class: org.apache.tools.Ant.Main Class-Path: xml-apis.jar xercesImpl.jar optional.jar xalan.jar Name: org/apache/tools/Ant/ Extension-name: org.apache.tools.Ant Specification-Title: Apache Ant Specification-Version: 1.5.3 Specification-Vendor: Apache Software Foundation Implementation-Title: org.apache.tools.Ant Implementation-Version: 1.5.3 Implementation-Vendor: Apache Software Foundation Ant folks followed suit and invented the <jarlib-resolve> task. They brought in the same intelligence found in Java plug-in tools of locating a specific jar file based on extended manifest attributes in to the new <jarlib-resolve> task. <jarlib-resolve> does two things: it locates a jar file based on a specific set of extension values, and assigns the location to an Ant property. It works with the concept of an <Extension> and <ExtensionSet>; these are custom data types that represent all available extension attributes for the jar file manifest. Since both <Extension> and <ExtensionSet> can be assigned with an unique ID, just like a classpath refid, they can be reused. This means, you can cook <Extension> or <ExtensionSet> definitions one per every revision of a shared jar file, and globally publish them so that internal consumers simply refer to the appropriate ids in their call to <jarlib-resolve>. As may now be apparent to you, property value assigned by successful <jarlib-resolve> can be preserved for the entire scope of the build process for managing both compile time and runtime dependencies. Combine this with strategies for designing by contract, chaining and failing, you can easily envision a build system that not only resolves dependencies, but also verifies them at relevant places and fails gracefully. Technique: Beyond building: automating configuration, setup and installation tasksIt's a shame if you haven't been using Ant for building. No, let me rephrase that - if you have been using it only for building. Why? Because the rich set of tasks, both core and extended, can be used accomplish a lot more useful things beyond mere building. Simple tasks can be scripted to automate mundane, repetitive and error prone jobs. If you are running a software shop, consider the process of setting up a new development environment for a new hire. A typical setup process constitutes configuring a database, version control system (SCM), IDE, the application server, and perhaps a few environment variables. Setting up each tool can quickly get complicated and may involve multiple steps. And don't forget that the guy is new, so there is a large probability of a mistake. In this scenario, would you rather hand him a script to run, or a 27 page document with instructions and screen shots? Although the latter works, it is error prone because of the human factor involved. Most setup and configuration tasks that I have seen can be automated, and Ant proves as an excellent tool for such automation. Using Ant for automating complex configuration tasks is especially useful when the process involves multiple steps, an array of software tools, and a fair amount of interdependency in how each tool is setup and configured. For instance, you can script an Ant file to setup the database using <sql> task. Use another script with Ant SCM tasks to pull base-lined code from your SCM. Then use app server specific extensions to Ant to configure a local server, setup JDBC connection pools, JMS connection factories, logger settings etc. Spend a few hours in writing ( and of course testing! ) these scripts, and then weave them together into a master module. Hand it over to the new hire and I bet she'll be impressed. Not to forget the fact that you have increased developer productivity and saved money you'd otherwise spend in both documenting the setup instructions and, more often than you think, fixing a corrupted setup. As an illustration of how Ant can be scripted to perform a complex configuration task, take a look at Weblogic's extensions to Ant here at http://e-docs.bea.com/wls/docs81/admin_ref/ant_tasks.html. Using standardized scripts to automate installation and configuration also offers other benefits such as better manageability, easy tool migration, smooth rollouts for configuration changes, repeatability, process maturity and tangible improvements to the overall bottom line. Closing RemarksComplexity is a fact of life in modern software development. Organizational structure, geographically dispersed teams, changes within the software development team, vendor dependency, and managing post-production changes all negatively affect the efficiency of both the process and economics of writing software. While Ant is not a tool for reducing complexity, it can be for put to good use for managing complexity. Hopefully the techniques and strategies presented here in will inspire you in to thinking about creative uses for the tool. If you already use Ant in your team, hopefully I have convinced you that utilitarian appeal of Ant extends beyond its original intent as a build tool, and that you will start expanding its usage to include other opportunities such as configuration automation or adopting continuous integration methodology. Return to Top |
||||||||||||||||||
|
by Ulf Dittmer In anticipation of the release of Java 6, which will include a standard for integration of scripting languages with Java called ”JSR-223“, there is a heightened interest in the subject of combining scripting languages with Java. While a quasi-standard API (BSF) has existed for a while, it's also possible to use a scripting engine through its native API. While this approach eschews some of the benefits of both JSR-223 and BSF (e.g., the possibility to use scripts in any language, not just one particular one), it makes it possible to use advanced features of a scripting language that cannot be accessed through a standardized API. This article looks at the capabilities of the Rhino JavaScript engine, which has been around for quite a while. It's important to realize that Rhino implements the JavaScript language only; there are no window or document objects which in a web page could be used to manipulate the page content. That's because Rhino does not operate in a browser environment (even though its origins are in Netscape's abortive attempt to write a web browser in Java). Applications use script engines generally in one of two ways: embedding, which means external (e.g. user-defined) scripts are called by the application, or scripting, which means that an external script calls a Java application (or library) for its own purposes. Loosely speaking, in embedding mode, the script does something for the application, while in scripting mode, the application does something for the script. Rhino can be used for both purposes. ExamplesThe following examples illustrate how a Java application can interact with JavaScript scripts, and how data is passed back and forth between both languages. The source code, which also includes the Rhino library, can be downloaded here. Examples 1 through 4 can be run from the command line by java -classpath .:js-1.6R3.jar Example1 (replace Example1 by Example2 etc.), while Example5 is run by java -classpath js-1.6R3.jar org.mozilla.javascript.tools.shell.Main -f scripts/example5.js Example1 is just about the shortest possible host application that calls into Rhino to make it do something. It creates a Context for executing JavaScript and uses that to call the example1.js script. The script in turn defines a simple function and calls it with a particular parameter (42). The result of the function is passed back to the Java application where it is converted to a double and printed to standard out. String or boolean values could also be handled through the toString and toBoolean methods, respectively, instead of toNumber. Example2 is a little bit more complicated. It reads the script example2.js -which defines a single JavaScript function that takes two parameters-, but instead of calling it directly, it causes the function to be compiled into a Function object. This allows the function to be called repeatedly with varying parameters. The application then calls the compiled function ten times with different parameters. Note the difference between cx.evaluateReader used in Example1, which interprets a complete script in one go, and cx.compileFunction and func.call used in Example2, which deal with one particular function. Example3 introduces the Scriptable object, which can be used to pass named variables back and forth between Java and JavaScript. In the example, an Integer (”javaNumber“), a String (”javaString“) and System.out (”systemOut“) are passed to the script, while the ”result“ variable is set in the script and then read by the host application. In addition, the script uses the System.out object to invoke its println method, and thus cause output to be written to standard out. This works via the Java Reflection API, and can be used to invoke any method of any object accessible to a script. Example4 demonstrates how to invoke methods in several other ways. It completes the construction of a GUI which the Java application has begun. Note that in order to access Java classes, they need to be prefixed by ”Packages.“, so e.g. java.awt.Button becomes Packages.java.awt.Button. This is necessary to distinguish Java objects from regular JavaScript identifiers (which ”Java“ would otherwise be). Finally, Example5 does away with the Java host application completely. It consists of just a JavaScript script that constructs a Java GUI application. It also introduces the ”importPackage(java.awt)“ notation, which is similar to the Java import statement, and allows us to write ”Button“ instead of ”Packages.java.awt.Button“. In addition, it shows how event handlers (an ActionListener and a WindowListener) can be used. Advanced topicsThe previous examples introduced some of the basic features of the Rhino scripting engine, but it has plenty of advanced capabilities, which at least merit a brief mention.
Return to Top |
||||||||||||||||||
|
by Paul Wheaton The Problem (and intermediate solutions)I have worked on no less than five projects where the standard, when I arrived, was to have a build.properties file right next to the build.xml file. Both go into version control. What always happens is that somebody changes a property to make the build work on their system. Then they check in their changes and everybody else's build breaks. The most common first solution is to simply not check in that file. This works kinda-okay until somebody accidentally checks it in. Then at least one person's properties file gets wiped out and .... no backup. And if you are new to the project, you need somebody to feel sorry for you and e-mail you a copy of a properties file to get a start. Sure, there can be documentation - but I have yet to see the documentation be kept up. And I have experienced multiple projects where the solution was to develop to the documentation and when it doesn't work, exchange e-mail with somebody until the documentation works. The next solution is to put build.properties into your home directory and have ant find it there. This works until you have more than one project. Then you change it to flooberproject.properties or start having properties like flooberproject.db.schemaname. This solves the problem of somebody accidentally checking in the properties, but incoming developers still need to depend on somebody sending them a properties file. The next improvement is to make a conf directory within the project that is in version control. This directory contains lots of username.properties files. This solves the incoming engineer problem and brings all the pluses that come with version control, but there are a couple of minor problems introduced. One is people that have the same username. Or the same person (with the same username) developing from two different boxes. Another is that sometimes you have data that you are not comfortable with moving into version control (a password perhaps?). Some Desired GoalsA) Have as few properties defined outside of build.xml as possible.I have seen projects that have hundreds of build properties defined. I'm sure when they started out they had two or three. And then there were forty. And then it just grew and grew and nobody could come up with a clear reason to not just add a few more now and then. Here's one reason: Anybody new coming to the project needs to understand these before they can configure them correctly. It is far easier to understand eight properties than three hundred. I think that if any project has more than 15 properties, it should be considered a bad smell and something should be done. Maybe the project is too big and should be broken up. Maybe there are a lot of things that can be moved into build.xml - not every developer needs it to be different? Maybe some coding standards could eliminate some properties? Maybe some properties are not being used any more? The focus of this article is properties that change from developer to developer. Once you have just a few properties to manage, everything else becomes much easier to solve. I have to say that having fewer properties is (IMO) ten times more important than what is being covered in this article. And it would be silly to write an article that simply says "use fewer properties." I only mention it because it is such a serious problem for some shops and there isn't a better time/place to express it. B) Try to keep as many properties as possible in version control.If the properties you are currently using are in version control, then when new people come to the project, they can look at the most recent property files that other developers are using and emulate those properties files. Further, if you make changes and those changes turn out to be poor, well you always can look up your older properties in version control! C) Provide a mechanism for sensitive properties to not be in version control.Database passwords are an example of something that you might want to keep out of version control. But when we are talking about a development box, and the database is configured to not talk to anybody outside of the box ... well, maybe it isn't such a big deal. As long as some people can have security if they want it and some people can go the version control route if they want that. D) Provide a mechanism to share build properties between projects.If you have really good communication between teams and within teams, you will avoid duplicated effort and use shared resources. If any one team will have, say, eight projects they are working on during a year, and some common property needs to change, it just seems wise to facilitate making the change just once and all of the projects still build properly. E) Properties need to be self documenting.Be considerate of engineers coming to this project. Also be considerate of the other engineers on a project when you are adding properties. A doc file, a readme file or a wiki can help, but they can easily become outdated and lead to confusion. Actual, functioning properties files make for an excellent form of documentation. Using "fail unless" ant tasks can help too! A Hybrid SolutionThis is just one humble solution. I suspect that there are many others that will work great. And I can't help but think that as the years pass, this solution will be enhanced. I'm a big fan of "do the simplest thing that could possibly work". In this case, all of the solutions mentioned earlier are simpler than what I'm about to propose. But the needs do exceed each of these solutions. So while this hybrid solution does add four lines to the simplest ant script, it does solve several problems. And when combined with making it a standard (as it now is for JavaRanch projects) there is predictability. The reason why I call this a hybrid is that it attempts to collect properties from any one of three places used in the previous solutions! Each solution has strengths and weaknesses. With all three you have all of the strengths and you have eliminated all of the weaknesses. I think that the optimal use of the hybrid approach is to keep as many properties as possible within version control (a config directory in the project). Keep sensitive properties in one of the user home properties files. Keep properties shared between projects in the common property file. Drop these ant tasks into the init of your build.xml to pull this off:
<property file="${user.home}/${project.name}.properties"/>
<property file="${user.home}/build.properties"/>
<property name="config.filename" value="${user.name}.properties"/>
<property file="config/${config.filename}"/>
So when I'm working on the floober project on windoze, I can put my properties in one of these three files:
C:\Documents and Settings\paul\floober.properties
C:\Documents and Settings\paul\build.properties
C:\work\floober\conf\paul.properties
And if I sometimes work from home, where my login is the same, I can define "config.filename" in build.properties in my home dir as, say, "paul_home" and then keep the rest of my properties in paul_home.properties in the conf directory for all projects. Since ant always uses the first definition of a property and ignores any attempt to change a property, you can declare some default properties in build.properties and override them with project specific properties in your home dir. You might be tempted to read in the config dir properties first, but that will eliminate the ability to define config.filename without adding yet another properties file. Self Documenting Build PropertiesOld, moldy programming pearl: Debug only code. Comments lie. Any time you leave something to the discipline of a human, you are looking for mistakes to be made. I've worked in shops where the technique to let you know about new properties was to send you an e-mail. So the next time you do a "get latest" from version control, you need to remember to look that e-mail up again and work the new properties in and test to make sure you did it right. Some shops use web pages or wiki pages. Some do both e-mail and wiki. Some put comments in the ant files. The problem with all of these is that things change, people forget to send the info, look up the info, or .... well ... all sorts of common, natural human stuff. And then it takes time to resolve things. Using the approach where properties go into version control helps a lot. If your build isn't working now and the last time you got the latest code was three hours ago, then somebody checked something in within the last three hours. Take a look at the config directory - if there is a file there that is less than three hours old, you found your culprit. A diff to the last version of the file will show you new or changed properties. What is proposed next is a pretty significant improvement. It does depend on the developer to remember to add one thing to the ant script, so there is still a hole in this process. But if that developer can remember this one thing, all of the other developers don't need to be as disciplined. For every property that needs to be defined by a developer, use fail/unless tags. Like so:
<property name="prop.message" value="must be defined, preferably in config/${config.filename}
(details at javaranch.com/props)"/>
<fail message="db.schema ${prop.message}" unless="db.schema"/>
<fail message="db.password ${prop.message}" unless="db.password"/>
Now, every time you have a required property, add one fail/unless tag. The next time the other six people on your team tries to build, each build will fail and a message will spell out exactly what to do. [Bonus Trick!] Instead of using fail/unless, simply declare a property after reading in the property files. It will act as a default. If somebody wants that value to be different, they can specify what they want in one of their property files! Beyond AntAnt is a fantastic tool. And now I'm ready for whatever is going to replace ant. I tinkered with maven for a while and ended up going back to ant. I had high hopes for gravy (groovy plus ant) and it doesn't seem to have caught on. As a Java programmer, I would like somebody to come up with something that lets me do loops and have a little more control over my build. Something that takes into account multiple developers, code re-use, CruiseControl, IntelliJ, sub projects, common projects, and ... properties! Return to Top |
||||||||||||||||||
|
by Andrew Monkhouse In a recent post, Swapnil Trivedi asked for help with some non thread-safe code that was not behaving the way he expected. While that particular problem could be solved without delving down into the depths of the produced bytecode, looking at it did present some interesting possibilities. So in this article I am going to look at a few simple threading issues, and solving them at a theoretical level, before eventually getting to a more complex example that may be easier to diagnose by looking at the bytecode. While I will be describing the bytecode in my particular example in some detail, I would recommend readers to Corey McGlone's excellent article: ' Looking "Under the Hood" with javap' from the August 2004 JavaRanch Journal for more details on javap. The code Swapnil presented could be boiled down to: public class TestThreads extends Thread {
static int i = 0;
public void run() {
for( ; i < 5; i++) {
System.out.println(getName() + " " + i);
}
}
public static void main(String args []) {
new TestThreads().start();
new TestThreads().start();
}
}
I am sure that most of you will have experimented with code like this at some point. And you will have seen that it is not possible to determine which threads will run in which order. For example, many of you will have seen output such as: Thread-0 0 Thread-0 1 While a later run might cause output such as: Thread-1 0 Thread-1 1 And yet another might cause output such as: Thread-0 0 Thread-1 1 And yet another might cause output such as: Thread-1 0 Thread-0 1 All fairly standard and expected. But what about output such as: Thread-0 0 Thread-1 0 Thread-1 1 Thread-0 2 Thread-0 3 Thread-1 4 That was the problem faced by Swapnil - not only did a number appear twice, but as a result 6 lines appeared in the output, not the expected 5. Thinking back to the code being run, it is very straightforward logic: for( ; i < 5; i++) {
System.out.println(getName() + " " + i);
}
We can consider there to be at least 3 code fragments in that block of code (the reason for the "at least" statement will be made clearer when we solve our final problem). Lets rewrite that code as a comparable do ... while statement to make the 3 code fragments a bit more obvious: do {
System.out.println(getName() + " " + i);
i++;
} while (i < 5);
We can now see that there is one line that is outputting data, another that is incrementing i and a third that is verifying that i is still in range. Since the Java Thread Scheduler can swap the threads at any point, it is quite plausible that Thread-0 ran the fragment System.out.println(getName() + " " + i); then the Java Thread Scheduler swapped to Thread-1 and ran the same fragment before either of them had a chance to increment i. Lets look at one possibility of that in slow motion: Thread-0 Thread-1 i output
---------------- ------------------ -- ----------
...println(i) 0 Thread-0 0
...println(i) 0 Thread-1 0
i++ 1
(i < 5) -> continue 1
...println(i) 1 Thread-1 1
i++ 2
(i < 5) -> continue 2
...println(i) 2 Thread-0 2
i++ 3
(i < 5) -> continue 3
...println(i) 3 Thread-0 3
i++ 4
(i < 5) -> continue 4
...println(i) 4 Thread-1 4
i++ 5
(i == 5) -> stop 5
(i == 5) -> stop 5
So far this seems simple. We have managed to find a probable cause, and even demonstrated it in theory, all without worrying about the nasty 'javap' command - but don't worry, I haven't forgotten about it :-). Lets go to a tiny bit more exotic case. In this example we will be incrementing and using the common variable in only one place: public class TestThreads extends Thread {
static int i = 0;
public void run() {
for (int j = 0; j < 50000; j++) {
System.out.println(getName() + " " + i++);
}
}
public static void main(String args []) {
new TestThreads().start();
new TestThreads().start();
}
}
Here's a small section of the output: ... Thread-0 10449 Thread-0 10450 Thread-0 10451 Thread-1 10453 Thread-1 10454 Thread-1 10455 ... Thread-1 12314 Thread-1 12315 Thread-1 12316 Thread-0 10452 Thread-0 12317 Thread-0 12318 ... Did you notice that the value "10451" is missing in the first block then appeared in the middle of the second block? But the variable i is only being referenced in one place? So therefore Java must consider this to be more than a single statement. Thinking about it for a moment, we do know that the println() method only accepts a String. Therefore logically that line could be rewritten as: String output = getName() + " " + i++;
System.out.println(output);
This allows us to logically see how the output above occurred - Thread-0 had incremented the value of i when creating the output string, but got swapped out before using it in the println() method. Making my example a little more complex, we are now using the same variable twice, but in what appears to be a single line of code: public class TestThreads extends Thread {
static int i = 0;
public void run() {
for (int j = 0; j < 50000; j++) {
String output = getName() + " " + ++i + " " + i;
System.out.println(output);
}
}
public static void main(String args []) {
new TestThreads().start();
new TestThreads().start();
}
}
Here's a small section of the output: ... Thread-0 69067 69067 Thread-0 69068 69068 Thread-0 69069 69069 Thread-1 69071 69071 Thread-1 69072 69072 Thread-1 69073 69073 ... Thread-1 70778 70778 Thread-1 70779 70779 Thread-0 69070 70779 Thread-0 70780 70780 Thread-0 70781 70781 ... Now we have something really interesting - the line that is out of sequence has 69070 in the first column and 70779 in the second column. It appears that Java swapped the threads while in the middle of the following line, which is building the String: String output = getName() + " " + ++i + " " + i; This is interesting - the answer to why this is happening is in the API documentation for the String class, but at only a single sentence it is easy to miss - it can be worthwhile to look at the API documentation now and see if you can spot the problem before continuing. In cases like this, where it is not immediately obvious what the problem is, it can be valuable to create a very simple test case that demonstrates the problem, then look at what the bytecode shows you. That is effectively what the code we are using is - the smallest amount of code that clearly shows a problem occurring. Rather than dump the entire javap -c TestThreads output and then discuss it, I am going to discuss some of the simpler sections first and get them out of the way, then move on to the all important run() method and break it up to make it simpler to understand (yes, the entire 4 lines of the run() method shown above do deserve to be broken up as you will see). In the following output I have reduced fully qualified class descriptions in the javap comments to the simpler class name so that I do not need to wrap lines. For example, where you would normally see java/lang/Thread referred to in the javap comments, I have reduced it to Thread. When we run javap -c TestThreads, we are first told what source code contains this particular class, then given the definition of the class: Compiled from "TestThreads.java"
public class TestThreads extends java.lang.Thread{
Next we have the definition of our static variable: static int i; Notice that in our source code we had provided an initial value for i but it is not listed here? That is because the java compiler moved the initialization to the static block. Normally we find the static block much later in the javap output, but I have moved it here to fit with the discussion's flow: static {};
Code:
0:iconst_0
1:putstatic #8; //Field i:I
4:return
So we can see that the constant value 0 will be put into storage area #8 which
is now effectively our Field i. By the way - the reason this is
storage area #8 is because for the sake of narrative flow I have moved that
method from where it appears in the output. Normally it would appear at the end
of the javap output. When we get to the later methods we will see the other
storage areas being used.
Keeping the narrative approach, I am going to skip code once again to the main() method, which looks like: public static void main(java.lang.String[]);
Code:
0:new #13; //class TestThreads
3:dup
4:invokespecial #14; //Method "<init>":()V
7:invokevirtual #15; //Method start:()V
10:new #13; //class TestThreads
13:dup
14:invokespecial #14; //Method "<init>":()V
17:invokevirtual #15; //Method start:()V
20:return
While not being completely straightforward, this is fairly close to our source code of two instances of new TestThreads().start(); The bytecode is a bit more verbose, but basically it creates a new instance of the TestThreads class, runs the special init method, then runs the start method. Not too difficult.
For the sake of completeness, I will also mention that the default constructor will appear in our decompiled output, as shown below: public TestThreads();
Code:
0:aload_0
1:invokespecial #1; //Method Thread."<init>":()V
4:return
Whenever you do not provide any constructors, the Java compiler will create a default constructor for you, which will call the parent class' default constructor. And this is what we see here - the created constructor calls the default constructor for the Thread class. Finally the bit you have been waiting for - now that everything has been set up, we get to the run() method. Just to save you scrolling backwards and forwards, here is the Java code for that method: public void run() {
for (int j = 0; j < 50000; j++) {
String output = getName() + " " + ++i + " " + i;
System.out.println(output);
}
}
So we start with the initialization of j to zero: public void run();
Code:
0:iconst_0
1:istore_1
That is the code that equates to j = 0; in our initializer. We immediately reload j and compare it with the value in storage area #2, which happens to be our magic number of 50000. If the two are equal we jump to line 67 (which is the implicit return statement at the end of the method). 2:iload_1
3:ldc #2; //int 50000
5:if_icmpge 67
We reloaded j, because this is a separate statement as far as both our original source code and the resultant code is concerned. This is the code that equates to j < 50000 in our evaluation expression, and we return to this block of code each time we go through the loop. If we are at this line, it must mean that j is less than 50000. So we need to build our String. We start by creating a StringBuilder to hold the interim string: 8:new #3; //class StringBuilder 11:dup 12:invokespecial #4; //Method StringBuilder."<init>":()V 15:aload_0 (hmmm, StringBuilder? More on that later) The first thing we want to do is find out the name of our current thread, and append it to the StringBuilder: 16:invokevirtual #5; //Method getName:()LString; 19:invokevirtual #6; //Method StringBuilder.append:(LString;)LStringBuilder; We can then load the String " " and append it to the StringBuilder: 22:ldc #7; //String 24:invokevirtual #6; //Method StringBuilder.append:(LString;)LStringBuilder; Then we will load the contents of the field i, increment it by 1, store a copy back in field i, and append a copy to the StringBuilder: 27:getstatic #8; //Field i:I 30:iconst_1 31:iadd 32:dup 33:putstatic #8; //Field i:I 36:invokevirtual #9; //Method StringBuilder.append:(I)LStringBuilder; We then append the same String " " used previously in line 22 to our StringBuilder: 39:ldc #7; //String 41:invokevirtual #6; //Method StringBuilder.append:(LString;)LStringBuilder; Note that we are constantly told that the Java compiler will recognize when we are reusing a String - here is an example in action. Even though our original line was getName() + " " + ++i + " " + i, the Java compiler recognized that the two instances of " " were the same, and only used the one reference to storage area #7 to get to the single instance of that String that it has put into the class file. Now we reload the value of i, and append it: 44:getstatic #8; //Field i:I 47:invokevirtual #9; //Method StringBuilder.append:(I)LStringBuilder; Finally our interim string building is complete and we can convert it back to a real String: 50:invokevirtual #10; //Method StringBuilder.toString:()LString; 53:astore_2 Then we can output the string: 54:getstatic #11; //Field System.out:LPrintStream; 57:aload_2 58:invokevirtual #12; //Method PrintStream.println:(LString;)V Finally we increment j by 1, and then go back to the top of the loop to repeat: 61:iinc 1, 1 64:goto 2 Just for completeness, we do have one more line: the implicit return statement at the end of the method. 67:return So - what does all this mean? It means that the following line from our original code is not considered a single statement by Java: String output = getName() + " " + ++i + " " + i; Rather it is more like: StringBuilder tmp = new StringBuilder();
tmp.append(getName());
tmp.append(" ");
int z = i;
z = z + 1;
i = z;
tmp.append(z);
tmp.append(" ");
tmp.append(i);
String output = tmp.toString();
Wow! It is hardly surprising that we were able to cause the Java runtime to swap threads in the middle of building the String given that we were doing all that work in a single line. Remember earlier that I mentioned that the answer to why this problem occurred in the API? Here is the explicit statement from the JavaDoc for String: String concatenation is implemented through the StringBuilder(or StringBuffer) class and its append method. Pretty simple to miss, but of of course we have just proven that ourselves. Hopefully this breakdown of a decompilation will help you in doing similar decompilations in the future, whenever you find code not acting in the manner you expected. As mentioned earlier, I recommend readers to Corey McGlone's excellent article: ' Looking "Under the Hood" with javap' from the August 2004 JavaRanch for more details on javap. On a final note, for those who would like to run those programs above and verify that the output can appear as I have shown, here is a very simple validator that should work for all the above cases: import java.io.*;
public class ValidateResult {
public static void main(String[] args) throws Exception {
if (args.length == 1) {
new ValidateResult(args[0]);
}
}
public ValidateResult(String fileName) throws Exception {
File f = new File(fileName);
if (f.exists() && f.canRead()) {
FileInputStream fis = new FileInputStream(f);
InputStreamReader isr = new InputStreamReader(fis);
BufferedReader in = new BufferedReader(isr);
int expectedLineNumber = 0;
String line = null;
for (line = in.readLine(); line != null; line = in.readLine()) {
String[] lineParts = line.split(" ");
String threadName = lineParts[0];
int lineNumber = Integer.parseInt(lineParts[1]);
int lineNumber2 = (lineParts.length == 3)
? Integer.parseInt(lineParts[2])
: lineNumber;
if (lineNumber == expectedLineNumber) {
expectedLineNumber++;
} else {
System.out.println(line);
expectedLineNumber = lineNumber + 1;
}
if (lineNumber != lineNumber2) {
System.out.println(">>>> " + line);
}
}
in.close();
}
}
}
You can send the output of one of the above programs to a file, and then run the above program on it. Something similar to: java TestThreads > tmp java ValidateResult tmp It should be noted, however, that Java might not be the best language for such a simple task. For example, when ensuring that my test cases generated the right output, I first started with some simple awk statements to quickly see the results: java TestThreads > tmp
awk 'BEGIN{EXP = 1}{if ($2 != EXP || $2 != $3) print; EXP = $2 + 1}' tmp
I find that single line much easier to write quickly than the equivalent Java program (but it would be much harder to maintain, and of course there are many things Java can do that awk and other tools can't). However knowing that there are other languages than just Java, and more importantly which ones to use in a given situation will make you a much better developer and far more sought after in the marketplace. But that could be a discussion for another time. :-) Return to Top |
||||||||||||||||||
|
Cattle Drive is a special place by Mapraputa Is From personal correspondence with Pauline McNamara:
JavaRanch: Cattle Drive *is* a special
place. To tell the truth, I feel intimidated even to ask about it... It
feels like one big conspiracy. Do you guys plan to take over the Ranch
some day? JavaRanch: What have you done in your life that feels closest to moderating on the Ranch? JavaRanch: Does moderating make you a better person? JavaRanch: Your first degree is in biology, the second in geography. Which is more useful for you as a programmer? JavaRanch: Which language is closer to Java, English? French? German? JavaRanch: Your work... Can you tell us what you do in one word? Two? Three? JavaRanch: What is the most American trait in you? JavaRanch: Is there anything else
you miss about the US? Is there anything about Switzerland you are
terrified to miss in case of leaving? JavaRanch: When I tell people that
I am from Russia, in 9 cases out of 10 the next question is "Is it cold
in Russia?" What do people ask you when you tell them you live in
Switzerland? JavaRanch: Are you a morning or evening person? JavaRanch: I am not a morning
person either. Ever wondered what is the reason to keep 9-5 schedule
for us, OK, let's say "me", if my brain wakes up by 11 pm? Any tips on
surviving in non-evening-person friendly environment?
JavaRanch: From your bio: what is it about your being a dedicated cappuccino drinker? JavaRanch: How do you think? Do
you think in pictures? Do you hear voices in your head? Draw boolean
algebra equations? How do you know that you are thinking? JavaRanch: Do you know where all this barbed wire on the Ranch came from? JavaRanch: Do you prefer two or three pin power plugs? JavaRanch: If you could choose a psychiatric disorder for yourself, what would you choose? JavaRanch: This question is stolen
from Kathy Sierra's blog: "Tell us something most people wouldn't know
about you (strange, unusual, etc.)". JavaRanch: The theme of this issue is "war". What war would you want to win? What to lose? Return to Top |
||||||||||||||||||
|
by Carol Murphy The longest day of the year has come and gone. Shoot, it's July already. High time to take a moment and look back on the last 3 months of the drive. Since we last checked in, we've had 8 greenhorns join us on the trail. Well, make that 7 greenhorns and 1 bartender and lowercase dad. Generally speaking, this has proven to be a scrappy bunch of cowpokes. 3 of 'em have already bagged their first Moose heads! We also had a couple of old-timers resurface, and the number of active drivers at the moment is an even baker's dozen. Now, let's get down to particulars....... Newbies!Our latest batch of greenhorns has been positively prolific in the amount of trail they have devoured. Let's welcome:
None of these folks were even in the saddle 3 months ago! I hope they aren't driving them doggies too hard, but that's pretty impressive trail blazin' for a bunch of greenhorns. Be sure to check out all the new Moose Heads here: http://www.javaranch.com/drive/halloffame.jsp. Sticking it outNo longer newbies, their saddles broken in and their expressions determined. It's hard to believe by the look of 'em that this bunch of riders with the grim visages were the new kids on the drive back in March. They are:
The old handsThe rest of us grizzled old riders are strung out along the trail from Java 4a to JDBC 3:
And then there is our mystery rider, Susan Brown. We don't know where she is, but if any of you run into her on the trail, say hey, and offer her a cup of Java. (or coffee, whatever she prefers.) Gosh, I hope I haven't overlooked anyone! With this many drivers on the trail I could very easily have missed one or two of 'em. But heck, there's always next time. Well, the sun is settling down onto the Pacific Ocean here at the western edge of the world, and I'm hoping all of you drivers have somewhere safe and dry to lay down your bedroll tonight. Happy Trails! Return to Top |
||||||||||||||||||
Return to Top |
||||||||||||||||||