|
Articles in this issue :
|
The Preferences Class
by: Thomas Paul
Whenever we needed to store user preferences (such as the four most recently used files) we could use the Properties
class. The problem with the Properties class is that it makes assumptions about where user preferences should be
stored. The basic assumption is that the file system would be used to store this information but this raises several
issues. Where in the file system should this data be stored? In the application directory, perhaps? What if the
user did not have write access to that directory? What if the user was running on a network computer?
The Preferences API, which is new to Java 1.4, was written to solve these problems. The purpose of the API is to
allow for the easy storage of user preferences without the developer having to worry about where this information
will be stored. The API determines the appropriate place. For example, when running an application in Windows,
the preferences will be stored in the Windows registry.
The API itself is found in the java.util.prefs package and is very easy to use. All preferences are stored in a
tree-like structure with the data itself stored in nodes of the tree. The nodes contain name-value pairs with the
actual preference data. The API allows for two different types of preference data. System data is shared among
all users while User data is used by the current user only. In this way, multiple users on the same device can
have their own preferences.
Getting a Preferences Object
Before you do anything with preferences you must get a Preferences object. Preferences is an abstract class so
it can't be instantiated directly. Instead you have to run one of the static methods of the Preferences class that
will return a real Preferences object. There are two ways to do this. The first method is to manually define a
tree structure. The second is to allow your package structure to define the tree structure. The second options
should not be used if your class is not in a package since the node will be "unnamed" and shared by every
class not in a package.
In order to manually define a tree structure, we need to first get a Preferences object. The Preferences class
has a static method to get either the System or User root preferences object:
Preferences prefs = Preferences.userRoot();
Preferences prefs = Preferences.systemRoot();
|
Once we have our root Preferences object, we can then get our node Preferences object by specifying the node we
wish to use. We can combine the two requests into one statement:
Preferences prefs = Preferences.userRoot().node("com/javaranch/prefs");
Preferences prefs = Preferences.systemRoot().node("com/javaranch/prefs");
|
The second option is to use a Preferences method which will use the name of the package that a class is in to determine
the nodes of the tree.
Preferences prefs = Preferences.userNodeForPackage(PrefsTest.class);
Preferences prefs = Preferences.systemNodeForPackage(PrefsTest.class);
|
Note: The beta version of the Preferences API allowed you to specify an object (such as "this") as a
parameter but the final version of the API requires that a class object be specified.
The node created by this command will be determined by the PrefsTest package name. If PrefsTest is in package "com/tom/test",
then the node created will be the same as if we had specified:
Preferences.userRoot().node("com/tom/test");
|
Now that we have a Preferences object, we can use it to store and retrieve user preference information.
Retrieving and Storing Preferences Data
The Preferences class has several methods used to get and put data in the Preferences data store. You can use
only the following types of data:
- String
- boolean
- double
- float
- int
- long
- byte array
There is a get and put method for each type. The get format is:
type getType(String key, type defaultValue)
So for the boolean, you would code:
boolean getValue = getBoolean("StoredBoolean", false);
|
For a byte array you would use:
byte[] getValue = getByteArray("StoredBoolean", new byte[0]);
|
The method name for the String version does not use the type in the name so to get a string you would use this
form:
String getValue = get("StoredString", "");
|
The get methods require that a default value be supplied. If no entry is found in the Preferences data store, the
default value will be returned.
The put methods are very similar. The form of the put methods are:
putType(String key, type value)
Here's an example of using preferences to retrieve the user's preferred number of rows to display and the preferred
color to display the rows in for an application:
int numRows = prefs.getInt("Rows", 40);
String color = prefs.get("Color", "Blue");
|
If the user had not previously saved any preferences the defaults of 40 rows and the color blue will be used. After
the user changes the preferences we can store them easily:
prefs.putInt("Rows", numRows);
prefs.put("Color", userColor);
|
Importing and Exporting Preferences
It may become necessary to save the user's preferences into a file. The Preferences class has methods to copy the
preference data into an XML file. The exportNode method will take the specified node and copy it to the specified
OutputStream in XML format. The format of the exportNode method:
void exportNode(OutputStream stream);
To create an XML file from our preferences we would do something like this:
prefs.exportNode(stream);
|
The output of this command will look something like the following:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE preferences SYSTEM 'http://java.sun.com/dtd/preferences.dtd'>
<preferences EXTERNAL_XML_VERSION="1.0">
<root type="user">
<map />
<node name="com">
<map />
<node name="javaranch">
<map />
<node name="preferences">
<map>
<entry key="Rows" value="80" />
<entry key="Color" value="Red" />
</map>
</node>
</node>
</node>
</root>
</preferences>
|
You can read this into a Preferences object by using the importPreferences method:
void importPreferences(InputStream stream);
Sample Program
Here is a simple program you can use as a sample. When you run it the first time, it will display the default values
of 40, and blue. When you run it the second time, it will display the new values of 80 and red. In addition, the
program will create an XML file and write it to, "prefs.xml".
import java.util.prefs.*;
import java.io.*;
public class PrefsTest{
public static void main(String[] args) throws Exception {
Preferences prefs = Preferences.userRoot().node("com/javaranch/preferences");
int numRows = prefs.getInt("Rows", 40);
String color = prefs.get("Color", "Blue");
new PrefsTest().putPrefs(prefs);
System.out.println("Color:" + color);
System.out.println("Rows:" + numRows);
OutputStream stream = new FileOutputStream("prefs.xml");
prefs.exportNode(stream);
}
public void putPrefs(Preferences prefs) {
prefs.putInt("Rows", 80);
prefs.put("Color", "Red");
}
}
|
If you are running under Windows, after running this program you can check the Windows registry and see the changes
that were made. Look under the node, "HKEY_CURRENT_USER/Software/JavaSoft". There you should find
"Prefs\com\javaranch\preferences". At the lowest node, you should find the keys containing the
stored preferences.
Conclusion
The Preferences API has some other features which we haven't discussed. For example, you can set Listeners to listen
for node value changes. More information on this can be found on the Sun web site at: http://developer.java.sun.com/developer/technicalArticles/releases/preferences/
If you have been using the Properties class to store user preference data in your applications you may want to
start using the Preferences API. It is generally easier to use and it is much more portable.
Return to Top
|
Introduction to the Java 2 Platform, Enterprise Edition (J2EE)Simon Brown, October 2002
IntroductionThis article, the first in a series, will introduce J2EE
and present an overview of what it is and what it can do. In addition to this,
we'll also take a look at how to get started with J2EE by presenting the steps
necessary to download, install and start developing J2EE applications.
Future articles will subsequently take a look at some of the core J2EE
technologies such as Java Servlets, JavaServer Pages (JSP), Enterprise JavaBeans
(EJB) and the Java Message Service (JMS). Following on from this, we'll move on
to take a look at J2EE from an architecture and design perspective, covering
topics like best practices and design patterns.
What is J2EE?Using the Java 2 Platform, Standard Edition (J2SE) as a
basis, Java 2 Platform, Enterprise Edition (J2EE) builds on top of this to
provide the types of services that are necessary to build large scale,
distributed, component based, multi-tier applications. Essentially, J2EE is a
collection of APIs that can be used to build such systems, although this is only
half of the picture. J2EE is also a standard for building and deploying
enterprise applications, held together by the specifications of the APIs that it
defines and the services that J2EE provides. In other words, this means that the
"write once, run anywhere" promises of Java apply for enterprise applications
too:
- Enterprise applications can be run on different platforms supporting the
Java 2 platform.
- Enterprise applications are portable between application servers
supporting the J2EE specification.
What does J2EE comprise?J2EE is comprised of many APIs that can be used
to build enterprise applications. Although the total list of APIs initially
seems overwhelming, it is worth bearing in mind that some are primarily used by
the J2EE environment in which your application executes, while some provide
services that your specific application may not require. Therefore, it is worth
remembering that you don't have to use all of them in order to build J2EE
applications. For completeness, however, the full list of technologies that make
up J2EE is as follows:
- Java Servlets
- JavaServer Pages (JSP)
- Enterprise JavaBeans (EJB)
- Java Message Service (JMS)
- Java Naming and Directory Interface (JNDI)
- Java Database Connectivity (JDBC)
- JavaMail
- Java Transaction Service (JTS)
- Java Transaction API (JTA)
- J2EE Connector Architecture (J2EE-CA, or JCA)
From a developer perspective, the main technologies are EJB, JSP, Java
Servlets, JDBC and JMS, although JNDI is used for locating EJBs and other
enterprise resources. For the moment, let's take a quick look at some of these
technologies before moving on to see how to get started with J2EE.
What are Java Servlets?At a high level, Java Servlets are the Java
equivalent of CGI scripts that can be used to perform processing and the
servicing of client requests on a web server. From an implementation
perspective, servlets are simply Java classes that implement a predefined
interface. One use for servlets is that they can be used to dynamically generate
content for presentation to the user, and this is achieved by embedding markup
language (e.g. HTML) inside the Java code. As Servlets are written in Java, they
have access to the rich library of features provided by Java, including access
to databases and other enterprise resources such as EJB.
What are JavaServer Pages (JSP)?JSP is another technology for
presenting information to the user over the web and uses a paradigm where Java
code is embedded into the HTML - the opposite of servlets, and much like
Microsoft ASP. Pages are written as HTML files with embedded Java source code
known as scriptlets.
One of the pitfalls in using JSP is that it is very easy to build large pages
containing lots of embedded Java code and business logic. For this reason, JSPs
provide easy integration with JavaBeans and another feature called JSP tag
extensions. These custom tags (also known as custom actions) allow re-usable
functionality to be encapsulated into XML-like tags that can be easily used on
the pages by both page developers and designers.
What are Enterprise JavaBeans?EJB is a major part of the J2EE
specification and defines a model for building server-side, reusable components.
There are three types of enterprise beans currently supported by J2EE - session
beans, entity beans and message-driven beans.
Session beans can be seen as extensions to the client application and are
typically used to model business processes. There are two types of session bean
- stateful and stateless. Stateful session beans are typically used to record
conversational state for a single client between requests, whereas stateless
session beans are shared between any number of clients at any one time.
Entity beans are typically used to model persistent business entities and, in
particular, data in a database. A common mapping is to model an entity bean on a
table, there being one instance of that bean for every row in the table. There
are two ways that persistence can be achieved - container managed and bean
managed persistence. In container managed persistence, a mapping is defined at
deployment time between the persistent properties in the bean and the columns in
the table. With bean managed persistence, developers write the JDBC code that
performs the create, read, update and delete operations.
Finally, message-driven beans allow functionality to be executed on an
asynchronous basis, typically triggered by JMS messages from message-oriented
middleware.
What is the Java Message Service (JMS)?JMS is Java API that presents an
interface into message-oriented middleware such as IBM MQSeries, SonicMQ and so
on. Like JDBC, JMS provides Java applications a mechanism to integrate with such
systems by presenting a common programming interface irrespective of the
underlying messaging system. Functionally, JMS allows messages to be sent and
received using a point-to-point or publish/subscribe paradigm.
The steps to running a J2EE application - build, package and
deploymentThere are several steps involved with building and running a J2EE
application. The first step is to build it. J2EE is now supported by many
tools (both commercial and open source) and these can certainly be useful in
removing some of the complexity involved during the development process.
Once you have built your application, the next step is to package it
up. Here, the type of J2EE component you have used will determine how you
package up your application. At a high level though, this is really just a
matter of bundling up all of your components and classes into an archive (for
example JAR) file. In addition to your compiled code, some of the
characteristics associated with certain components need to be configured using
deployment descriptors. These are simply XML files that describe the way that
the component will behave when running within the J2EE environment.
The final step in the process is called deployment. Since J2EE is, in
essence, a collection of APIs and specifications, it is necessary to install an
application server - the software that implements these specifications and
provides the services that your J2EE components rely upon to run.
Where do I get an application server from?There are many commercial
application servers available on the market, including BEA WebLogic,
IBM Websphere, Oracle 9i Application
Server and so on. There are also some excellent open source implementations
available such as JBoss. Finally, for
non-commercial uses, the J2EE development kit is available free of charge. This
is Sun Microsystems' reference implementation of the J2EE specifications, meant
specifically for the development, testing and non-commercial deployment of J2EE
applications.
If you only plan to use Java Servlets and JSPs...
If you
are only planning on writing web-based applications using Java Servlets
and JSP, it's not strictly necessary that you need to run a full J2EE
application server. Many application server vendors supply cut-down
implementations that only support servlets and JSP and there are also many
open source implementations available too, with one of the most popular
being Tomcat. This is the reference implementation of the Java Servlet and
JSP specifications, and is available to download from the Jakarta site.
|
How do I get started with J2EE?
Step 1 : Install the JDKThe first thing that you'll need to get started
with J2EE is the regular Java Development Kit (JDK). Ideally, you should try to
get the latest version that you can to ensure the best compatibility and absence
of bugs. Currently, this is version 1.4.1 and is available to download from the J2SE downloads page.
Step 2 : Install the J2EE SDKNext you'll need an application server so
that you can run your J2EE applications. The J2EE development kit (J2EE SDK)
which is currently at version 1.3.1 can be downloaded from the J2EE downloads page.
How do I run the J2EE SDK on Microsoft Windows 95/98/Me?
With respect to Microsoft Windows, although the J2EE SDK is designed
to run on NT/2000/XP, it can successfully be run on other versions such as
95/98 and Me. Take a look at this
thread on the Java Developer Connection for detailed information.
|
Step 3 : Start the J2EE serverFor the purposes of illustrating how to
start up the J2EE server, let's assume that you're using a Microsoft Windows
platform and have installed the JDK into c:\j2sdk1.4.1, and the
J2EE SDK into c:\j2sdkee1.3.1. To start the J2EE server, open up
command window and type the following:
set JAVA_HOME=c:\j2sdk1.4.1
set J2EE_HOME=c:\j2sdkee1.3.1
cd %J2EE_HOME%\bin
j2ee -verbose After a short delay and a few messages,
you should see "J2EE server startup complete".
Step 4 : Start the J2EE deployment toolNow that the J2EE server is up
and running, the next thing to do is to start the deployment tool. Once you have
built a J2EE application, this is the tool that you use to deploy it into the
J2EE server. To run the deployment tool, open up another command window and type
the following:
set JAVA_HOME=c:\j2sdk1.4.1
set J2EE_HOME=c:\j2sdkee1.3.1
cd %J2EE_HOME%\bin
deploytool After a short delay you should see a
splash screen followed shortly afterwards by the main application window.
Step 5 : Test the installationA useful, final step that we can perform
is to test that everything is working correctly by pointing a web browser to http://localhost:8000/index.html. If
successful, you'll see the J2EE server home page indicating that everything is
working okay. At this stage you're now ready to start building and running J2EE
applications.
Where can I find more information about J2EE?The J2EE home page is a good place to start, as
is TheServerSide.com and, of course,
if you have a specific question, don't forget to join us over at the JavaRanch
J2EE and EJB forum. Also, take a look at the J2EE section of The
Bunkhouse for a list of related books, reviews and recommendations.
Another good starting point for building J2EE applications is the J2EE
tutorial, covering how to get started writing Java Servlets, JSPs, EJBs and
other J2EE components.
SummaryThe J2EE is a very comprehensive platform and at first the range
of technologies and APIs can seem daunting. By building up your knowledge of
J2EE piece by piece, technology by technology, you'll soon be a good position to
start designing and building J2EE systems. Next month we'll start our tour of
the various J2EE technologies by taking a closer look at the web tier (Java
Servlets and JSP) including a discussion of how they fit in to the J2EE, how
Java Servlets and JSP coexist and also the sort of things that they are both
capable of.
Return to Top
|
Equals and Hash Code
Author: Manish Hatwalne
Introduction
The Java super class java.lang.Object has two very important methods defined in it. They
are -
public boolean equals(Object obj)
public int hashCode()
These methods prove very important when user classes are confronted with other Java classes, when objects of
such classes are added to collections etc. These two methods have become part of Sun Certified Java Programmer
1.4 exam (SCJP 1.4) objectives. This article intends to provide the necessary information about these two methods
that would help the SCJP 1.4 exam aspirants. Moreover, this article hopes to help you understand the mechanism
and general contracts of these two methods; irrespective of whether you are interested in taking the SCJP 1.4 exam
or not. This article should help you while implementing these two methods in your own classes.
public boolean equals(Object obj)
This method checks if some other object passed to it as an argument is equal to the object on which this
method is invoked. The default implementation of this method in Object class simply checks if two
object references x and y refer to the same object. i.e. It checks if x == y. This particular comparison
is also known as "shallow comparison". However, the classes providing their own implementations of the
equals method are supposed to perform a "deep comparison"; by actually comparing the relevant
data members. Since Object class has no data members that define its state, it simply performs shallow
comparison.
This is what the JDK 1.4 API documentation says about the equals method of Object class-
Indicates whether some other object is "equal to" this
one.
The equals method implements an equivalence relation:
- It is reflexive: for any reference value x, x.equals(x) should return true.
- It is symmetric: for any reference values x and y, x.equals(y) should return true if and
only if y.equals(x) returns true.
- It is transitive: for any reference values x, y, and z, if x.equals(y) returns true and y.equals(z)
returns true, then x.equals(z) should return true.
- It is consistent: for any reference values x and y, multiple invocations of x.equals(y) consistently
return true or consistently return false, provided no information used in equals comparisons on the object is modified.
- For any non-null reference value x, x.equals(null) should return
false.
The equals method for class Object implements the most discriminating
possible equivalence relation on objects; that is, for any reference values x and y, this method returns true if
and only if x and y refer to the same object (x==y has the value true).
Note that it is generally necessary to override the hashCode method whenever this method is overridden, so as to
maintain the general contract for the hashCode method, which states that equal objects must have equal hash codes.
The contract of the equals method precisely states what it requires. Once you understand it completely,
implementation becomes relatively easy, moreover it would be correct. Let's understand what each of this really
means.
- Reflexive - It simply means that the object must be equal to itself, which it would be at any given
instance; unless you intentionally override the
equals method to behave otherwise.
- Symmetric - It means that if object of one class is equal to another class object, the other class object
must be equal to this class object. In other words, one object can not unilaterally decide whether it is equal
to another object; two objects, and consequently the classes to which they belong, must bilaterally decide if they
are equal or not. They BOTH must agree.
Hence, it is improper and incorrect to have your own class with equals method that has comparison
with an object of java.lang.String class, or with any other built-in Java class for that matter. It
is very important to understand this requirement properly, because it is quite likely that a naive implementation
of equals method may violate this requirement which would result in undesired consequences.
- Transitive - It means that if the first object is equal to the second object and the second object is
equal to the third object; then the first object is equal to the third object. In other words, if two objects agree
that they are equal, and follow the symmetry principle, one of them can not decide to have a similar contract with
another object of different class. All three must agree and follow symmetry principle for various permutations
of these three classes.
Consider this example - A, B and C are three classes. A and B both implement the equals method in
such a way that it provides comparison for objects of class A and class B. Now, if author of class B decides to
modify its equals method such that it would also provide equality comparison with class C; he would
be violating the transitivity principle. Because, no proper equals comparison mechanism would exist
for class A and class C objects.
- Consistent - It means that if two objects are equal, they must remain equal as long as they are not
modified. Likewise, if they are not equal, they must remain non-equal as long as they are not modified. The modification
may take place in any one of them or in both of them.
- null comparison - It means that any instantiable class object is not equal to
null, hence
the equals method must return false if a null is passed to it as an argument.
You have to ensure that your implementation of the equals method returns false if a null
is passed to it as an argument.
- Equals & Hash Code relationship - The last note from the API documentation is very important, it
states the relationship requirement between these two methods. It simply means that if two objects are equal, then
they must have the same hash code, however the opposite is NOT true. This is discussed in details later in this
article.
The details about these two methods are interrelated and how they should be overridden correctly is discussed
later in this article.
public int hashCode()
This method returns the hash code value for the object on which this method is invoked. This method returns
the hash code value as an integer and is supported for the benefit of hashing based collection classes such as
Hashtable, HashMap, HashSet etc. This method must be overridden in every class that overrides the equals
method.
This is what the JDK 1.4 API documentation says about the hashCode method of Object class-
Returns a hash code value for the object. This method is supported
for the benefit of hashtables such as those provided by java.util.Hashtable.
The general contract of hashCode is:
- Whenever it is invoked on the same object more than once during
an execution of a Java application, the hashCode method must consistently return the same integer, provided no
information used in equals comparisons on the object is modified. This integer need not remain consistent from
one execution of an application to another execution of the same application.
- If two objects are equal according to the equals(Object) method,
then calling the hashCode method on each of the two objects must produce the same integer result.
- It is not required that if two objects are unequal according to
the equals(java.lang.Object) method, then calling the hashCode method on each of the two objects must produce distinct
integer results. However, the programmer should be aware that producing distinct integer results for unequal objects
may improve the performance of hashtables.
As much as is reasonably practical, the hashCode method defined by
class Object does return distinct integers for distinct objects. (This is typically implemented by converting the
internal address of the object into an integer, but this implementation technique is not required by the JavaTM programming language.)
As compared to the general contract specified by the equals method, the contract specified by the
hashCode method is relatively simple and easy to understand. It simply states two important requirements
that must be met while implementing the hashCode method. The third point of the contract, in fact
is the elaboration of the second point. Let's understand what this contract really means.
- Consistency during same execution - Firstly, it states that the hash code returned by the
hashCode
method must be consistently the same for multiple invocations during the same execution of the application as long
as the object is not modified to affect the equals method.
- Hash Code & Equals relationship - The second requirement of the contract is the
hashCode
counterpart of the requirement specified by the equals method. It simply emphasizes the same relationship
- equal objects must produce the same hash code. However, the third point elaborates that unequal objects need
not produce distinct hash codes.
After reviewing the general contracts of these two methods, it is clear that the relationship between these
two methods can be summed up in the following statement -
Equal objects must produce the same hash code as long as they are equal, however unequal objects need not
produce distinct hash codes.
The rest of the requirements specified in the contracts of these two methods are specific to those methods and
are not directly related to the relationship between these two methods. Those specific requirements are discussed
earlier. This relationship also enforces that whenever you override the equals method, you must override
the hashCode method as well. Failing to comply with this requirement usually results in undetermined,
undesired behavior of the class when confronted with Java collection classes or any other Java classes.
Correct Implementation Example
The following code exemplifies how all the requirements of equals and hashCode methods
should be fulfilled so that the class behaves correctly and consistently with other Java classes. This class implements
the equals method in such a way that it only provides equality comparison for the objects of the same
class, similar to built-in Java classes like String and other wrapper classes.
1. public class Test
2. {
3. private int num;
4. private String data;
5.
6. public boolean equals(Object obj)
7. {
8. if(this == obj)
9. return true;
10. if((obj == null) || (obj.getClass() != this.getClass()))
11. return false;
12. // object must be Test at this point
13. Test test = (Test)obj;
14. return num == test.num &&
15. (data == test.data || (data != null && data.equals(test.data)));
16. }
17.
18. public int hashCode()
19. {
20. int hash = 7;
21. hash = 31 * hash + num;
22. hash = 31 * hash + (null == data ? 0 : data.hashCode());
23. return hash;
24. }
25.
26. // other methods
27. }
Now, let's examine why this implementation is the correct implementation. The class Test has two member variables
- num and data. These two variables define state of the object and they also participate
in the equals comparison for the objects of this class. Hence, they should also be involved in calculating
the hash codes of this class objects.
Consider the equals method first. We can see that at line 8, the passed object reference is compared
with this object itself, this approach usually saves time if both the object references are referring
to the same object on the heap and if the equals comparison is expensive. Next, the if condition at
line 10 first checks if the argument is null, if not, then (due to the short-circuit nature of the
OR || operator) it checks if the argument is of type Test by comparing the classes of
the argument and this object. This is done by invoking the getClass() method on both the references.
If either of these conditions fails, then false is returned. This is done by the following code -
if((obj == null) || (obj.getClass() != this.getClass()))
return false; // prefer
This conditional check should be preferred instead of the conditional check given by -
if(!(obj instanceof Test)) return false; // avoid
This is because, the first condition (code in blue) ensures that it will return false if the argument
is a subclass of the class Test. However, in case of the second condition (code in red) it fails.
The instanceof operator condition fails to return false if the argument is a subclass
of the class Test. Thus, it might violate the symmetry requirement of the contract. The instanceof
check is correct only if the class is final, so that no subclass would exist. The first condition
will work for both, final and non-final classes. Note that, both these conditions will return false
if the argument is null. The instanceof operator returns false if the left
hand side (LHS) operand is null, irrespective of the operand on the right hand side (RHS) as specified
by JLS
15.20.2. However, the first condition should be preferred for better type checking.
This class implements the equals method in such a way that it provides equals comparison only for
the objects of the same class. Note that, this is not mandatory. But, if a class decides to provide equals comparison
for other class objects, then the other class (or classes) must also agree to provide the same for this class so
as to fulfill the symmetry and reflexivity requirements of the contract. This particular equals method
implementation does not violate both these requirements. The lines 14 and 15 actually perform the equality comparison
for the data members, and return true if they are equal. Line 15 also ensures that invoking the equals
method on String variable data will not result in a NullPointerException.
While implementing the equals method, primitives can be compared directly with an equality operator
(==) after performing any necessary conversions (Such as float to Float.floatToIntBits
or double to Double.doubleToLongBits). Whereas, object references can be compared by invoking their
equals method recursively. You also need to ensure that invoking the equals method on
these object references does not result in a NullPointerException.
Here are some useful guidelines for implementing the equals method correctly.
- Use the equality
== operator to check if the argument is the reference to this object, if yes.
return true. This saves time when actual comparison is costly.
- Use the following condition to check that the argument is not
null and it is of the correct type,
if not then return false.
if((obj == null) || (obj.getClass() != this.getClass())) return false;
Note that, correct type does not mean the same type or class as shown in the example above. It could be any class
or interface that one or more classes agree to implement for providing the comparison.
- Cast the method argument to the correct type. Again, the correct type may not be the same class. Also, since
this step is done after the above type-check condition, it will not result in a
ClassCastException.
- Compare significant variables of both, the argument object and this object and check if they are equal. If
*all* of them are equal then return true, otherwise return false. Again, as mentioned earlier, while comparing
these class members/variables; primitive variables can be compared directly with an equality operator (
==)
after performing any necessary conversions (Such as float to Float.floatToIntBits or double to Double.doubleToLongBits).
Whereas, object references can be compared by invoking their equals method recursively. You also need
to ensure that invoking equals method on these object references does not result in a NullPointerException,
as shown in the example above (Line 15).
It is neither necessary, nor advisable to include those class members in this comparison which can be calculated
from other variables, hence the word "significant variables". This certainly improves the performance
of the equals method. Only you can decide which class members are significant and which are not.
- Do not change the type of the argument of the
equals method. It takes a java.lang.Object
as an argument, do not use your own class instead. If you do that, you will not be overriding the equals
method, but you will be overloading it instead; which would cause problems. It is a very common mistake, and since
it does not result in a compile time error, it becomes quite difficult to figure out why the code is not working
properly.
- Review your
equals method to verify that it fulfills all the requirements stated by the general
contract of the equals method.
- Lastly, do not forget to override the
hashCode method whenever you override the equals
method, that's unpardonable. ;)
Now, let's examine the hashCode method of this example. At line 20, a non-zero constant value 7
(arbitrary) is assigned to an int variable hash. Since the class members/variables num
and data do participate in the equals method comparison, they should also be involved
in the calculation of the hash code. Though, this is not mandatory. You can use subset of the variables that participate
in the equals method comparison to improve performance of the hashCode method. Performance
of the hashCode method indeed is very important. But, you have to be very careful while selecting
the subset. The subset should include those variables which are most likely to have the greatest diversity of the
values. Sometimes, using all the variables that participate in the equals method comparison for calculating
the hash code makes more sense.
This class uses both the variables for computing the hash code. Lines 21 and 22 calculate the hash code values
based on these two variables. Line 22 also ensures that invoking hashCode method on the variable data
does not result in a NullPointerException if data is null. This implementation
ensures that the general contract of the hashCode method is not violated. This implementation will
return consistent hash code values for different invocations and will also ensure that equal objects will have
equal hash codes.
While implementing the hashCode method, primitives can be used directly in the calculation of the
hash code value after performing any necessary conversions, such as float to Float.floatToIntBits
or double to Double.doubleToLongBits. Since return type of the hashCode method is int,
long values must to be converted to the integer values. As for hash codes of the object references, they should
be calculated by invoking their hashCode method recursively. You also need to ensure that invoking
the hashCode method on these object references does not result in a NullPointerException.
Writing a very good implementation of the hashCode method which calculates hash code values such that
the distribution is uniform is not a trivial task and may require inputs from mathematicians and theoretical computer
scientist. Nevertheless, it is possible to write a decent and correct implementation by following few simple rules.
Here are some useful guidelines for implementing the hashCode method correctly.
- Store an arbitrary non-zero constant integer value (say 7) in an
int variable, called hash.
- Involve significant variables of your object in the calculation of the hash code, all the variables that are
part of equals comparison should be considered for this. Compute an individual hash code
int var_code
for each variable var as follows -
- If the variable
(var) is byte, char, short or int, then var_code
= (int)var;
- If the variable
(var) is long, then var_code = (int)(var ^ (var >>>
32));
- If the variable
(var) is float, then var_code = Float.floatToIntBits(var);
- If the variable
(var) is double, then -
long bits = Double.doubleToLongBits(var);
var_code = (int)(bits ^ (bits >>> 32));
- If the variable
(var) is boolean, then var_code = var ? 1 : 0;
- If the variable
(var) is an object reference, then check if it is null, if yes then
var_code = 0; otherwise invoke the hashCode method recursively on this object reference
to get the hash code. This can be simplified and given as -
var_code = (null == var ? 0 : var.hashCode());
- Combine this individual variable hash code
var_code in the original hash code hash
as follows -
hash = 31 * hash + var_code;
- Follow these steps for all the significant variables and in the end return the resulting integer
hash.
- Lastly, review your
hashCode method and check if it is returning equal hash codes for equal objects.
Also, verify that the hash codes returned for the object are consistently the same for multiple invocations during
the same execution.
The guidelines provided here for implementing equals and hashCode methods are merely
useful as guidelines, these are not absolute laws or rules. Nevertheless, following them while implementing these
two methods will certainly give you correct and consistent results.
Summary & Miscellaneous Tips
- Equal objects must produce the same hash code as long as they are equal, however unequal objects need not produce
distinct hash codes.
- The
equals method provides "deep comparison" by checking if two objects are logically
equal as opposed to the "shallow comparison" provided by the equality operator ==.
- However, the
equals method in java.lang.Object class only provides "shallow
comparison", same as provided by the equality operator ==.
- The
equals method only takes Java objects as an argument, and not primitives; passing primitives
will result in a compile time error.
- Passing objects of different types to the
equals method will never result in a compile time error
or runtime error.
- For standard Java wrapper classes and for
java.lang.String, if the equals argument
type (class) is different from the type of the object on which the equals method is invoked, it will
return false.
- The class
java.lang.StringBuffer does not override the equals method, and hence it
inherits the implementation from java.lang.Object class.
- The
equals method must not provide equality comparison with any built in Java class, as it would
result in the violation of the symmetry requirement stated in the general contract of the equals method.
- If
null is passed as an argument to the equals method, it will return false.
- Equal hash codes do not imply that the objects are equal.
return 1; is a legal implementation of the hashCode method, however it is a very
bad implementation. It is legal because it ensures that equal objects will have equal hash codes, it also ensures
that the hash code returned will be consistent for multiple invocations during the same execution. Thus, it does
not violate the general contract of the hashCode method. It is a bad implementation because it returns
same hash code for all the objects. This explanation applies to all implementations of the hashCode
method which return same constant integer value for all the objects.
- In standard JDK 1.4, the wrapper classes
java.lang.Short, java.lang.Byte, java.lang.Character
and java.lang.Integer simply return the value they represent as the hash code by typecasting it to
an int.
- Since JDK version 1.3, the class
java.lang.String caches its hash code, i.e. it calculates the
hash code only once and stores it in an instance variable and returns this value whenever the hashCode
method is called. It is legal because java.lang.String represents an immutable string.
- It is incorrect to involve a random number directly while computing the hash code of the class object, as it
would not consistently return the same hash code for multiple invocations during the same execution.
Resources
Here is a list of few more resources that might be useful if you are interested in knowing more about these
two methods, their implementation and significance.
- Object class - API
documentation for the
java.lang.Object class. The general contract of these two methods is available
here.
- Effective
Java - Nice book by Joshua Bloch. Chapter 3 of this book is available online in a
pdf format.
This chapter deals with all the methods of java.lang.Object class. It also discusses in details the
implementation of equals and hashCode methods, correct and incorrect way of overriding
them etc. This article is partially based on the information given in this book.
However, this article is an attempt to explain the mechanism and implementation details of these two methods in
a simple and compact presentation. It also adds tips and review questions for better understanding.
- JavaWorld Article
- This article discusses the methods of java.lang.Object, also explains shortcomings of using the instanceof condition
in the equals method.
- Importance of
equals and
hashCode - This FAQ question discusses the importance of overriding equals and hashCode
methods correctly. It also discusses important issues regarding these two methods with respect to Java collection
framework.
- Equals & Hash Code Mock Test - If you are interested in
taking the mock test featured here under review questions separately.
This article has been reviewed and revised repeatedly so as to make it as correct as possible. Thanks a
lot to Valentin Crettaz and friends at JavaRanch for suggesting
many changes. Especially thanks to Valentin for pointing out the violation of the symmetry requirement by using
the instanceof condition in the equals method. If you notice any ambiguity, error in
the article and/or the mock test, please do let me know. Your feedback is very important in making this article
and test more useful.
Return to Top
|
Small Worlds 2.0
a dependency analyzer by Information Laboratory, Inc.
by: Ilja Preuss
Small Worlds is
a tool for exploring and analyzing dependencies in object oriented software
systems. It promises to "help prevent [...] failures by allowing managers,
engineers, developers, and testers to gain critical understanding of stability
issues in their systems" by "performing a structural analysis, evaluating the
overall stability, and pointing out potentially problematic areas". It even
claims giving managers the ability to assess the maintainability of a system
without having to know anything about programming.
To investigate the meat behind those claims, I used Small Worlds Analyzer
Edition 2.0 for Java, provided by Information Laboratory. There is also a
version for C++ and a shortened Visualizer Edition. I mainly analyzed an open source project,
first because there is no problem with publishing details about it, and second
because I am very familiar with the code and therefore in a good position to
judge the findings of the tool. The project consisted of 94 classes/interfaces
in 12 packages forming a net of 386 relationships. I also took a quick shot at
two bigger projects, one of around 600, one of over 1000 "objects".
Installation
Installation went very smoothly. After downloading and starting the setup
program for Windows, I only had to enter the registration key. That was it. The
registration key is bound to the MAC address of the installation machine, so you
have to get a new key if you find yourself needing to replace the network
adapter. As the folks of Information Laboratory seem to be very responsive in
general, that probably shouldn't be much of an issue.
Setting up a project
After starting the program, you are welcomed by a project wizard. It gives
you the option to either open a recently worked on project or start a new
one.
Small Worlds works on class files, so you don't need the sources of the
project. The files can reside either in jar- or zip-files or in a directory
structure (or any combination of the three). It also wants to know the location
of the used external libraries. Optionally, you can configure the location of
source- and javadoc-files. These aren't used in the analysis, but can be viewed
from the explorer.
First exploration
After loading the class files, you get to the Application Guide. This guide
presents the six main parts of the tool, giving a short description and the
option to get more information on a part or to Launch a particular one. The
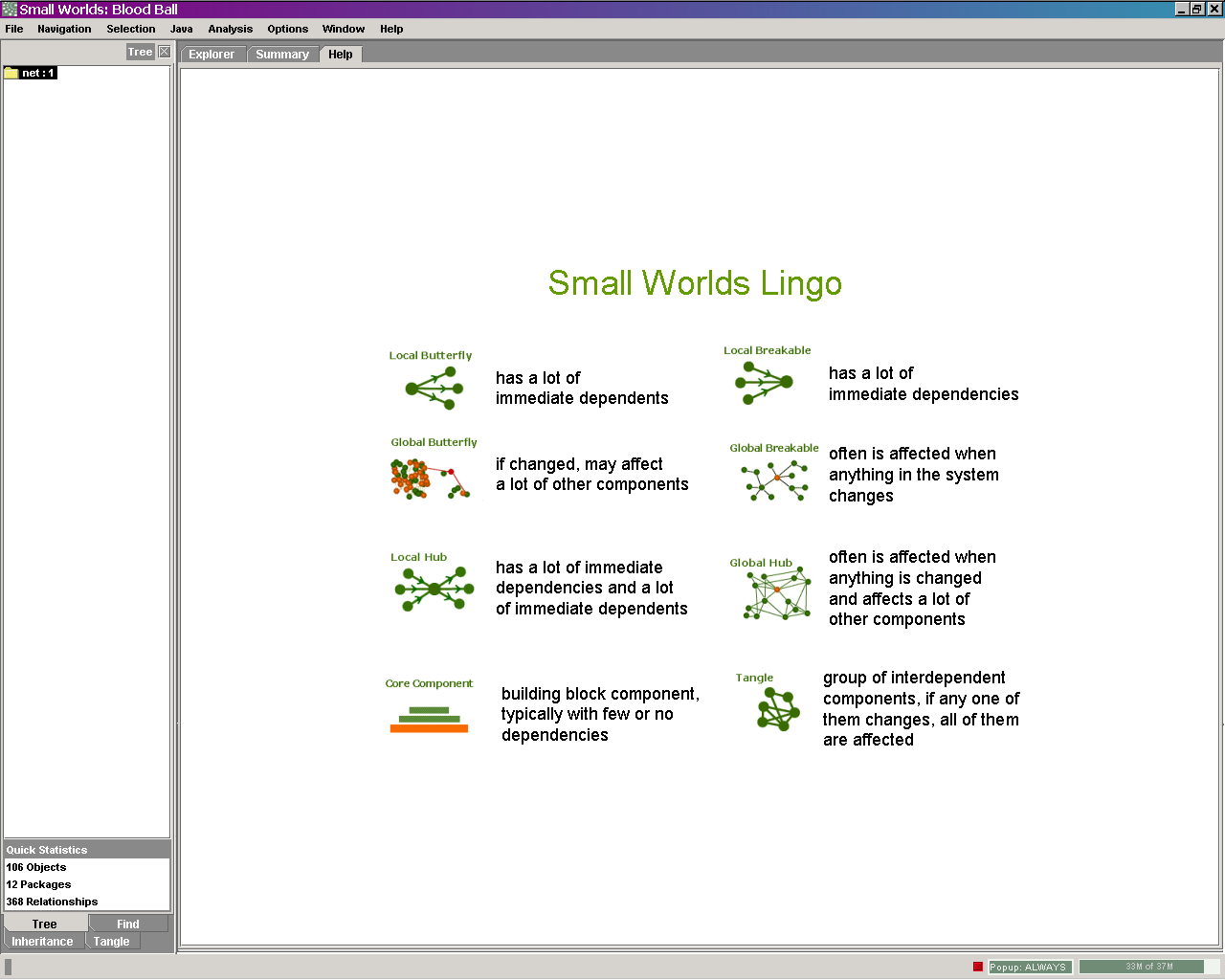
first is the Explorer, used to "navigate through software as a web of
relationships". (The segmentation into those parts is only done for the
convenience of the beginner - they are integrated rather seamlessly and you will
later switch between them without even noticing.)
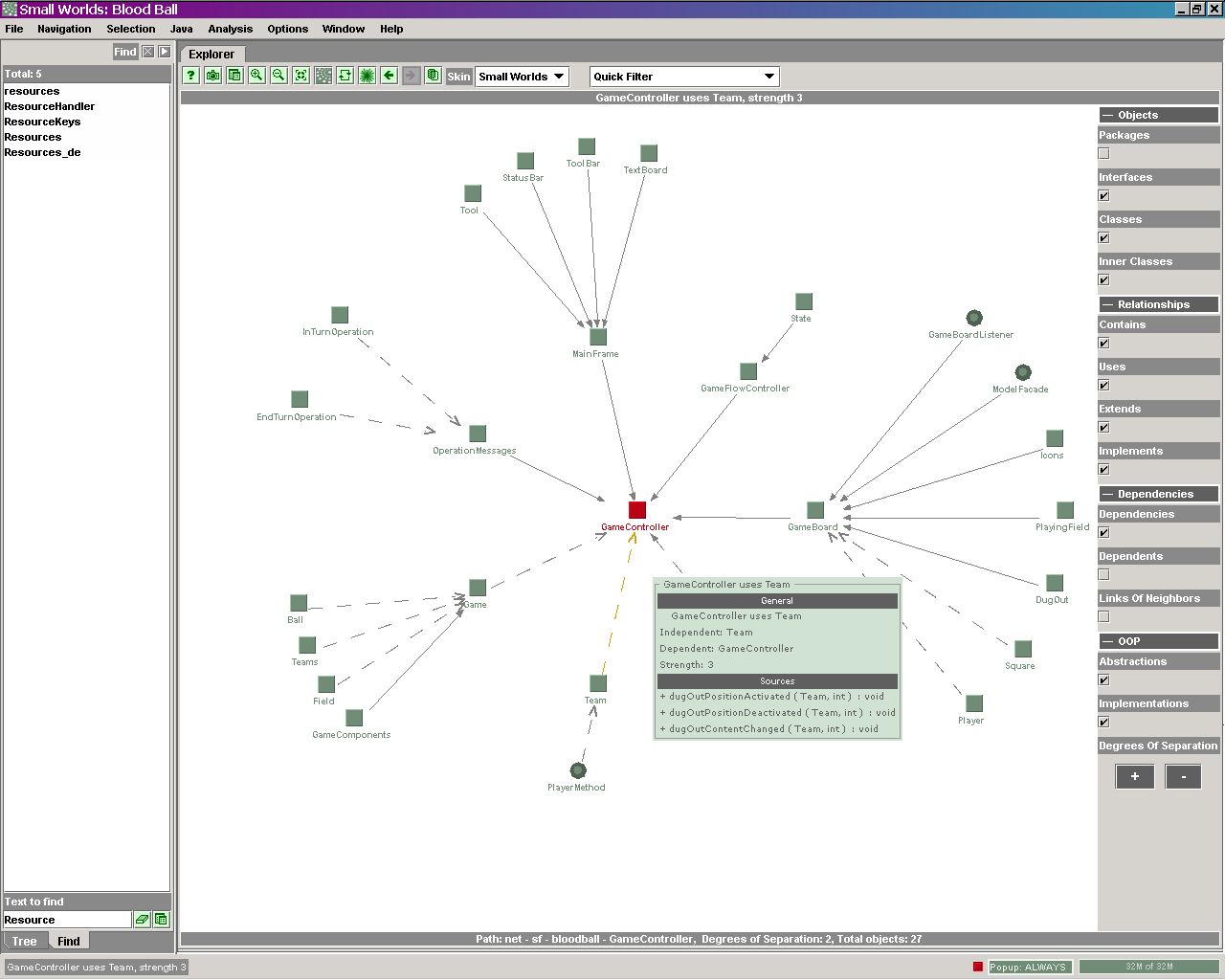
The 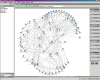 Explorer can best be described as an interactive form of a simplified UML class
diagram. There is always one entity (class, interface or package) at the center
of the screen, surrounded by its dependants and entities it depends on. The type
and level of dependencies shown can be configured in detail -
Explorer can best be described as an interactive form of a simplified UML class
diagram. There is always one entity (class, interface or package) at the center
of the screen, surrounded by its dependants and entities it depends on. The type
and level of dependencies shown can be configured in detail - 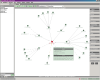 which is necessary because showing all dependencies can quickly produce a
complex, useless mess. After fiddling with the settings a little bit, we can
finally get a usable view, for example focused on incoming dependencies. There
are also some Quick Filters predefined for typical configurations. If you hover
the mouse cursor over an entity, a window containing detailed information pops
up.
which is necessary because showing all dependencies can quickly produce a
complex, useless mess. After fiddling with the settings a little bit, we can
finally get a usable view, for example focused on incoming dependencies. There
are also some Quick Filters predefined for typical configurations. If you hover
the mouse cursor over an entity, a window containing detailed information pops
up.
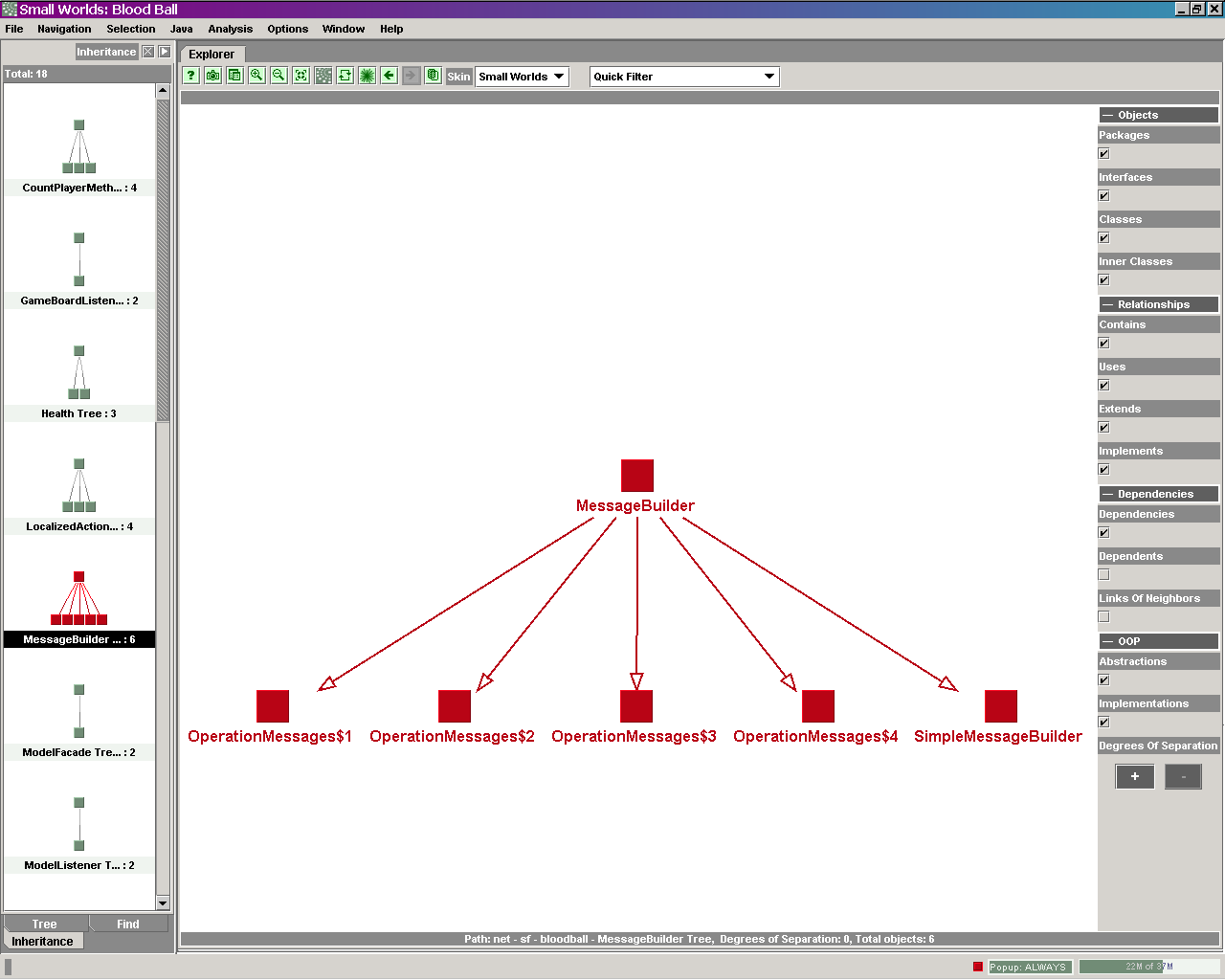
By  clicking on an entity, that entity gets centered in the view. This
way you can browse through the system step by step. There are also predefined
views on specific aspects of the system, for example all the existing
inheritance relationsships. Unnecessary to mention that you can also search for
a specific entity by name. clicking on an entity, that entity gets centered in the view. This
way you can browse through the system step by step. There are also predefined
views on specific aspects of the system, for example all the existing
inheritance relationsships. Unnecessary to mention that you can also search for
a specific entity by name.
The analysis Summary
Probably  the most important part of the Analyzer Edition is the Summary.
the most important part of the Analyzer Edition is the Summary.  The Summary is a textual description of the
system, giving you some general statistics and pointing out potential problems,
linked to sections containing more information. The types of potential problems
Small Worlds analyses are tersely described in the help system. The Summary is a textual description of the
system, giving you some general statistics and pointing out potential problems,
linked to sections containing more information. The types of potential problems
Small Worlds analyses are tersely described in the help system.
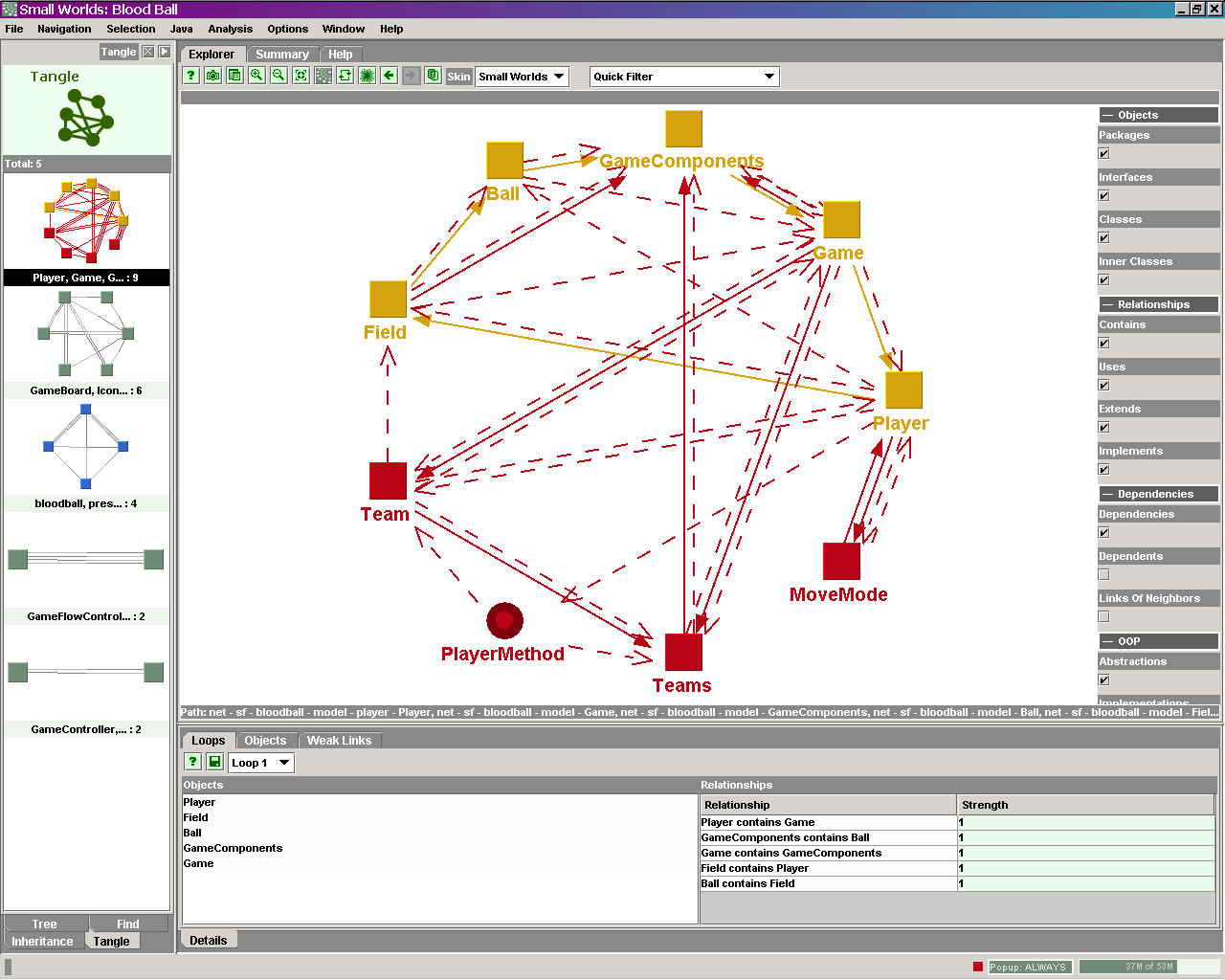
Let's take a look at a tangle (a tangle is a group of entities with circular
dependencies). After clicking on the link and choosing one of the identified
tangles, the Explorer is showing the tangle. 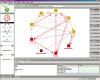 To further analyze it, we can activate the Details
view and highlight a specific circular dependency. To further analyze it, we can activate the Details
view and highlight a specific circular dependency.
What now?
OK, certainly a tangle is a bad thing. But what do we do about it? This is
were Small Worlds seems to let us down. Neither in the online help, nor in the
manual did I find any advice on how to break a tangle. Finally I found a message
in the Small
Worlds forum, promptly and concisely answered by the support team, as seems
to be generally the case. It explains that you should find the dependency that
doesn't make sense (where a simple concept depends on a more complex one, for
example - hopefully a weak dependency) and remove it. Sadly, it doesn't give any
hints on how such a dependency might be broken - though I suspect you would get
an equally concise answer if you asked (probably pointing out something along
the lines of the Dependency Inversion Principle).
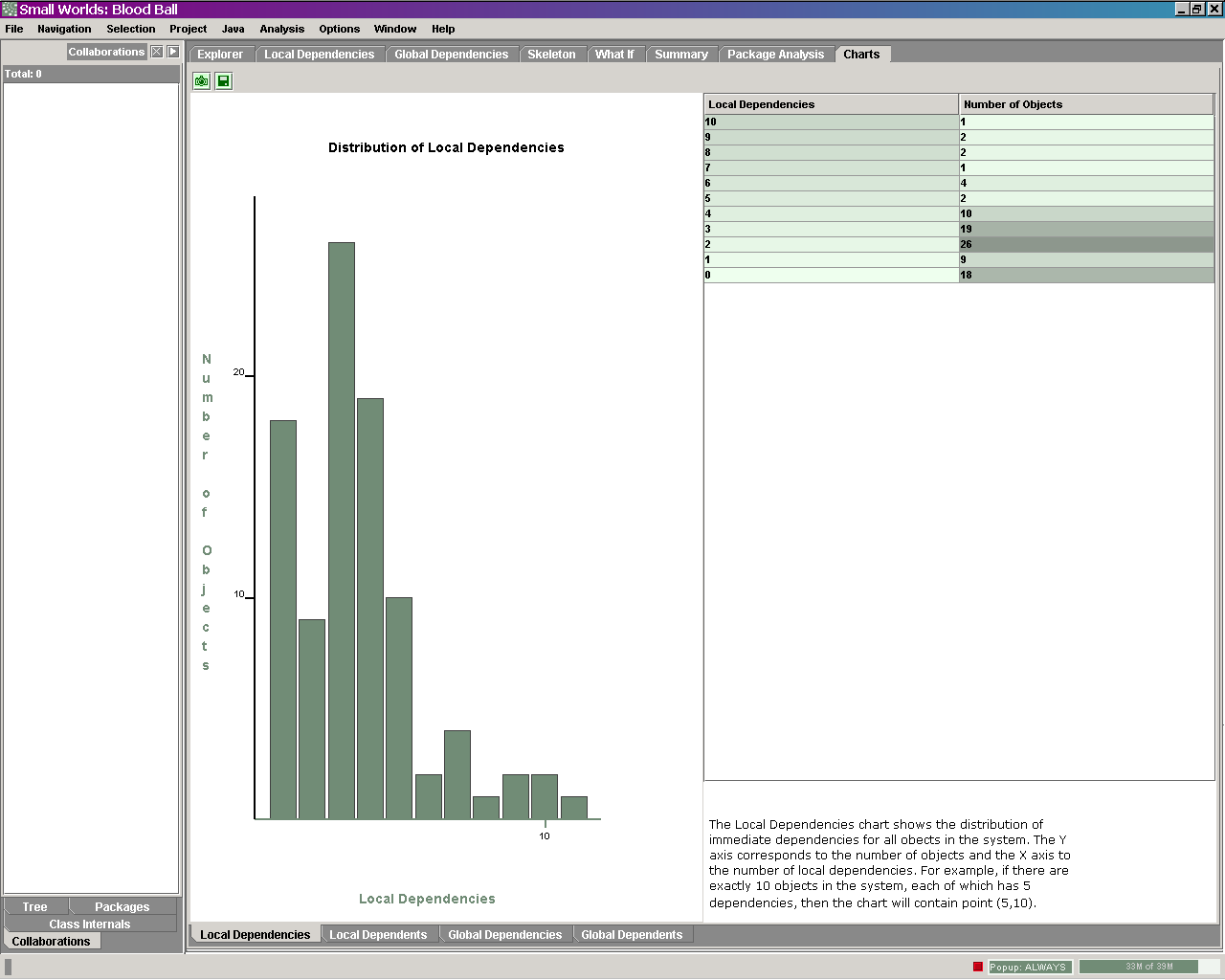
Other metrics and views
Small 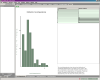 Worlds also provides a whole bunch of other, more conventional metrics like
instability, abstractness and imbalance (distance from the main sequence) of
packages. The program thereby colors the values by potential criticality and
makes it easy to spot entities demanding special attention. Some of the metrics
can also be portrayed in statistical charts.
Worlds also provides a whole bunch of other, more conventional metrics like
instability, abstractness and imbalance (distance from the main sequence) of
packages. The program thereby colors the values by potential criticality and
makes it easy to spot entities demanding special attention. Some of the metrics
can also be portrayed in statistical charts.
If you want to share the above metrics and the Summary with your colleagues
without having them to crowd around your monitor, you can save every screen as
HTML and/or GIF file as appropriate or even create a whole hyperlinked HTML-report.
Another interesting view is the Skeleton view. It shows the "dependency
hierarchy" of the system in a form of a pyramid - the entities with only
outgoing dependencies on the bottom, those with only incoming dependencies on
the top. Ideally, this view actually shows you a triangle - major deviation from
this shape can point out problems in the design. Tangles, butterflies etc. can
be specially colored (as can be done in the explorer). You can also highlight
the dependants of an entity by clicking on it.
For the latter there is even another specific view called "What If". Here the
classes and interfaces are grouped by packages. If you click on an entity, a
simple animation is started, connecting it to all its dependants, thereby
showing you the potential effects of a change in that entity.
Something missing?
The information Small Worlds presents is quite voluminous and might even be
overwhelming at the beginning. Nevertheless there are some things, Small Worlds
won't tell you.
For example, Small Worlds gave the above mentioned "middle sized" system a
stability rating of 94%, though I experienced it to be rather hard to maintain
and extend. This was because of a lot of indirect coupling, like one class
expecting another class to organize an array in a specific way. Those
dependencies aren't considered by Small Worlds, and would probably be very hard
to.
There are also other, more "mechanical" design heuristics Small Worlds
currently doesn't take into account, like the Law Of Demeter.
Another request from the forum is analysis on the method level in addition to
the current class/interface/package levels.
Besides this, Small Worlds also doesn't record the history of a project. So,
if you want to know how some metrics changed while the design evolved, you need
to keep track of that in some other way.
Fortunately, the folks at Information Laboratory seem to be fully aware of
these issues, so that we can look forward to upcoming releases. There are talks
about promising features like refactoring wizards, history tracking with
visualization of structural changes and charts for metrics through the lifetime
of a project.
Conclusion
Small Worlds is certainly a very powerful design analysis tool. The
information it presents will give you much to think about and might highlight
critical problems you weren't previously aware of.
But you shouldn't expect it to do your work for you (as you shouldn't expect
from any tool). You still need to interpret the information in the light of your
situation and find the right ways to act accordingly.
Therefore I don't think this tool could or should replace a manager's trust
in the development team or the extensive care for new team members. An
introduction by Pair Programming, accompanied with some high-level class
diagrams on the white board will still be way more effective than browsing in
the Small Worlds Explorer in most situations.
If you are aware of these social and technical limitations, Small Worlds can
without doubt be a very effective tool for analyzing and teaching specific
critical design aspects in your object oriented projects. (Ilja Preu? -
bartender, October 2002)
Resources
The Small Worlds homepage: http://www.thesmallworlds.com/
OO design principles for managing dependencies: http://c2.com/cgi/wiki?OoDesignPrinciples
Return to Top
|
Book Review of the Month
Mr. Bunny's Big Cup o' Java
by Carlton Egremont III
|

|


|
This book is the story of Farmer Jake's quest to learn Java from his mentor, Mr. Bunny. The book starts at the beginning. This is about the last thing it has in common with other Java books (until it gets to the end).
Farmer Jake and Mr. Bunny are sucked into the computer, tokenized, put in a jar, and find themselves facing the Java Class Verifier (in the person of Telly the Bridge Troll). After passing inspection, they go on to meet Inky (a Squid-based implementation of the Java Virtual Machine). Along the way they meet many other characters that teach them about Primitives, Applets, Classes, Objects, Inheritance, the Garbage Collection, Interfaces, and even the Java Native Interface.
So much packed into one short book! Even the copyright notice is worth reading. This is an entertaining book, appropriate for readers with any level of Java experience, although greenhorns may not get all the jokes (yet). Most of the allegories and examples are reasonably accurate, technically. The explanation of threads and thread scheduling is particularly good.
If you can only buy one Java book this year, this probably shouldn't be it. But if you can scrape up some extra change from between the cushions of the couch, this would be a great way to spend it.
(Dave Landers - Ranch Hand, September 2002)
More info at Amazon.com
More info at Amazon.co.uk
|
Chosen by Cindy Glass and Madhav Lakkapragada
Return to Top
|
October News
Hey, we've added a Tack Room. No one should be out on the range without their vital JavaRanch supplies. T-shirts, caps, lunch bags, and mugs will keep you ready whether you are out on a cattle drive or just dropping in to the saloon.
 This month's special item is the JavaRanch backpack. No CS major should be caught carrying his books in anything else!
This month's special item is the JavaRanch backpack. No CS major should be caught carrying his books in anything else!
As always JavaRanch is dedicated to providing you with the best source of information on Java Programming and Engineering.
by Thomas Paul
Return to Top
|
Managing Editor: Carl Trusiak
Comments or suggestions for JavaRanch's NewsLetter can be sent to the NewsLetter Staff
For advertising opportunities contact NewsLetter Advertising Staff
|