JLS 15.12 (Method Invocation Expressions) in Plain English
This article aims at giving a more understandable description of what a method invocation expression really is. The Java Language Specification is targeted at people having a certain mathematical background. What we are trying to do here is to explain its content to people having a moderate experience in technical English and willing to get to know Java in a more advanced way without coping with pure maths.
There are a lot of things going on under the hood when methods are invoked. First of all, a method is to be seen as a service a class provides to itself and/or to other classes.
Whenever the compiler encounters a method invocation it has to figure out which method is to be invoked and most importantly where to find its implementation.
To get the ball rolling let's just think of some real-life examples. If we want to order a pizza, we have to call a pizza delivery place and not the immigration office or the hospital. If we want to buy a car, we sure don't go to Starbucks or the train station. Put shortly, we have to find the right place where we are sure we are going to get the service we need.
"we" stands here for the compiler which is in charge of turning the human-readable Java code you have written into bytecode the Java Virtual Machine (JVM) will understand. And that's exactly how we are going to proceed here, we will try to "think" exactly the same way the compiler
does. Trying to figure out what the compiler does and how it works is an excellent exercise not only to gain in-depth knowledge of the compilation process but also to spare development time by recognizing code that will result in compile-time and run-time errors.
The following table shows how this article is organized. In order to keep things pretty much organized the same way as in Section 15.12 of the the Java Language Specification (JLS), we decided to keep the same structure. The first part discusses the three steps performed at compile-time while the second focuses on what is achieved at run-time by the linker and interpreter.
Ok, let's go. Below is a slightly modified version of the method invocation expression given in JLS 15.12:
MethodInvocation:
Identifier (ArgumentListopt)
TypeName . Identifier (ArgumentListopt)
FieldName . Identifier (ArgumentListopt)
Primary . Identifier (ArgumentListopt)
super . Identifier (ArgumentListopt)
ClassName . super . Identifier (ArgumentListopt)
ArgumentList:
Expression
ArgumentList , Expression
|
Although those expressions may seem overly complex, they are not. We can see that the part after the left paranthesis, that is ArgumentListopt), is common to all four cases. By investigating the form BEFORE the left paranthesis, we notice
that we always find an Identifier which may be qualified or not. To qualify a method means that we have a clue of where the method may reside and we want to specify it (with the dot-notation). So, we will look into those six different cases and explain when they are used and what purposes they serve.
Moreover, we are going to illustrate the concepts using the following example which contains at least one sample of each expression given above:
- public class MethodInvocation extends Object{
- public MethodInvocation(){
- }
- public void anInstanceMethod(){
- this.anotherInstanceMethod();
- aStaticMethod("test1");
- Class c = getClass();
- }
- public void anotherInstanceMethod(){
- }
- public static void aStaticMethod(String s){
- }
- public static MethodInvocation getMethodInvocationInstance(){
- return new MethodInvocation();
- }
- public String toString(){
- return super.toString();
- }
- public static void main(String args[]){
- aStaticMethod("test2");
- MethodInvocation.aStaticMethod("test3");
- MethodInvocation mi = getMethodInvocationInstance();
- mi.anotherInstanceMethod();
- getMethodInvocationInstance().anInstanceMethod();
- Runtime.getRuntime().freeMemory();
- System.exit(0);
- }
- }
|
The compiler first has to discover the class --what we called a "place"--
in which the method --what we called a "service"-- we need is defined.
- The first form is the simplest of all and is used to:
- invoke static or non-static methods contained in the same class as the caller method, or
- invoke non-static methods inherited from superclasses.
Identifier is the method name itself. It is a simple name being a valid Java
identifier as explained in
JLS 3.8 Identifiers.
Lines 5, 6, 7, 20 and 22 above show that concept. Lines 5,6 and 20 contain invocations
to methods defined in MethodInvocation whereas line 7 invokes getClass
which is inherited from the superclass Object and line 22 invokes the static method
getMethodInvocationInstance defined in the same class, that is MethodInvocation.
- In the second form, TypeName . Identifier, we say that the invocation of the method
Identifier is qualified. TypeName is in fact the name of the class that contains
the method Identifier. It is easy to see that this form is only used to invoke static methods
and that a compile-time error occurs if TypeName is the name of an interface rather than
a class since interfaces cannot have static methods.
On line 21, we invoke the static method named aStaticMethod defined in the class
MethodInvocation. Note that since the method aStaticMethod is in the same
class as the invocation expression, it has the same functionality as the unqualified invocation on lines 6
and 20.
On line 26, we invoke the static method exit defined in the class System. In
this case, the qualified invocation expression is needed since we have to specify where the method
called exit is to be found, that is in class System.
- In the third form, FieldName . Identifier, the invocation of the method Identifier
is also qualified. FieldName is now the name of a reference to an object (an instance of a class).
The class or interface to search is the declared type of the field named FieldName.
This form is used to invoke a static or non-static method on a specific object.
On line 23, we invoke the non-static method anotherInstanceMethod on the reference mi
of type MethodInvocation.
This invocation form may also be used to invoke a static method and the type of FieldName
will be used to determine the class as it was the case in the second form. This is bad practice as far as
readability and consistence are concerned, though. Basically, one should use the second form to invoke static methods
and the third form to invoke non-static methods.
Note: Readability sure is a matter of personal taste. But the bottom line is that it is much better to
settle for some kind of consistence while coding, that is invoke instance methods declared in the same class using
the keyword this (as on line 5) and invoke static method declared in the same class using the class name (as
on line 21). That way
developers will grasp much more quickly the intent of your code and won't need to search for the place where the
method is declared.
|
- In the fourth form, Primary . Identifier, the invocation of the method Identifier
is qualified as well. Primary is now an expression whose type is used to determine the class or interface
providing the implementation of the method Identifier. This form is only used to invoke non-static
methods.
Line 24 contains two different method invocation expressions. The one on the left side, getMethodInvocationInstance,
is what we call the Primary expression here (you may notice that the method is invoked using the very first form
we have discussed above). Then, the return type of that method (MethodInvocation) is used to determine
the class or interface which provides the implementation of the method on the right side, anInstanceMethod.
Put shortly, getMethodInvocationInstance is invoked and returns an instance of the class
MethodInvocation upon which the method anInstanceMethod will then be invoked.
Be aware that Primary may be a complex expression, that is an expression chain as on line 25. The
most important thing to know is that the evaluation goes from left to right.
- In the fifth form, super . Identifier, Identifier is the name of the method to invoke and it can be found
in the superclass of the class containing the invocation. This form is used to invoke static and non-static
methods defined in the superclass of the class containing the invocation.
From this, we can logically derive that two error cases may arise, namely when the class containing the invocation is the
class Object (Object has no superclass) or when the invocation is contained within an interface
(interfaces do not contain any implementation).
Why do we need this invocation pattern if methods (except private) are inherited anyway? Well, the case may arise
where you may want to override (an instance method) or hide (a static method) declared in the superclass in order to
provide your class with a more specific behavior.
Line 16 to 18 show the concept. The class MethodInvocation contains an overridden declaration of the
toString method originally declared in class Object. But for now we are happy with the default
implementation of method toString and decide to rely on the behavior provided by class Object
until our needs evolve. Thus, we invoke toString of class Object using the prefix
super and return the result.
As a rule of thumb, as soon as you override and/or hide a method and you want to invoke the overridden/hidden method,
you'll need to prefix the method name with super.. This way you bypass the overriding method
in your class.
- The last form, ClassName . super . Identifier, is used when dealing with inner
classes. The name of the method is Identifier and it is to be found in the superclass
of the class ClassName. The next requirement is that ClassName MUST be a
lexically enclosing class of the class containing the invocation (in brief it means that the
class containing the invocation is a member class of ClassName,
see JLS 8.1.2),
otherwise a compile-time error occurs. A compile-time error occurs as well if the class in which
the invocation occurs is
Object or an interface (for the same reason stated in the
fifth form).
The goal of this first step was to determine the class or interface which contains the method to invoke.
Now that we know exactly where to search we have to look for the right method to invoke. This is done in the
second step where we will investigate which method signature fits best the invocation expression.
In the rest of this article, we will use the same code examples as in the JLS.
The choice of the right method is based on the method descriptor.
Note:
Method signature? Method descriptor? What are they? The method signature is composed of the method name
and the parameter list (ordered!). The method descriptor takes the method signature AND the return type.

|
This step consists of two sub-steps:
- we have to find the method declarations that are both applicable and
accessible
- we have to find the most specific method since several method declarations may meet the
previous requirement.
Two conditions must be met for a method declaration to be applicable:
- the number of arguments in the method invocation expression MUST be the same as the number
of parameters in the method declaration.
That is, if the method you want to invoke declares having 3 parameters, you have to provide
3 arguments.
- the type of each actual argument can be converted to the type of the corresponding parameters.
That means that you cannot provide a double if a String is required,
for instance.
Conversion issues are discussed in the sections
5.2
(Assignment Conversion) and
5.3
(Method Invocation Conversion) of the JLS.
The class or interface we found in the previous step as well as all its superclasses and superinterfaces
are searched for all method declarations applicable to the method invocation we are trying to resolve.
Accessibility depends on what type of access the method has been granted (public,
none, protected or private) and where the invocation expression appears.
See Section
6.6 (Access Control) of the JLS for specific details concerning accessibility.
To get a better understanding of the applicability and accessibility concepts, let's have a look at the
following code borrowed from
JLS
15.12.2.1 (Find Methods that are Applicable and Accessible):
- public class Doubler {
- static int two() {return two(1);}
- private static int two(int i) {return 2*i;}
- }
- class Test extends Doubler {
- public static long two(long j) {return j+j;}
- public static void main(String[] args) {
- System.out.println(two(3));
- System.out.println(Doubler.two(3)); //compile-time error
- }
- }
|
- On line 2, we invoke the method
two with one int argument (1) from within class
Doubler. We can see that
we have two methods named two within class Doubler but only the second
one (on line 3) is applicable because its parameter list matches the argument list of the invocation
expression on line 2. At runtime, the method named two on line 3 will be invoked.
- On line 8, we invoke the method
two with one int argument (3) from within class
Test. From the latter's perspective, we have three methods named two
but the one on line 2 is not applicable because the parameter list is empty. The one on
line 3 is applicable since it fulfills the applicability requirements stated above but it is not accessible
(private accessibility) and thus cannot be used. The only applicable and accessible method is
the one on line 6 (Note that the argument 3 is converted to long) within class Test.
- On line 9, we try to invoke a non-accessible (
private modifier!!) method in class Doubler.
The compiler will choke on this and spit some error stating that: two(int) has private access in Doubler,
which is quite understandable.
If we don't manage to find any method declaration that is both applicable and accessible, then
an error during the compilation process will result as it is the case on line 9.
Locate the Most Specific Method
The case where several methods are applicable and accessible arises while
overloading methods. What do we do then? We just have to choose the most specific
one. How do we do that?
The JLS says:
The informal intuition is that one method declaration is more specific than
another if any invocation handled by the first method could be passed on to the other one
without a compile-time type error.
To see how this makes sense, let's take a look at the following code. We have:
public void doSomeJob(String s)
and
public void doSomeJob(Object o)
Both methods are overloaded (same name but different parameter types). Now, suppose
we have the following invocation expression:
doSomeJob("Test");
Both methods are applicable since "Test" is a String but
also an Object (since a String is an Object).
Always come to think of the most specific method
as the one having its parameter types matching the best the argument types of the invocation.
So, the first method is more specific than the second one because its parameter (String)
can be converted to the second's parameter (Object) by method invocation conversion
(see JLS
5.3).
As we have seen above, we may end up with several methods being accessible and applicable.
The final goal of this step is to find the maximally specific method. Put simply,
a method is maximally specific if it is applicable and accessible and there is no other applicable
and accessible method that is more specific.
Now, as the flowchart below will show, it is possible to reach different verdicts:
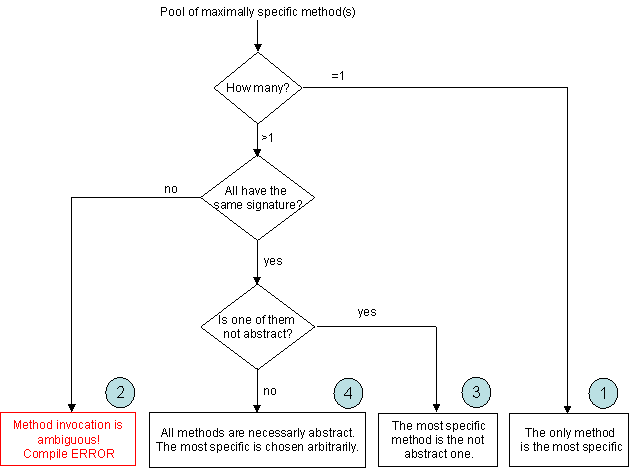 |
- Case 1: if only one method is maximally specific then it is the most specific and the
process goes on.
- Case 2: if there are more than one maximally specific methods and they don't have
the same signature then we have an invocation ambiguity and a compile error is thrown.
Suppose we have the following overloaded method declarations:
public void doSomeJob(String s, Object o)
and
public void doSomeJob(Object o, String s)
and the following method invocation:
doSomeJob("test1","test2");
then this invocation is ambiguous because neither of the declaration is more specific
than the other and thus a compile-time error occurs. We have to add the following more
specific method declaration to get rid of the compilation error:
public void doSomeJob(String s1, String s2)
- Case 3: if there are more than one maximally specific methods, they all have the
same signature and one of them is not declared abstract, then it is the most specific
method and the process goes on.
- Case 4: if there are more than one maximally specific methods, they all have the
same signature and all of them are abstract, one is chosen arbitrarly and the
process goes on.
Another important consideration is that the return type of the method is not taken into
account when resolving method declarations. The following example illustrates the problem:
- class Point { int x, y; }
- class ColoredPoint extends Point { int color; }
- class Test {
- static int test(ColoredPoint p) {
- return p.color;
- }
- static String test(Point p) {
- return "Point";
- }
- public static void main(String[] args) {
- ColoredPoint cp = new ColoredPoint();
- String s = test(cp); //compile-time error
- }
- }
|
The invocation expression on line 12 will cause a compile-time
error. The method on line 4 is the most specific (since it takes a ColoredPoint
argument) but the problem is that the return type, int, is not assignment
compatible with a String. The method on line 7 is also applicable but less
specific than the method on line 4. Moreover, by choosing the method on line 7 the compilation
would succeed because of the return type, String.
Trick :
However, you could make this code compilable by changing line 12 to:
String s = ""+test(cp);
This way the returned int will be transformed to a String object.
|
If we managed to get to this step, it means that we have found THE most specific method
matching the invocation expression and we call it the compile-time declaration for the
method invocation. Now what? Remember the invocation patterns we saw at step 1?
We now have to check if the chosen method can be used in the given context, that is, at the
place where the invocation occurs. As an example, you certainly already know that you cannot
invoke an instance method from within the body of a static method. We have to make sure that
such things don't happen. This is what this step is for.
If the invocation pattern is:
- Identifier and the method is an instance method, then:
- if the invocation appears within a static context
(see JLS 8.1.2),
then a compile-time error occurs. (because
this is not available in static contexts).
- if the invocation is not in the same class containing the declaration
of the method or in an inner class of it, then a compile-time error occurs.
- TypeName . Identifier, then the method (named Identifier) must be
declared
static otherwise a compile-time error occurs. The reason is because
an instance method must be invoked on an object and not on a class. (while a static method
can be invoked both on a class or on an instance as we will see later.)
- super . Identifier, then a compile-time error occurs if either the method
Identifier is abstract or if the invocation occurs in a static context. (in a
static context we don't have a
this to refer to the current instance nor
a super to refer to the superclass instance.)
- ClassName . super . Identifier, then a compile-time error occurs if either
the method Identifier is abstract or the invocation occurs within a static context
(for the same reason than previous point) or the invocation is not directly enclosed by
ClassName or an inner class of ClassName.
Moreover, if the return type of the compile-time declaration is void then the
method cannot be used where a value is expected. For instance, suppose we have the following
expression:
String s = doSomething();
and doSomething's return type is void then a compile-time error
occurs.
More generally, a method whose return type is void can only be used as an
expression statement, that is, alone on a line, or in the initialization or update part of
a for statement
(see JLS 14.13).
Finally, if the chosen method passes all tests successfully, the compilation will succeeds
and we can proceed to runtime checks. The bytecode of the method invocation now contains
the following information that can be used at runtime by the Java bytecode interpreter:
- the name of the method, that is, Identifier;
- the qualifying type of the method
(see JLS 13.1)
(basically where the method declaration is to be found);
- the number of parameters as well as the types of the parameters, in order;
- the result type or
void (note that void IS NOT a
primitive type in Java,
see this
discussion at JavaRanch);
- the invocation mode , that is:
static: if the method declaration contains the static
modifier;non-virtual: if the method is declared private;super: if the invocation pattern is super . Identifier or
ClassName . super . Identifier;interface: if the method is declared in a interface;virtual for any other cases.
These invocation modes can be seen as some sort of hints the compiler creates
in order to let the interpreter know what kind of method it is dealing with and where
the method lookup should begin.
A target reference is a reference to an instance of a class (an object) on which the method
will be invoked. No target references are needed for static methods, that is,
methods whose invocation mode is static.
The target reference is computed differently depending on the invocation pattern.
If the invocation expression is:
- Identifier, then:
- if the invocation mode is
static, there is no need for a target reference.
That means that if a static method is invoked upon a null reference,
no NullPointerException will be thrown.
- otherwise the target reference is the class/interface which contains the method declaration.
- TypeName . Identifier, then there is no target reference (Remember that this
invocation expression is only used for static methods).
- FieldName . Identifier, then:
- if the invocation mode is
static, there is no target reference.
- otherwise the target reference is the value of the expression FieldName.
- Primary . Identifier, then:
- if the invocation mode is
static, there is no target reference. The
expression Primary is evaluated but the result is discarded anyway.
- otherwise the target reference is the value of the evaluation of Primary
(The result must be a reference to an object, see line 24 of the first code excerpt
at the top of this article).
If the evaluation of Primary fails for one reason or another, then the invocation
fails for the same reason. Note also that the argument expressions haven't been evaluated
yet.
- super . Identifier, then the target reference is the value of
this.
- ClassName . super . Identifier, then the target reference is the value
of
ClassName . this
This step's job is to evaluate the argument expression from left to right. If any
argument expression evaluation fails, then no argument expression on its right will be evaluated
and the method invocation expression fails for the same reason.
We now have to determine if the type of the target reference and the method to invoke
are accessible. Three different entities are involved here:
- the method
m to invoke;
- the class
C containing the invocation;
- the class/interface
T in which m is declared.
Any Java programming language implementation must check during linkage that:
m exists in class/interface T, otherwise
a NoSuchMethodError is thrown.- if the invocation mode is
interface, then the target reference type
must implement the specified interface otherwise an IncompatibleClassChangeError
occurs.
Accessibility is the next issue. Since the invocation of method m (declared
in class/interface T) occurs in class C, the compiler has to make
sure that:
T is accessible from C, and then thatm (in T) is also accessible from C.
In clear, this means that the class containing the method invocation must be able to access
the class or interface containing the declaration of the method. If this access is granted,
then the class containing the method invocation must also be able to access the method itself.
Read carefully the latter two sentences again and you'll see that they make sense.
Class/interface T is accessible from class C if:
T and C are in the same package.
(Two classes in the same package are always accessible to one another.)
|
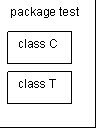 |
T and C are in a different package and T
is public.
(If two classes are unrelated and belong to different packages, they are only accessible to
each other if they are declared public.)
|
 |
T and C are in a different package, T
is protected and T is a superclass of C.
(A protected class/interface is available outside a package only to a
subclass/subinterface.)
|
 |
Finally, method m (in T) is accessible from class C
if either one of the following is true:
m is public.m is protected, and either one of the following is true:
C and T are in the same package.
(protected methods are available throughout a package.)C and T are the same class.
(protected methods are available throughout a class.)C is a subclass of T.
(protected methods are available to the defining class
and to all subclasses as well.)
m has default access (no modifier) and C and
T are in the same package.
(methods with default accessibility are accessible throughout a package.)m is private and either one of the following is true:
C and T are the same class.
(private methods are available throughout a class.)C encloses T or T encloses C,
that is, one is an inner class of the other.
(private methods are available to inner class.)C and T are both enclosed by a third class.
(private methods are available to inner class.)
If this paragraph seems overly complex to you, rest assured that it wasn't out
original intent. The content is very logical. Just read it once or twice before going on.
Think of these accessibility issues as a sort of labyrinth where not only one but several
paths lead to the exit and some don't. Everything depends on the accessibility modifiers.
The next picture will help you find your way through the labyrinth.
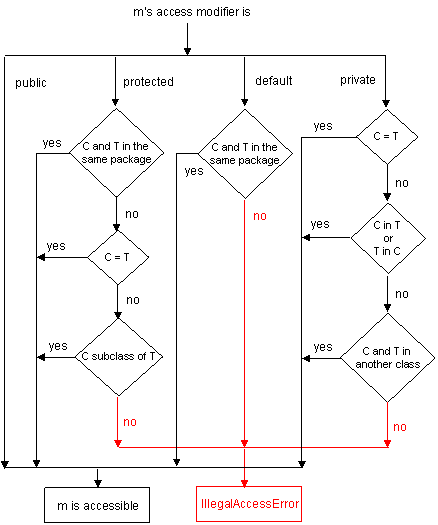
If either of the accessibility checks fails, then an IllegalAccessError
occurs.
We now have to locate the method to invoke. The invocation mode (step 3)
provides us with that information. After this step we end up with a precise method to invoke.
Don't worry if you feel lost after reading this paragraph, the meaning is not very easy to grasp
and, moreover, this is the most important but also the most difficult step of the whole method
invocation process. Read this section twice or thrice if you feel the need to do so.
Remember that we have 5 different invocation modes: static, nonvirtual,
interface, super and virtual.
static
(static modifier) |
We don't need any target reference (on which to invoke the method), overriding is NOT allowed and method
m of class T is the one to be invoked. The method lookup ends here.
|
Note :
Every subsequent invocation mode handles an instance method invocation, we therefore need the target reference
on which the method will be invoked. If this reference is null then a NullPointerException
is thrown. Otherwise, the target reference (see step 4) refers to the target object which will
be used as this in the method body.
|
nonvirtual
(private modifier) |
Overriding is NOT allowed and method m of class T is the one to be invoked.
The method lookup ends here.
|
For the three remaining invocation modes, overriding may occur. That's why we need a dynamic method lookup process.
The process starts looking for the method in class S (and then if needed in the superclasses of S),
where S is the runtime class of the object on which the method is invoked. Moreover,
- if the invocation mode is
interface, then S necessarly implements interface T.
- if the invocation mode is
virtual, then S is T or a subclass of T.
- if the invocation mode is
super, then S is the class/interface
in which the method is declared.
The method lookup for interface, virtual and super invocation mode
is as follows:
If S contains a non-abstract declaration of a method named m having
the same descriptor, that is, same number of parameters, same parameter type AND same return type, then:
- if the invocation mode is
interface or super, then m is the method
to be invoked. The method lookup ends here.
- if the invocation mode is
virtual and the method declaration in S overrides the one
in the compile-time type of the target reference of the method invocation, then m is the method
to be invoked. The method lookup ends here.
Otherwise, if S has a superclass, then this lookup is performed recursively on the
direct superclass of S. The result of this recursion will be the method to
be invoked.
This lookup always succeeds provided that the compilation of the classes has been
done in a consistent way or various errors may occur.
This step just handles
administration stuff, like creating a new activation frame, synchronizing data access if
needed and transferring control to the method body.
We won't go into very much details here. If you want to know exactly what an
activation
frame is, or what
synchonization means,
please refer to the given hyperlinks.
Activation
Frame
Creation |
At the end of the previous step, we ended up with the actual method to invoke. The only
thing that remains to be done is to execute it. To do so, we create a new activation frame containing:
- the target reference
this (only for non-static methods) referring to the actual
object on which the method is invoked;
- the argument values (values passed between the paranthesis) if any;
- enough space for local variables;
- any other bookkeeping information (stack pointer, program counter, reference to previous activation frame, and the like);
At this point, if not enough memory is available to create the frame, then a OutOfMemoryError occurs.
This new activation frame becomes the new current activation frame and the argument values are assigned to the newly created
parameter variables (available within the method's body). Just think of the activation frame as a context for the method
execution that contains everything that the method may need to execute properly.
|
native
methods |
If the method is declared native and the binary code for the method has not been loaded, then an
UnsatisfiedLinkError occurs.
|
synchronized
methods |
Finally, if the method is not synchronized, that is, its declaration does not contain the
synchronized keyword, the control is transferred to the method's body. Otherwise, we have to lock
an object before transferring the control to the method's body.
If the method is:
static, then the Class object of the class containing the method is locked;- non-
static (an instance method), then the target reference (the object itself) is locked.
Just after the locking has occurred, the control is transferred to the method's body for further processing. The previously
locked object is unlocked upon completion, whether normally or abruptly (in the case of exceptions or errors).
|
Written by Valentin Crettaz.
|




 Exploring JSP Documents (XML Style JSP Pages)
Exploring JSP Documents (XML Style JSP Pages)