| Articles in this issue :
|
Driving On CruiseControl - Part 2
Driving On CruiseControl - Part 2
Lasse Koskela
Accenture Technology Solutions
In Part 1 of this tutorial, we set up the
CruiseControl
Continuous Integration server against a
Subversion repository.
In this second part, we'll continue where we left off by taking our
build results online with the CruiseControl reporting web application.
As we discussed in Part 1, there are some very good reasons for wanting to
put your Continuous Integration builds' results online for everyone to see.
Many don't like filling their inbox with full-blown reports, many projects
don't have easy access to a mail server, and many projects would like to
integrate the build results to other dashboard-like applications which don't
quite fit in with the HTML email publisher solution.
In the case of CruiseControl, the web application used for presenting
build results needs to work with the XML log files produced by CruiseControl
during a build cycle. Not a surprise, the most used application used for
exposing CruiseControl's build results over the Web is the reporting
application that comes as part of the CruiseControl distribution.
Let's dig in.
Configuring the CruiseControl web application
The first step in getting the CruiseControl reporting application up
and running is to build it from the sources and configure a few
parameters.
Below is the familiar-looking directory structure from Part 1:
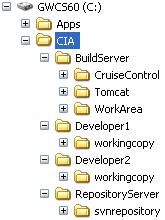
Assuming you used the above directory structure, this is how you build
the cruisecontrol.war web application:
C:\CIA\BuildServer\CruiseControl\reporting\jsp> build war
lib/ant.jar;lib/optional.jar;lib/junit.jar;lib/xerces.jar
Using Javac!
Buildfile: build.xml
clean:
[delete] Deleting directory C:\CIA\BuildServer\CruiseControl\reporting\jsp\dist
[delete] Deleting directory C:\CIA\BuildServer\CruiseControl\reporting\jsp\classes
[delete] Deleting directory C:\CIA\BuildServer\CruiseControl\reporting\jsp\testresults
[delete] Deleting directory C:\CIA\BuildServer\CruiseControl\reporting\jsp\tmp
init:
[mkdir] Created dir: C:\CIA\BuildServer\CruiseControl\reporting\jsp\dist
[mkdir] Created dir: C:\CIA\BuildServer\CruiseControl\reporting\jsp\classes
[mkdir] Created dir: C:\CIA\BuildServer\CruiseControl\reporting\jsp\testresults
[mkdir] Created dir: C:\CIA\BuildServer\CruiseControl\reporting\jsp\tmp
check-duplication:
checkstyle:
compile:
[javac] Compiling 27 source files to
C:\CIA\BuildServer\CruiseControl\reporting\jsp\classes
test:
[javac] Compiling 21 source files to
C:\CIA\BuildServer\CruiseControl\reporting\jsp\classes
[junit] Running net.sourceforge.cruisecontrol.BuildInfoTest
[junit] Tests run: 3, Failures: 0, Errors: 0, Time elapsed: 0,111 sec
[junit] Testsuite: net.sourceforge.cruisecontrol.BuildInfoTest
[junit] Tests run: 3, Failures: 0, Errors: 0, Time elapsed: 0,111 sec
...
-set.log.dir:
[input] WARNING! Property user.log.dir not set!
Please enter the absolute path to the CruiseControl logs directory:
C:\CIA\BuildServer\CruiseControl\main\logs
-set.status.file:
[input] WARNING! Property user.build.status.file not set!
Please enter the absolute path to the current build status file:
currentbuild.txt
-set.artifacts.dir:
[input] WARNING! Property cruise.build.artifacts.dir not set!
Please enter the absolute path to the directory where additional build
artifacts are stored:
/
create-web-xml:
[copy] Copying 1 file to
C:\CIA\BuildServer\CruiseControl\reporting\jsp\tmp
war_jdk14:
war_pre14:
[war] Building war:
C:\CIA\BuildServer\CruiseControl\reporting\jsp\dist\cruisecontrol.war
war:
BUILD SUCCESSFUL
Total time: 56 seconds
C:\CIA\BuildServer\CruiseControl\reporting\jsp>
Notice how the -set.xxx.xxx targets are asking for input? That's the
build script noticing that it's missing some essential details about
the location of your CruiseControl logs directory, the currentbuild.txt
file, and the artifacts directory. The build script inserts the given paths
into the web.xml of the resulting cruisecontrol.war archive.
After building the reporting web application, we need to deploy it somewhere.
I chose to use Jakarta Tomcat
as my web container of choice. You could just as easily use another J2EE
compliant web container such as Jetty
or a full-blown J2EE application server such as
JBoss.
Tomcat has an auto-deployment directory named "webapps" where you can just
drop a .war file and it gets deployed automatically within a few seconds
(or whenever you restart Tomcat if it's not running at the time). That's
exactly what we're going to do next.
With Tomcat installed (unzipped) to C:\CIA\BuildServer\Tomcat, it can be
started by double-clicking on bin\startup.bat:
25.9.2004 16:39:57 org.apache.coyote.http11.Http11Protocol init
INFO: Initializing Coyote HTTP/1.1 on http-8080
25.9.2004 16:39:57 org.apache.catalina.startup.Catalina load
INFO: Initialization processed in 1322 ms
25.9.2004 16:39:57 org.apache.catalina.core.StandardService start
INFO: Starting service Catalina
25.9.2004 16:39:57 org.apache.catalina.core.StandardEngine start
INFO: Starting Servlet Engine: Apache Tomcat/5.0.28
25.9.2004 16:39:58 org.apache.catalina.core.StandardHost start
INFO: XML validation disabled
25.9.2004 16:39:58 org.apache.catalina.core.StandardHost getDeployer
INFO: Create Host deployer for direct deployment ( non-jmx )
25.9.2004 16:39:58 org.apache.catalina.core.StandardHostDeployer install
INFO: Processing Context configuration file URL
file:C:\CIA\BuildServer\Tomcat\conf\Catalina\localhost\admin.xml
25.9.2004 16:39:58 org.apache.struts.util.PropertyMessageResources <init>
INFO: Initializing, config='org.apache.struts.util.LocalStrings',
returnNull=true
25.9.2004 16:39:58 org.apache.struts.util.PropertyMessageResources <init>
INFO: Initializing, config='org.apache.struts.action.ActionResources',
returnNull=true
25.9.2004 16:39:59 org.apache.struts.util.PropertyMessageResources <init>
INFO: Initializing, config='org.apache.webapp.admin.ApplicationResources',
returnNull=true
25.9.2004 16:40:01 org.apache.catalina.core.StandardHostDeployer install
INFO: Processing Context configuration file URL
file:C:\CIA\BuildServer\Tomcat\conf\Catalina\localhost\balancer.xml
25.9.2004 16:40:01 org.apache.catalina.core.StandardHostDeployer install
INFO: Processing Context configuration file URL
file:C:\CIA\BuildServer\Tomcat\conf\Catalina\localhost\manager.xml
25.9.2004 16:40:01 org.apache.catalina.core.StandardHostDeployer install
INFO: Installing web application at context path /jsp-examples from URL
file:C:\CIA\BuildServer\Tomcat\webapps\jsp-examples
25.9.2004 16:40:01 org.apache.catalina.core.StandardHostDeployer install
INFO: Installing web application at context path from URL
file:C:\CIA\BuildServer\Tomcat\webapps\ROOT
25.9.2004 16:40:01 org.apache.catalina.core.StandardHostDeployer install
INFO: Installing web application at context path /servlets-examples from URL
file:C:\CIA\BuildServer\Tomcat\webapps\servlets-examples
25.9.2004 16:40:01 org.apache.catalina.core.StandardHostDeployer install
INFO: Installing web application at context path /tomcat-docs from URL
file:C:\CIA\BuildServer\Tomcat\webapps\tomcat-docs
25.9.2004 16:40:01 org.apache.catalina.core.StandardHostDeployer install
INFO: Installing web application at context path /webdav from URL
file:C:\CIA\BuildServer\Tomcat\webapps\webdav
25.9.2004 16:40:01 org.apache.coyote.http11.Http11Protocol start
INFO: Starting Coyote HTTP/1.1 on http-8080
25.9.2004 16:40:02 org.apache.jk.common.ChannelSocket init
INFO: JK2: ajp13 listening on /0.0.0.0:8009
25.9.2004 16:40:02 org.apache.jk.server.JkMain start
INFO: Jk running ID=0 time=0/50
config=C:\CIA\BuildServer\Tomcat\conf\jk2.properties
25.9.2004 16:40:02 org.apache.catalina.startup.Catalina start
INFO: Server startup in 4447 ms
Dropping the cruisecontrol.war into the webapps directory should result
in a bit more activity in the Tomcat window:
25.9.2004 16:41:42 org.apache.catalina.core.StandardHostDeployer install
INFO: Installing web application at context path /cruisecontrol from URL
file:C:/CIA/BuildServer/Tomcat/webapps/cruisecontrol
Looking familiar? Good. You've just put your build results online!
Exploring the reporting application UI
With Tomcat running and the reporting application deployed, it's time
to verify the installation by pointing a web browser at the front page:
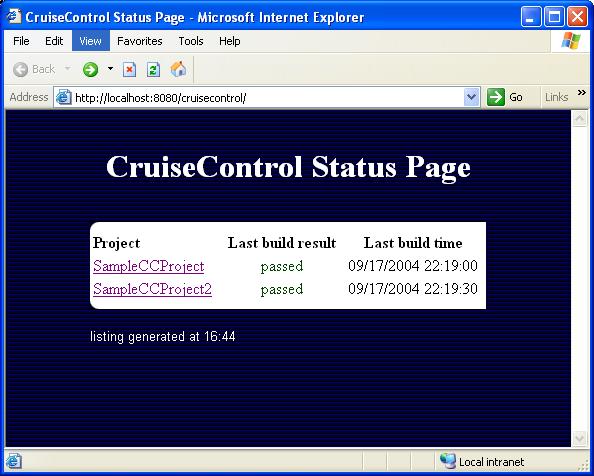
As you can see, the front page gives a very brief summary of all
projects for which the reporting application can find reports under the
logs directory we configured it to look at. In addition to the projects'
names, the front page lists the latest status of each project (passed/failed)
and when the last build was made.
Now try clicking one of the projects listed. Do you see an all-blue page like
this?
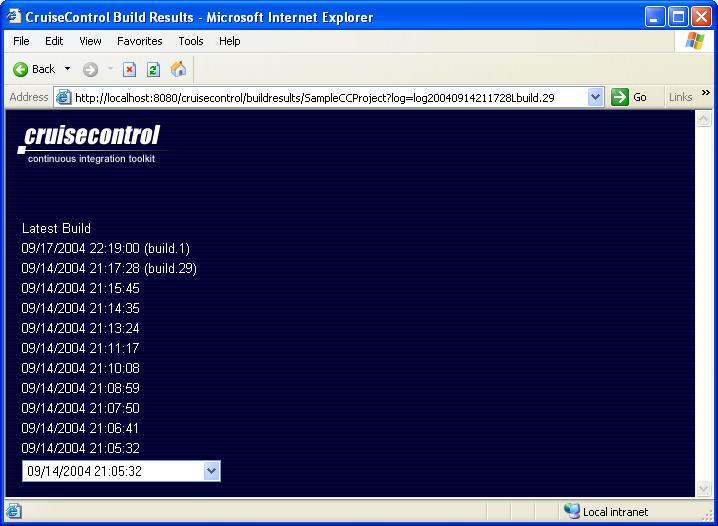
If you see a page like that and your web container's log file has a stack
trace saying "org.apache.xml.utils.WrappedRuntimeException: The output format
must have a '{http://xml.apache.org/xalan}content-handler' property!", the
problem is a version clash between Xerces and Xalan under JDK 1.4. Some solutions
you should try to fix this are:
- Upgrade the JDK you run the web container with into a newer version
(I'm using J2SE 1.4.2_05 with Tomcat 5.0.29 in this article)
- Build the CruiseControl web application with -Djdk1.4=true
or manually remove xerces.jar and xalan.jar from the .war archive
before deploying it
Hopefully, with more or less tweaking, you should be looking at a page like this:
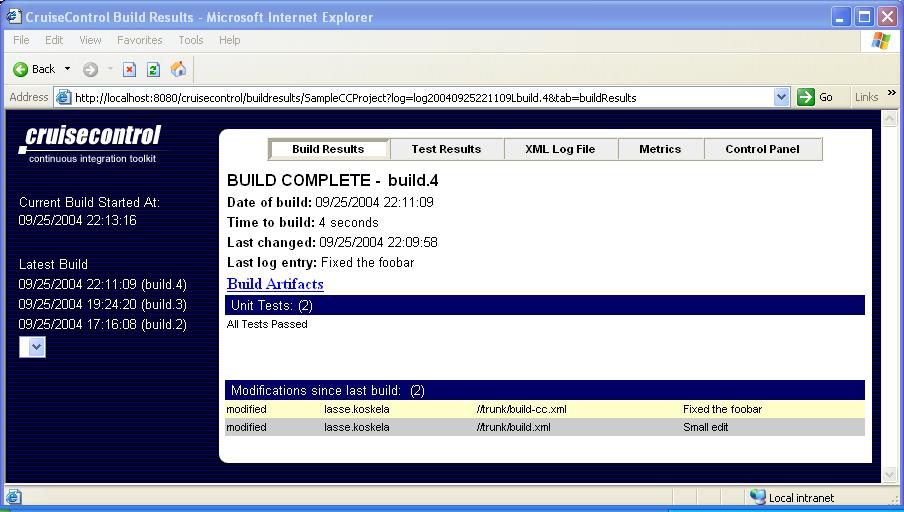
First of all, the navigation pane on the left-hand side shows you the
project's scheduling status, i.e. tells you when the current build was
started or when the next build starts (depending on whether CruiseControl
is currently waiting for the next build cycle or doing a build).
Below the scheduling status, there's a list of dated builds. Clicking on
the date of a build opens up that particular build's results (or whatever
tab you had selected when clicking the link). Once you've got more than
10 builds under your belt, only the first 10 will be displayed as links
and the rest will be collected into the dropdown box below those links.
See those tabs in the top of the main view? The reporting application splits
the information in the CruiseControl log file into smaller views so you can
look at just the information you want.
The first tab, "Build Results", displays a summary of the selected build
including date information, a list of failed unit tests, and a very useful
list of modifications in the source repository since the previous build
(a.k.a. "the suspects" if the build has turned from green to red). A quick
peek at this page is most often enough to give you the information you're
looking for. Also, the "Build Results" tab includes a link named
"Build Artifacts", which leads to a directory listing of the project's
artifacts directory -- the place where CruiseControl gathers a project's
build output files (such as sample.jar for the sample project
we used in Part 1).
If you feel like digging deeper, the "Test Results" tab displays a full
listing of all tests run and their pass/fail status and the execution time.
The "XML Log File" page renders the raw XML log file for you to look at
(to date, I have not needed to but it's good to know it's there just in case).
The "Metrics" tab displays a couple of graphs showing the green/red stats
for your project, which is a more recent and very nice little "extra"
for the reporting application.
The last tab, "Control Panel", is probably displaying an error page to you.
Why is that? Well, if you look at the HTML generated by CruiseControl, you'll
see that the error page comes from an embedded IFRAME pointing to port 8000
on the build server. What it's expecting to find from that port is the
CruiseControl JMX server (or, more accurately, the HTTP adapter for it).
At this point, let's go and restart the CruiseControl process with the JMX
features enabled:
C:\CIA\BuildServer\CruiseControl\main\bin> cruisecontrol -port 8000
"C:\j2sdk1.4.2_05\bin\java" -cp "..." CruiseControl -port 8000
[cc]syys-25 18:38:24 Main - CruiseControl Version 2.1 Compiled on
September 12 2004 1552
[cc]syys-25 18:38:24 trolController- projectName = [SampleCCProject]
[cc]syys-25 18:38:24 Project - Project SampleCCProject: reading
settings from config file [C:\CIA\BuildServer\CruiseControl\main\bin\config.xml]
[cc]syys-25 18:38:24 trolController- projectName = [SampleCCProject2]
[cc]syys-25 18:38:24 Project - Project SampleCCProject2: reading
settings from config file [C:\CIA\BuildServer\CruiseControl\main\bin\config.xml]
[cc]syys-25 18:38:25 ontrollerAgent- Starting HttpAdaptor with CC-Stylesheets
[cc]syys-25 18:38:25 ontrollerAgent- starting httpAdaptor
[cc]syys-25 18:38:25 Project - Project SampleCCProject starting
[cc]syys-25 18:38:25 Project - Project SampleCCProject: idle
...
The key here is to give the CruiseControl startup script the port number for
the JMX adapter as an argument. We're using port 8000 here as it's the default
for the reporting web application. If you need to use a different port, you'll
have to start CruiseControl with a different port number and edit
controlpanel.jsp under reporting/jsp (yes, I know...).
With CruiseControl running JMX enabled, reload the "Control Panel" tab in your
browser and you should see the CruiseControl JMX Console:
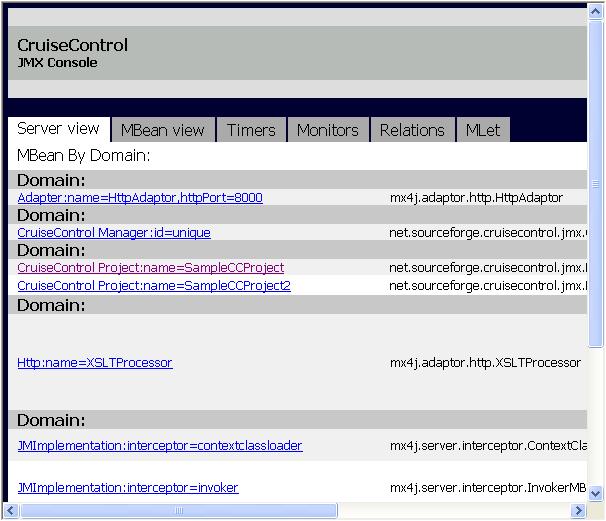
Tip: You might want to customize the reporting web application a little
by making the "Control Panel" link open the JMX Console in a new window
instead of squeezing it into a tiny IFRAME.
The JMX Console is a very handy tool for changing different configurations
at runtime without restarting CruiseControl. Try navigating to your
project (link named "CruiseControl Project:name=SampleCCProject")
to see all the nice things you can change or trigger through the JMX Console.
For example, you can change the project's build interval by putting a new
value for the "BuildInterval" attribute and clicking the "set" button right
next to the text field. You can also force a build by clicking on the
"Invoke" button for an operation named "build". Play around with the
console and keep the output of the CruiseControl process open to see how
your doings affect CruiseControl's. Makes you wonder why more products don't
ship with similar JMX utilities, doesn't it.
That's all for now
I'm afraid that's all for now. In the next part of my series of CruiseControl
tutorials, I might show how to connect your CruiseControl server to the
developers' desktops. "I might" means that's what I'm going to do unless
I get feedback to tell me otherwise.
Discuss this article in The Big Moose Saloon!
Return to Top
|
The SCJP Tip Line
Implicit Conversions, Explicitly
by Corey McGlone
In this article, I'm going to go over the basics of explicit and implicit conversions and some of the nuances associated with them. In general, the material in this article would be considered "fair game" for the SCJP exam so, if you're planning on taking the exam soon, you'll want to make sure you understand the concepts in this article well.
Most of you probably already know what a conversion is. In general terms, a conversion is the process of transforming one thing into another, such as melting ice to turn it into water. In Java, when we talk about conversions, we are generally talking about the process of changing the type of an object from one type to another. One example might be the process of converting an int to a long or a short to a byte. You can also convert objects from one type to another. Often, you'll hear such a conversion called a "cast." For example, to turn an int into a byte, you "cast" the int as a byte.
Widening (Safe) Conversions vs. Narrowing (Unsafe) Conversions
There are two basic types of conversions: widening and narrowing. You might also hear these referred to as safe and unsafe conversions, respectively.
So, what is a widening conversion, and why is it safe? Well, when dealing with primitives, a widening conversion occurs when you convert one type, A, to another type, B, when type B has a larger (or wider) range than A. This is the type of cast that occurs when you cast a byte to an int. A byte has a range of just 256 values, from -128 to 127. An int, on the other hand, has a range of 4,294,967,296 values, ranging from -2,147,483,648 to 2,147,483,647. Obviously, any value that fits in a byte will fit in an int. Because of this, there is no chance for data loss and the conversion is considered "safe."
With that in mind, can you guess what a narrowing conversion is and why it is considered unsafe? Based on our previous conclusion, that a widening conversion was considered "safe" because there was no chance for data loss, it seems only natural that a narrowing conversion would be considered "unsafe" because there is a chance for data loss. If we turn our previous example around and try to cast an int as a byte, we have a narrowing conversion. This is because the range of a byte is much smaller (or narrower) than the range of an int. What happens if you try to convert an int with a value of 200 to a byte? You're bound to lose some data because the number 200 is not within the range of a byte. Performing such a conversion will change the number 200 into -56 because data is lost.
If you'd like to get more details about widening and narrowing conversions, I'd suggest checking out this article in the SCJP Tip Line.
Implicit vs. Explicit Conversions
I know, I know - I just stated that there are two types of conversions and now I've gone and come up with two more types. Well, in my defense, implicit and explicit conversions aren't really new conversions, they simply describe how narrowing and widening conversions are performed. An implicit conversion is performed automatically, with no additional input from you (the programmer). An explicit conversion, on the other hand, is not performed automatically and is, instead, dictated by you, the programmer.
I'm sure it comes as no shock to you that widening conversions, which are always safe from data loss, generally occur implicitly, while narrowing conversions, which run the risk of data loss, are usually performed explicitly. Let's take a look at an example that performs both:
|
Source Code
|
public class Conversions
{
public static void main(String[] args)
{
int i = 200;
byte b = 10;
int j = b; // 1
byte c = (byte)i; // 2
System.out.println(j);
System.out.println(c);
}
}
// Output
10
-56
|
Take a look at line 1. Notice that we're assigning a byte variable to an int variable. Java is a strongly typed language so you can't just assign one data type to another. Therefore, before this is allowed, some sort of conversion much take place. In this case, we're going from a byte to an int, which is a widening conversion. The compiler realizes that and simply adds a cast to convert the byte to an int prior to assignment. This is called an implicit cast because Java does it for you. Pretty convenient, huh? (See §5.2 Assignment Conversion in the JLS for more details about assignment conversions.)
Now let's take a look at line 2. In this case, we're trying to assign an int to a byte variable. We already know from our previous discussion that this is considered a narrowing conversion and we risk losing data if we do so. Because of this, the compiler won't just do the conversion for us. Rather, we need to tell the compiler, explicitly, that we want the conversion to take place. We do that by adding the (byte) in front of the variable. This is your way of telling the compiler, "Yes, I know this is risky, but I'll take the responsibility for it. Just do the conversion." Without that directive, the compiler will give you an error about that line.
Implications of Implicit Casting
In general, explicit casts are easy to deal with because you're the one making them. You have to know what type something is, because you're the one telling the compiler which type to make it. However, because the compiler will sometimes cast things for you, you might not realize that it's doing such a thing and the results can be... unexpected. Let's look at a few examples.
Binary Numeric Promotion
Let's start in the wonderful world of computer hardware. Imagine you're creating a simulator that is designed to test a piece of hardware that your company is designing. In order to test the software, you need to read in two bytes of data from the hardware and xor those bytes together. You'll be storing the result in another byte variable for later use. Here's a little snippet of code that you might be using for such an application:
|
Source Code
|
public class HardwareTester
{
public static void main(String[] args)
{
byte input1 = readByteFromHardware();
byte input2 = readByteFromHardware();
byte xorTotal = input1 ^ input2;
// Do some more processing using xorTotal
}
private static byte readByteFromHardware()
{
// Reads a byte of data from the hardware and returns it.
// For the sake of this example, assume this method
// is complete and returns a value.
}
}
|
Looks like a simple program, right? Well, the bad news is that this program doesn't even compile! Why not? Can you see the error? The compiler message helps to give it away - here's what it says:
HardwareTest.java:8: possible loss of precision
found : int
required: byte
byte xorTotal = input1 ^ input2;
^
So, the question is, why is the compiler complaining about a narrowing conversion at this point? Notice that it says you're trying to convert an int to a byte. Certainly, converting an int to a byte is a narrowing conversion, but where the heck did the int come from? There isn't an int anywhere in that code!
Well, the int shows up because an implicit conversion is taking place. In Java, any time you perform a binary operation (an operation requiring two operands), Binary Numeric Promotion is performed. Binary Numeric Promotion casts each operand up to the size of the other or, if neither is larger than an int, both are cast as ints. What type do you think you'll get as a result of xor'ing two int values together? You're going to get an int, of course. That's why you're getting a compiler error - the xor operation is returning an int and we know that we can't assign an int to a byte without a cast because that's a narrowing conversion. Therefore, in order to make the above code work, you must add a cast to the xor statement, like this: byte xorTotal = (byte)(input1 ^ input2);
Implicit Explicit Casts
Next, let's focus on implicit explicit casts. What?!? Yeah, you heard me - implicit explicit casts. There is a case in which an explicit cast is implied. Anyone know what it is?
The answer is a compound assignment operator. Compound assignment operators, such as +=, -=, *= all contain an explicit cast, even though it's not shown. Take the following application as an example:
|
Source Code
|
public class ImplicitExplicitCast
{
public static void main(String[] args)
{
byte b1 = -13;
b1 >>>= 1;
System.out.println(b1);
}
}
|
What does this program print? Even if you don't know what the value of -13 shifted to the right one position is off the top of your head, you can be certain that the result will be positive because we're using the unsigned right shift operator. However, if that's your assumption, I'm afraid to say you need to stop making assumptions. This program prints -7.
So what went wrong? Unlike our hardware program, there was no compiler error to tell us that something wasn't right. The compiler was just fine with the code we wrote but, if the code is good, why the failure?
Well, the reason for the "failure" is that compound assignment operators contain an explicit cast, implicitly. :) If I rewrite this code snippet and expand the compound assignment operator to what it truly is, the code would look like this:
|
Source Code
|
public class ImplicitExplicitCast
{
public static void main(String[] args)
{
byte b1 = -13;
b1 = (byte)(b1 >>> 1);
System.out.println(b1);
}
}
|
From that, the problem is probably a bit more obvious. From our previous conversation about binary numeric promotion, we know that b1 is first going to be cast from an 8 bit byte to a 32 bit int. Next, we shift all of the bits 1 position to the right and add a 0 to the left. That makes the resultant value positive, right? Well, yes, it does...for a moment. The very next thing we do, though, is cast our int as a byte and chop off the high order 24 bits, which includes our precious sign bit. What we're left with is -7.
Those are just a couple cases in which you can get into trouble from an implicit cast. I'm sure there are plenty more "gotchas" out there waiting for you so be wary. Check out Dan Chisholm's mock exams (referenced below) for some additional practice.
Conclusion
Understanding type conversions is very important with regards to the SCJP exam. You might not see these exact examples on your exam, but the principles are certainly fair game. Make sure you understand this material well. Besides the SCJP exam, understanding conversions and their implications is a fundamental topic that should be well understood by any Java programmer.
Always be wary of picky details when you're taking the exam but be especially wary if you start seeing data types like bytes and shorts. If those appear in a question, make sure there aren't any hidden conversions you're missing. Below, I've cited some great resources for more information on this topic if you need some more clarification. Of course, if this material is giving you trouble, feel free to pop into the SCJP Forum.
JLS: Conversions and Promotions
SCJP Tip Line: Widening and Narrowing Conversions
JLS: Compound Assignment Operators
Dan Chisholm's Mock Exams, Including Single-Topic Exams on Conversions
Until next time,
Corey
Discuss this article in The Big Moose Saloon!
Return to Top
|
Java Designs
Synchronized Multithreading with Swing
by Tom
Tolman
For some people, hearing the word "thread" brings to mind spiders, or
else other creeping things which can be seen on dark nights when one is
coding alone in the office. However, this should not be the case, for in a
Java program threads are your friend, and perhaps unbeknownst to you, they
have been aiding your adventures from the first time you used the Swing
library.
Before we slide down into a possible tangle of multiple threads,
remember that one should not begin creating threads without a good
purpose, for they are complex and need to be completely thought through
before being used. When you are creating threaded code, keep it as simple
as possible, for any complexity you introduce will surely lead you into
some sticky situations like a moth who gets trapped forever in a
deadlocked situation.
You may be surprised to find out that Swing already uses
multiple threads. "How is this possible?" you might ask. "I have never
implemented a Runnable interface nor extended Thread in my years of using
Swing." Swing utilizes something called the event dispatch thread
which operates behind the scenes. This thread is responsible for handling
system events, such as when a user clicks the mouse button or when a Swing
timer goes off. Fortunately, event handling code automatically executes
in the event dispatch thread, so all of your callbacks are already taking
place on this thread. When the user clicks on one of your controls,
the event is handled by the event dispatch thread and your code that
responds to this event is executed on this separate thread.
Try running this example which shows the name of the thread in the
label on the left.
| Source Code |
import java.awt.*;
import java.awt.event.*;
import javax.swing.*;
public class ThreadDemo extends JFrame {
JLabel label;
public ThreadDemo() {
super("Thread Demo");
setSize(300,50);
this.getContentPane().setLayout(new GridLayout(1,2));
label = new JLabel();
label.setText(Thread.currentThread().getName());
this.getContentPane().add(label);
JButton button = new JButton();
button.setText("Get Thread");
ActionListener listener = new ActionListener() {
public void actionPerformed(ActionEvent e) {
label.setText(Thread.currentThread().getName());
}
};
button.addActionListener(listener);
this.getContentPane().add(button);
setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
setVisible(true);
}
public static void main(String args[]) {
new ThreadDemo();
}
}
|
The first time the call Thread.currentThread().getName()
is invoked, it is in the thread named "main", because the label is created
within the main thread. However, within the ActionListener
which is invoked when you press the on screen button the thread name is
"AWT-EventQueue-0". The actionPerformed call is invoked when
you click the mouse button, which is handled in the event dispatch thread.
You can use this technique of checking the thread name to ensure any code
you are writing is actually being run in the event dispatch thread.
One of the fortunate things about the fact that events are handled
automatically on the event dispatch thread is that Swing is not thread
safe and you must modify any realized GUI components from within the event
dispatch thread. Thus, the difficult and dangerous task of keeping
Swing thread-safe is happening by default for your event handling code, and is
already taking place within this context. You could imagine if a separate
thread began modifying a combo box at the same moment a user chose that
combo box and started scrolling through it. The technical term for such a
confluence of events is "uh oh". In the worst case, not only will data
integrity be compromised, but the entire application will lock up, and the
hours of work the user has spent using your application will vanish into a
cloud of smoke coming out of his or her ears.
Historically there has been one mighty exception to the rule that you
must modify any GUI components from within the event dispatch thread; that
was at startup. It had been considered safe to create the GUI in the
application's main thread provided no GUI components were visible. This is
the way most programs are written, and is likely to be safe, but now as
you can see the official way to ensure complete safety is to now
also create the GUI itself within the event dispatch thread. This will
ensure you have no lockup at startup.
There are two methods for invoking code inside the event dispatch
thread when you are not already in that thread: invokeLater
and invokeAndWait. The invokeLater is utilized
by passing in a Runnable interface object with a run method which executes
at a later time on the event dispatch thread. The
invokeAndWait operates in the same way, but does not return
until the event dispatch thread has finished executing the code. When you
create these Runnable objects and pass them to the invoke methods, they
are executed on the event dispatch thread.
Below is the code to replace the main method coded above with the
creation of the GUI taking place on the event dispatch thread. An
anonymous class is created with the Runnable interface which calls the
new ThreadDemo(); to create the GUI. As you can tell if you
run the modified code, the creation of the label now takes place on the
event dispatch thread.
| Source Code |
public static void main(String args[]) {
javax.swing.SwingUtilities.invokeLater(new Runnable() {
public void run() {
new ThreadDemo();
}
});
}
|
Using other threads
If you have ever used an application and
wondered "What the heck is taking so long here?" you have encountered a
reason to use multiple threads. The user is in charge of your application,
and as soon as you wander off with the event dispatch thread with an
extremely slow piece of code, your user has lost control. The application
will appear to hang, since no other mouse or keyboard events can be
handled as long as the event dispatch thread is busy.
For this sample application we will compute the value of P using perhaps the slowest algorithm possible. Since
P is an irrational number, a complete
implementation could take forever to complete. In case the user is not
willing to wait forever, we will utilize multiple threads: one thread to
compute the value of P, and the other default
event dispatch thread to keep the user informed of what we think P is at the moment. For this example we store the
approximated value of pi in a double.
As an aside, the way we are computing P here
is by throwing random darts that hit a square with a quarter of a circle
inscribed in it. The ratio of darts which fall within the circle to the
total number of darts thrown gives a way to approximate P. The square is 1 unit across, and the circle has a
radius of 1 unit. The complete circle has an area of P * radius * radius so the quarter circle has an area
of P / 4. Thus P is
approximately equal to 4 * the number of circle quadrant hits divided by
the number of throws.
 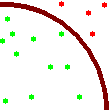 P is roughly equal to the 4 * number of
green dots / (number of green dots + red dots).
P is roughly equal to the 4 * number of
green dots / (number of green dots + red dots).
Since this is random, there is no guarantee we will converge on P- all of the darts may well fall into the circle
quadrant and it will appear P is very close to
4.0. In reality the most significant digits of PI will be calculated
fairly quickly and it will take a very long time to find additional
significant digits. This is useful, however, as an example utilizing
concurrent threading with Swing.
| Source Code |
import java.awt.*;
import java.awt.event.*;
import javax.swing.*;
public class CalculatePi extends JFrame {
JLabel label;
volatile double pi = 0;
synchronized void setPi(double value) {
pi = value;
}
synchronized double getPi() {
return pi;
}
class ThrowDarts implements Runnable {
public void run() {
long counter = 0;
long hits = 0;
double x = 0;
double y = 0;
while (counter < Long.MAX_VALUE)
{
counter++;
x = Math.random();
y = Math.random();
if (Math.sqrt(x*x + y*y) < 1.0f)
{
hits++;
}
setPi(4 * (double) hits / (double) counter);
if (counter%1000 == 0)
{
try {
javax.swing.SwingUtilities.invokeAndWait(new Runnable() {
public void run() {
label.setText("" + getPi());
}
});
}
catch (Exception e) {
e.printStackTrace();
}
}
}
}
}
public CalculatePi() {
super("Throwing Darts");
setSize(300,50);
label = new JLabel();
label.setText(Thread.currentThread().getName());
this.getContentPane().add(label);
setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
setVisible(true);
ThrowDarts dartThrower = new ThrowDarts();
Thread t = new Thread(dartThrower);
t.start();
}
public static void main(String args[]) {
javax.swing.SwingUtilities.invokeLater(new Runnable() {
public void run() {
new CalculatePi();
}
});
}
}
|
Notice that the variable pi is declared to be volatile.
This tells the compiler not to place the value of pi into any
registers so that it can be accessed from any thread. To guarantee that
any accesses to the value of pi are atomic, that is taking
place in a single operation, both set and get methods exist with the
keyword synchronized to make sure that these operations
complete fully before any other thread executes. The code that runs within
these synchronized methods will be mutually exclusive; both of these
methods can not be executed at once by different threads. Depending on the
Java Virtual Machine implementation potentially half of the bytes of
pi could be accessed when the other thread changes the value.
At regular intervals, whenever the counter is a multiple of 1000, an
anonymous class implementing Runnable is created that updates the label. It
is passed to invokeAndWait which will wait for the event
dispatch thread to return before processing further. In this way, the
update to the label that shows pi takes place on the event dispatch
thread.
The invokeAndWait will wait for the event dispatch thread
to return before computing more, thus preventing us from adding too many
Runnable objects on the event dispatch thread. Do not create too many
Runnable objects on the event dispatch thread or the thread can get bogged
down. An alternative technique would be to utilize a timer to periodically
update the label.
In the main method of the program, the interface is created on the
event dispatch thread with its own anonymous instantiation of the Runnable
interface.
Parting ideas
There are some methods which are thread safe within the Swing component
hierarchy. They will be marked in the documentation as "This method is
thread safe".
In summary, there is no need to create separate threads for the general
Swing application, although you are advised to instantiate your GUI on
the event dispatch thread. All of your event handling code will take place
on the event dispatch thread by default. If you are doing something
advanced that does require multiple threads, be sure to make it thread
safe and manipulate Swing components from within the event dispatch
thread. Java Virtual Machine implementations of threading are not
consistent so code that works in your test environment may fail elsewhere
unless you are careful. Unless the documentation explicitly states that
methods are thread safe, you should assume that they are not.
Discuss this article in The Big Moose Saloon!
Return to Top
|
Positioning Your Software Product - Part I
by Rick Chapman
The first chapter of "The Product Marketing Handbook for
Software" starts with a description of how to position your product for a
very simple reason: proper product positioning drives all aspects of your
marketing and sales efforts. Improperly position your software and despite the
quality of your product, the design of your collaterals (either web-based or
paper), the abilities of your sales force, all of your marketing and sales
programs will immediately begin to misfire. Improper product positioning can
wreak enormous havoc on a company. For example, a fundamental positioning
mistake made by my first employer in the industry, MicroPro, publisher of what
was once the world's most popular word processor, WordStar, literally destroyed
a $67 million dollar company in the span of 18 months.
Over the last two decades literally dozens of books and
articles and thousands of pages have been dedicated to explaining product
positioning to the masses. In the chapter in my book "In Search of Stupidity: Over 20
Years of High-Tech Marketing Disasters" that describes the havoc MicroPro
unleashed on itself by releasing two products with the same name, price, audience
and functionality at the same time, I describe one of the most popular and
widely used explanations. This is marketing guru Regis McKenna's take on
product positioning. He believes it is a:
" ... psychological location
in the consumer's mind, pertaining to the relative qualities a company,
product, or service may have with respect to its competitors."
The only trouble with this approach is that software is, by
its nature, an abstraction, a stream of electrons coursing through your
computer or perhaps the Internet. You can never "see" a software application
before interacting with it. For this reason, assigning a product a "visceral"
or physical identity is very important. Too many times you'll see software
products described as being the "best in their class," or the "fastest" or the most
"reliable" without anyone having any clear idea of what the software actually
does. A classic example of this is Lotus Notes. When the product was first
introduced, few potential buyers knew what it did. Lotus was aware of the
problem, and in a display of unintended humor, even talked about the issue in
their documentation:
?"What Is Notes Anyway?
People have been asking that question since the
beginning of time (or at least since Notes first came onto the market). It has
been hard for people to define Notes because you can use it to do so many
things."
?From the Notes 4.0 Beginner's Guide, published in 1996
By the way, the manual never
DOES explain what Notes "is."
As a result of the confusion, Note's market acceptance was
very slow, a fact that allowed Microsoft to catch up in sales to it with
Exchange. When Exchange was first introduced, Microsoft positioned the product
as a "post office" in your computer, an easy concept for buyers to grasp. On
the strength of this positioning, Microsoft was able to limit Lotus' success
with Notes. Yes, Notes did eventually become a solid seller, but when Lotus
first released the product it had expectations it would become a "killer app,"
something the product's unclear identity to buyers made impossible.
Assigning software a physical identity is not usually very
difficult (though it can be tricky with certain products) but despite all the
ink spilled on the topic, many companies and marketing "experts" continue to
get software positioning wrong. For instance, I attended the recent Software
Business magazine conference held in September in San Francisco and sat through
a presentation given by a consultant who specializes in high-tech "messaging." At
one point, his presentation focused on Microsoft's rollout of Windows 3.X in
the early 90s. During his presentation, he showed two slides. The first was
filled with a fair amount of jargon and wordy gobbledygook. This, the presenter
claimed, was Microsoft's original positioning statement. The second slide, he
claimed, represented Microsoft's new, successful positioning strategy. It
stated that:
"Windows 3.X Will Transform the Way You Use Your Computer"
This is wrong. This is not a "positioning" statement?this is
a tag line. You can tell by the generic nature of the phrase, as it can be used
to describe ANY product. For instance:
"Binky 3.X will transform the way you use mapping software."
"Binky 3.X will transform the way you manage shipping schedules."
"Binky 3.X will transform the way you live your life."
And so forth.
Now, how exactly did Microsoft position Windows 3.X? It was
very simple. They said:
"Microsoft Windows (finally) makes your PC work like a Mac
(for a lot less money than a Mac)."
Now, if you want, you could use the tag line:
"And thus transforms the way you will use your PC."
In the context of the events surrounding the early 1990s, this
was a powerful statement. The Macintosh had been on the market since 1984,
everyone who was interested in a desktop computer knew what a Mac could do (and
what a PC running DOS couldn't), and IBM had just spent the last several years
bungling the release of OS/2 (a complete chapter in "In Search of Stupidity" is
dedicated to examining what may be high-tech's biggest fiasco). All that
Microsoft had to do was produce a product that was good enough to stand up to
the market's scrutiny of its claim about Windows working just about as well as
a Mac. Despite the beliefs of Microsoft haters and Macophiles, Windows passed
that scrutiny and the rest is history.
Later that evening I had a chance to put my product
positioning techniques to work. In addition to writing books on high-tech
history and marketing, I'm also the managing editor of Soft*letter, a bimonthly newsletter
dedicated to examining all aspects of the software business. As I was handling
out a free sample of the publication at a show reception, I was approached by a
gentleman with some questions on how his company could position their software
product.
"OK," I said, "can you first tell me what your software
product does?"
"Sure, " he said. "It Bzzzzz application Zaaaappppiinn
integration MOM Bzzzz diagnostics errrrburrr help desk Xxxxx network
architecture."
I blinked at him. "Uh, again, what does your software do?
How would I use it?"
"Bzzzzz application Zaaaappppiinn integration?"
"No, wait, stop. What does your software product work with?"
"Applications."
"And how does it work with applications?"
"It monitors them."
"And where does it monitor them?"
"It monitors them on a network."
"And what precisely does it monitor about the applications?"
"It monitors them for their functionality. If an application
crashes, it informs a help desk that the application has crashed."
"What else does it tell the help desk? "
"It provides diagnostics that describes the network and user
environment when the application crashed."
"OK, that's better. So, how about this? Your application
functions as a sort of virtual fireman on call. He monitors your network for
application problems. When a program crashes and burns, the fireman tells you
that there's a fire and provides helpful information that will assist you in
putting the fire out."
He looked at me thoughtfully for a moment. "You know, we
paid some consultant six thousand dollars to come out and talk to us about our
software. We talked about the fire, but never got to the fireman."
In part two of this article, we'll take a look at some
contemporary positioning failures (including one by Microsoft) and discuss how
to fix a positioning mess.
Merrill R. (Rick)
Chapman is the publisher and managing editor of Soft*letter and Software Success
newsletter. In addition to the aforementioned publications,
Soft*letter also publishes the Soft*letter Financial Handbook and the
Services Marketing and Metrics Handbook. Rick has worked in the
software and high-tech industry since 1978 as a programmer, salesman,
support representative, and consultant for many different companies,
including MicroPro, Ashton-Tate, IBM, Inso, Bentley Systems, Berlitz,
Hewlett-Packard, and Ziff-Davis. He has held senior marketing and sales
positions at a variety of high tech companies including AGA, Stromberg, and
Miacomet.
Rick is also the
author of "The Product
Marketing Handbook for Software" and "In Search of Stupidity: Over 20
Years of High-Tech Marketing Disasters" and is the co-author of
the Software Industry and Information Association's US Software Channel
Marketing and Distribution Guide. He is currently at work on a new
book on marketing and selling open source software.
Return to Top
|
The Big Moose Saloon Question and Answer of the Month
Mosey on in and pull up a stool. The
JavaRanch Big Moose Saloon is the place to get your Java questions answered.
Our bartenders keep the peace, and folks are pretty friendly anyway, so don't
be shy!
The Topic: Pair Programming is NOT always a choice
Over in the Process forum, Sonny Gill found relief in a recent blog entry from Kathy Sierra:
Phew! I am not alone, I mean I am not the only one who is alone!! What a relief.
I was referring to being a bit of a loner in general, and not specifically in relation to Pair Programming. I also find that, although I am perfectly ease at being in company of other people, often I prefer not to. For me, staying at home reading a good book, or getting together with one or two friends at a quiet place is as much fun ( if not more), as going out and meeting with a large group of people. And I find it really strange when some people think that there is something wrong with that.
Now from my limited knowledge of PP, although pair programming is not a standard practice at my work place, I find that I am really uncomfortable working if there is somebody sitting right beside me looking at it all the time.
But, I have no problem going through any code that I have written with someone trying to find problems or explaining it etc. And that piece of code can be as small as a 10-20 lines long method, but while I am writing I prefer to be alone.
So, I am fine with a practice where, for example, I spend 30 minutes writing some code, and then I spend 10 minutes with someone going through it, and then back to coding on my own.
Sixty-seven replies later, folks are still chimin' in with thoughts and experiences.
Now, mosey on o'er, see what folks are saying and chime in with some thoughts of your own.
Join this discussion in The Big Moose Saloon!
Return to Top
|
Book Review of the Month
Pragmatic Project Automation
Mike Clark |  |           | |
If you're involved in any type of commercial Java projects, you owe yourself to pick up this book. I'm not kidding.
"Pragmatic Project Automation", the third book in the Pragmatic Programmers' Starter Kit series, authored by Mike Clark, is an invaluable asset for automating the grunt work of your Java development projects and raising your standards regarding quality, lead times in bug fixing, and eventually, the motivation of your whole team.
I read the book over a weekend in two sittings and enjoyed every minute of it. Mike has put together a series of high quality tutorials for setting up a repeatable build process using Ant, scheduling the build process using shell scripts, cron/at, and eventually CruiseControl, while keeping in the spirit of pragmatic thinking. He then continues by showing how to automate your release process and software deployment -- with both simple shell scripts and an open source graphical installer tool. To finish, he talks about different techniques for monitoring your software for errors.
I honestly couldn't find anything to complain about this book -- except that I wouldn't have minded reading another 150 pages of it.
(Lasse Koskela - Bartender, September 2004)
| | |  | | |
This little book could double your productivity by showing you how to make computers actually help you do your job. Do you spend too much time chasing configuration bugs, following checklists, and performing repetitive tasks that take time away from your coding and design duties? Then "Pragmatic Project Automation" is for you.
This isn't the kind of "software process" book that tries to sell you on following a methodology. There's no preaching, and there are no outlandish claims of productivity increases. Instead of selling snake oil, Mike Clark just wants to explain, in a clear, effective way, how to use open-source tools to automate your builds, release process, and application monitoring. Java tools like Ant, CruiseControl, and JUnit are the centerpieces of this book, but shell scripts and batch files also make cameo appearances.
There's even a section on assembling novel monitoring devices. Admit it -- wouldn't it be cool to have red and green Lava Lamps that light up according to the status of your project build?
The beginning programmer might wonder what all the fuss is about, but anyone tasked with delivering software on a schedule will appreciate the many ways in which this book will help them.
(Ernest Friedman-Hill - Sheriff, August 2004)
| | |
More info at Amazon.com ||
More info at Amazon.co.uk
| |
Other books reviewed in
September :
| Contributing to Eclipse - Principles, Patterns, and Plug-Ins by
Erich Gamma, Kent Beck | | User Stories Applied: For Agile Software Development by
Mike Cohn | | JUnit Recipes: Practical Methods for Programmer Testing by
J.B.Rainsberger, Scott Stirling | | How Tomcat Works by
Budi Kurniawan, Paul Deck | | Beginning PHP 5 and MySQL From Novice to Professional by
W. Jason Gilmore | | J2EE1.4 The Big Picture by
Solvieg Haugland, Mark Cade, Anthony Orapallo | | Dive Into Python by
Mark Pilgrim | | The Pragmatic Starter Kit by
David Thomas, Andrew Hunt | | The Product Marketing Handbook for Software by
Merrill R. Chapman | | Decompiling Java by
Godfrey Nolan | | Pro Jakarta Commons by
Harshad Oak | | Eclipse: Building Commercial-Quality Plug-ins by
Eric Clayberg, Dan Rubel | | The Definitive Guide to Linux Network Programming by
Keir Davis, John W. Turner, Nathan Yocom | | Beginning JSP 2: From Novice to Professional by
Peter Den Haan, Lance Lavandowska, Sathya Narayana Panduranga, Krishnaraj Perrumal |
Discuss this book review in The Big Moose Saloon!
Return to Top
|
|
Following are the scheduled promotions coming in October and November. Be sure to check our promotions page often for changes and new promotions. Participate in a promotion and you might win a copy of a book!
| October 19 |
 Java 1.5 Tiger : A Developer's Notebook Java 1.5 Tiger : A Developer's Notebook |
Brett McLaughlin |
O'Reilly |
Java in General (intermediate) |
| October 19 |
 Head First Servlets & JSP Head First Servlets & JSP |
Bryan Basham, Kathy Sierra, Bert Bates |
O'Reilly |
Web Component Certification (SCWCD) |
| October 19 |
 Java Threads, 3rd Edition Java Threads, 3rd Edition |
Scott Oaks, Henry Wong |
O'Reilly |
Threads and Synchronization |
| October 26 |
 Whizlabs XML Certification (IBM Test 141) Simulator Whizlabs XML Certification (IBM Test 141) Simulator |
Hari Vignesh Padmanabham |
Whizlabs |
XML Certification |
| October 26 |
 Spring Live Spring Live |
Matt Raible |
SourceBeat.com |
Web Application Frameworks |
| November 2 |
 Enterprise Java Development on a Budget: Leveraging Java Open Source Technologies Enterprise Java Development on a Budget: Leveraging Java Open Source Technologies |
Brian Sam-Bodden, Christopher M. Judd |
Apress |
Other Open Source Projects |
| November 2 |
 Oracle Application Server 10g: J2EE Deployment and Administration Oracle Application Server 10g: J2EE Deployment and Administration |
Erin Mulder, Michael Wessler |
Apress |
Oracle/OAS |
| November 2 |
 Practical WebObjects Practical WebObjects |
Charles Hill, Sacha Mallais |
Apress |
Web Application Frameworks |
| November 9 |
 Building Portals with the Java Portlet API Building Portals with the Java Portlet API |
Jeff Linwood, David Minter |
Apress |
Web Application Frameworks |
| November 9 |
 Pro Jakarta Velocity: From Professional to Expert Pro Jakarta Velocity: From Professional to Expert |
Rob Harrop |
Apress |
Other Open Source Projects |
| November 16 |
 Core Java 2, Volume I - Fundamentals (7th Edition) Core Java 2, Volume I - Fundamentals (7th Edition) |
Cay Horstmann, Gary Cornell |
Prentice Hall PTR |
Java in General (intermediate) |
| November 23 |
Mastering the Fundamentals of the Java Programming Language, Volume 2 |
Doug Dunn |
TBA |
Java in General (intermediate) |
| November 30 |
 Java 2: The Complete Reference, Sixth Edition Java 2: The Complete Reference, Sixth Edition |
Herbert Schildt |
McGraw-Hill Osborne Media |
Java in General (intermediate) |
Return to Top
|
Managing Editor: Dirk Schreckmann
|