|
Looking "Under the Hood" with javap by Corey McGlone There's a utility that is included with the Java Development Kit that I find is seldom used but can be remarkably handy. In fact, I almost never used it until it came time for me to study for the SCJP exam. That utility is called javap and it is used to disassemble Java bytecode, which is in a binary format, into a readable form. Most people know that, when you compile your .java files, they become .class files but most people never bother to look at what is actually produced. Sometimes, what you can find in your bytecode can be quite enlightening. Learning to Read BytecodeLet's start with a simple Java program and see what the bytecode looks like. (Note that bytecode will vary from compiler to compiler - for the purpose of this article, I'm using Sun's compiler, javac 1.4.2). Once you've compiled your program, simply use the command javap -c [ClassName] to view the bytecode (The -c switch indicates that you want to disassemble the code). In my case, the command I used was javap -c SimpleProgram. There are other switches you can investigate on your own by using the command javap -help.
Certainly, it's a simple program, but we can learn a lot about bytecode from just this little example. Notice that there are two methods in this bytecode, SimpleProgram and main. But where did that first method come from? We only defined one method in our program and that was main so why do we now have two? Well, that first method, named SimpleProgram, is the default constructor that is automatically supplied in the case that you don't provide a constructor. Just as you'd expect, that default constructor is public and takes no arguments. So, now if you've been told that default constructors exist, you can see it first hand - they're generated by the compiler and put directly into your bytecode. Let's really get into the guts of this bytecode and look at the internal parts of these methods. Let's start with that default constructor by looking at the makeup of a line of bytecode. Let's start with the first line: 0: aload_0The first value, 0, is the offset of the instruction from the beginning of the method. As you can see, the first instruction is marked with a 0 and, for what we'll be discussing here, that number is quite inconsequential. The rest of the line is a bit more interesting in that it contains an operator (sometimes called an opcode) and any arguments for that opcode, if applicable. In our first line, we're going to push a value from the "local variable table" onto the stack. In this case, we're really only pushing the implicit reference to "this" so it isn't the most exciting instruction. So what do you think this next line does? 1: invokespecial #1; //Method java/lang/Object."Well, what do you know about constructors? What's the first thing a constructor does? It invokes the parent class' constructor. That's just what this line does - it invokes the constructor of the parent class (in this case, Object). What's with the #1? Well, that is really just an index into a constant table. Index #1 apparently references the constructor of Object. Finally, the last line returns us from our constructor. Certainly, it's not a very exciting method, but it does help us along our way to understand bytecode. Let's look at the next method, our main method, to get a little more into bytecode. Let's go through this bytecode line by line, much like we did above. When we're done with this, you should have a decent understanding of how to make heads or tails of bytecode. 0: getstatic #2; //Field java/lang/System.out:Ljava/io/PrintStream;This line include the opcode getstatic. As you might guess, this opcode gets a static field (in this case, System.out) and pushes it onto the operand stack. As you might have guessed, that #2 refers to that field in our constant table. Let's go on to our next line. 3: ldc #3; //String Hello World!This line uses the opcode ldc, which loads a constant onto the operand stack. At this point, we're going to load whatever constant is in index #3 of our constant table. That constant is our String, "Hello World!". Going forward, we run into this line: 5: invokevirtual #4; //Method java/io/PrintStream.println:(Ljava/lang/String;)VThis line invokes the method println of our object System.out. The process involved here is to pop the two operands off the stack and then execute the method. At this point, our method is over and we return. Investigating Strings vs. StringBuffersWell, there you have it, a quick introduction to reading some bytecode. Now let's see how this can actually be useful to you. You've probably all heard that you should use StringBuffer objects when you have to do String manipulation because Strings are immutable. Let's make our bytecode prove just how true this is. We'll start with a program that defines two method that both append Strings to one another. One method will use Strings while the other will use a StringBuffer.
Well, we can safely ignore the default constructor, but take a look at those two methods, concat1 and concat2. Wow! What a difference! If you look at concat1 as bytecode, you can see that we first create a StringBuffer object and append the first String to it and then append the second String to it, as well. Then, when we're all done with that, we create a String from that StringBuffer and return that new String. Seems like a lot of work to do something so simple - and wasteful, too. Notice that the final return is a full 18 instructions from the start of the method. Now look at the second method. See how nice and compact that one is? Because we're already working with a StringBuffer, there's no reason to create a new one. We simply append the String to the one we have now and return from the method. In this case, our return method is a paltry 6 instructions from the beginning of the method. Well, if someone telling you to use StringBuffer instead of String for maniuplation wasn't enough, I hope this proved why you should. However, there is one caveat to this. With the inclusion of "Just in Time" compilers, further optimizations can be made to your bytecode and it's possible that the first method will end up looking just like the latter. However, you have little to no control over this and it's in your best interest to practice good, conscientious programming techniques rather than to rely on some compiler. Using the String Literal PoolLet's look at one more example in which we can see something quite interesting by examining bytecode directly. Quite often, people in the SCJP forum ask about String literals and how they are handled. A String is an object, but the fact that it is immutable makes it a somewhat "special" case. Let's look at a simple program using String literals and see what the resulting bytecode looks like.
Once again, let's skip over the default constructor - let's look at the main method. Take a look at lines 0 and 2: 0: ldc #2; //String Test 2: astore_1What is this doing? Well, we know that the opcode ldc is going to load a constant. We're grabbing a constant from our constant table and pushing it onto the stack. The next opcode, astore_1, pops that value off the stack and stores it in the local variable table. Now, the real kicker here is to compare these two lines against the next 4 lines. Here are all 6: 0: ldc #2; //String Test 2: astore_1 3: ldc #2; //String Test 5: astore_2 6: ldc #2; //String Test 8: astore_3Well, take a look at that. All three sets look just about identical. The only difference is that each one is going into a different part of the local variable table (which only makes sense since we're using 3 local variables). So what does this tell us about how Strings are handled? This tells us that, in the constant pool, there is a reference to a String that contains the value "Test". That reference just got assigned to 3 different local variables. This means that all 3 local variables, one, two, and three, all reference the exact same String object. This is the sharing that is performed by the "String Literal Pool." Notice, also, that there is no use of the opcode "new" in those 6 lines. So when did the String get constructed? It was constructed when the class was loaded. Now, let's look at the final few lines of the bytecode: 9: new #3; //class String 12: dup 13: ldc #2; //String Test 15: invokespecial #4; //Method java/lang/String."Why do these lines look so different? Well, take a look back at our main method. When we assigned a value to the String variable four, we used the keyword "new." This caused a new String to be created at runtime, rather than reusing the String that was created when the class was loaded. So, when we finish executing these four lines of our main method, we would have a situation that looks like this (a bit simplified, but you get the idea): 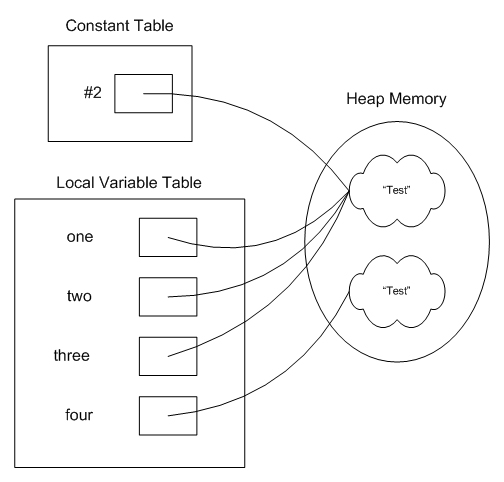 ConclusionWell, that's it for my little intro to using javap to investigate Java bytecode. This is really just scratching the surface of all you can do. If you'd like to know more about the bytecode spec, be sure to check out the Java Virtual Machine Specification. (§3.11 Instruction Set Summary is especially useful for interpreting bytecode.)I found that, especially when studying for the SCJP exam, when I was confused, it was often helpful to look at the bytecode directly to see what was really happening when my code was executing. I always find it interesting what little tidbits I can unearth when using javap to look at the bytecode directly. Hopefully, this will just add another tool to your bag of tricks as a software developer. Certainly, this isn't something I use every day but, when I find the need, it's a handy tool to have available to you. Remember to tune in to the SCJP Tipline for more updates. Return to Top |
||||||||||||
|
Thomas B. Passin by Dirk Schreckmann JavaRanch: Thomas, you recently published a book titled "Explorer's Guide to the Semantic Web". It's likely no surprise that my first question is, "What is the Semantic Web?" Thomas: It's hard to give a concise answer because there are so many different ideas about what the Semantic Web is all about. The first chapter in my book talks about these views in some detail. It turns out that they do have some things in common. Here's how I put it on JavaRanch a few days ago "The idea is that there are a lot of things that we do on the web today that could be automated if only ... if only computers could understand the data better (HTML has to be read by people for much of its meaning to be available)... if only a software agent could act for you... if only searching could be smarter... and so on. "The Semantic web is really intended to increase the amount of help that computers can give us, to relieve us of some of the more time-consuming and mundane tasks, to handle details that require information (on the Web) that is currently implicit but not really available to software as things are now." The key element here is to have computers be able to make better use of data on the Web that is out there but not very accessible to computers today. Then we ought to be able to get the computers to do good things for us with much less need for us to do all the steps ourselves. The shorthand way to express this thought is to say that "Computers will understand the meaning of data on the Web." But remember that the sense of the words "understand" and "meaning" may be pretty loose. JavaRanch: Could you expand on what you mean by, "...the sense of the words "understand" and "meaning" may be pretty loose?" Thomas: I'd rather not! Seriously, these words are very hard to define, and usually lead to arguments, heavy philosophical discussion, or both. What I meant by "loose" is that a system can respond to some situation in an appropriate way without "understanding" it in any normal human sense of the word you might pick. For example, a statistical spam filter does not have any notion of the sentence structure in an email, nor of the "meanings" of the words, yet it may do a good job of filtering out the spam. On the other hand, another kind of filter might in fact have some knowledge of the appropriateness of words and phrases given the context of the rest of the email. We might say that this second system has a higher level of "understanding" of the email and of spam than the first. But strictly speaking (at the level of theories of meaning, say), this kind of understanding would still be pretty far from what we imagine that humans do. So I say "loosely". I think we should leave it at that, especially since we really don't know much about what human-style "understanding" or "meaning" really is or how it works in our heads. JavaRanch: How intelligent or sophisticated will these agents need to be? Thomas: For some of the advanced scenarios, very sophisticated. I think that mid-range progress will be more likely to come from trying to learn how to make as much mileage as possible from less sophisticated or intelligent agents. JavaRanch: What's a classic example scenario of using this Semantic Web in the future? Thomas: Classic scenarios often involve some kind of an "agent" that makes arrangements for you. For example, you are traveling abroad and your plans change. The agent finds flights to the new destination, makes sure the connections will work, books the tickets, makes new hotel reservations for you, and offers up a list of restaurant suggestions for tomorrow's dinner. It knows enough to look for vegetarian restaurants because it knows your food preferences, and it can check the menus in several languages by means of multi-lingual ontologies. JavaRanch: Do you have an idea for a use of the Semantic Web that perhaps strays a bit from the classic examples? What will we be doing with it that we perhaps don't currently expect to be doing with it? Thomas: Here's a Semantic Web style capability that I would really like to have, but I haven't seen written about. It involves a system for annotating on-line material. Imagine that you are reading some work in your (semantically advanced) browser. You highlight a passage and write an annotation that is, perhaps, several sentences long. Behind the scenes, the system analyzes both the surrounding passage and your annotation to arrive at an understanding of the context for and content of your note. Then, over a period of minutes, hours, or maybe even days, it goes out on the web and performs semantically-enhanced searches for material relevant to your note. It communicates with other annotation agents, monitors relevant URLs for changes, and so forth. Eventually, when the system has integrated enough data, it presents you with a selection of information relating to your note and possibly to the surrounding text as well. This might well be information you had known nothing about. A really advanced agent might even offer suggestions about the validity of your annotation! Ultimately, your note along with a selection of the enhanced material, would become available for others to see as well. JavaRanch: Who is behind the Semantic Web? Is this the brain child of an individual, or small group of individuals? What larger organizations are developing it today? Are any particular interests (such as scientific groups, some part of the government, library organizations, big business) behind it? Thomas: Well, Tim Berners-Lee first articulated the term and vision of a "Semantic Web". He seems to have seen it as a natural extension of the current Web. The W3C (World Wide Web Consortium), which of course he heads, eventually established a Semantic Web activity. There has been a fair amount of academic work in the area, and DARPA, the U.S. Defense Advanced Research Projects Agency, has funded related work in ontologies (e.g., DAML, which later morphed into the W3C's OWL) and in autonomous agents. Generally speaking, "big business" has not shown a lot of interest, but there are some exceptions. HP has funded some important work in RDF tools, for example. In terms of governments, there is no government-wide push, but individual agencies are searching for help with problems that Semantic Web technologies could be helpful with. So, as usual, there is government funded or supported work but you can't really say that various governments are "behind it". The obvious areas for near-term payoff are in specifying ontologies and adapting several ontologies to work together, and in integrating disparate data sources. Governments and large businesses are starting to see how important these areas are becoming. One thing to bear in mind is that many Semantic Web technologies will be useful in themselves even if the Semantic Web itself never materializes in the form people are currently thinking of. JavaRanch: Was the WWW initially designed to evolve into this Semantic Web, or has it been more of an emerging concept, come to life as people have seen what the WWW can do and have dreamed about what the WWW could be doing in the future? Thomas: I would say mainly the latter, although Berners-Lee has written that he always had Semantic Web capability in mind, right from the start. But I am sure that his ideas evolved over time just like everyone else's. JavaRanch: How far are we from experiencing the Semantic Web more in our day to day lives? How much older will I be before I should expect my cell phone to make arrangements for my birthday party? Thomas: It's starting to sneak in, mostly in invisible ways. RDF, for example, is starting to get used a little more at a time, but behind the scenes where you cannot see it. There is a new (still in beta) application for organizing and sharing your photographs, called Tidepool, which eventually will let you tie the photos into stories you write about them. Sun Microsystems has had a substantial project that uses RDF to help capture and organize a lot of their distributed company knowledge. I'm told that in the course of doing this, they were able to discover "islands" of knowledge that were related but not previously strongly connected. But having capabilities for making smart arrangements, arrangements that require common sense, that will take a lot of doing, for sure. So that's not right around the corner, not by a long shot. In addition to the technical challenges, there is the whole issue of trust and security on the Web. We know that is hard even when people are closely involved, let alone when "smart" agents will be out there interacting on their own. JavaRanch: Could you expand on the issues of trust and security? Does current Semantic Web thought suggest that any particular security mechanisms will dominate in the agent arena? Thomas: Most of what I read has to do with either:
JavaRanch: What could we be doing at JavaRanch, with our web site, to be moving towards this Semantic Web? Could we be annotating content to better provide machines with a mechanism to understand things? Who might benefit from this, today? How so? Thomas: It's a bit hard to say without taking into account what you would like to do, what directions you want to go in. Generally speaking, there are things you can do that would set you up to use Semantic Web technologies are they become more capable, things that would cost very little and would have some value on their own. For example, you could promote more effective searching of material - say, of questions and answers in the forums. You see more and more of this in the better blogs - say, Jon Udel's blog and Ongoing, just to name a few. Generally, more use is being made of keywords. The del.icio.us site (http://del.icio.us) lets users add their own keywords and apply them to bookmarks. This provides for the group to share bookmarks on common subjects. But almost no one talks about the difficulty of using and maintaining keywords as their numbers get large. This can be hard. I have tackled this problem for my own collection of bookmarks, using a topic map application I wrote (available on the Sourceforge project "TM4JScript"), so I know that one can do a lot better without a huge effort. I'd have to say that we don't know the best ways to annotate sites to improve search yet. Jon Udel has been exploring this subject in his columns on InfoWorld, and they are worth reading. Generally speaking, RDF and Topic Maps are good for piecing together bits of information from different sources (among other things). You can also arrange an overlay - RDF or Topic Maps - onto relational data, meaning you can make it look like it is, say, RDF. This approach provides a way to integrate various data sources, although I don't know how JavaRanch is organized so I can't say if this would fit in. I have started to advocate a few strategies that I think will help position people to take advantage of some Semantic Web capabilities in the near future. First, the next time you decide to create a new XML format for data, bear in mind that it is often easy to make slight modifications and turn it into legal RDF. The XML syntax for RDF is frequently disparaged (think "rant"), but you don't have to use all the features by any means. If you take this approach, you get XML data that looks "normal", that can be handled by regular XML processing methods, and that can also be processed by RDF processors. For practically no cost, except for a bit to time getting up to speed on the technique, you can have the benefits of both XML and RDF. In addition, the thought needed to make sure you have proper RDF tends to help you understand your requirements better, anyway. In a similar way, the next time you decide you need to create a new vocabulary, you can do it in OWL. OWL can be written in RDF, and just as above, you can make your OWL files easy to process with regular XML techniques. Again the cost is low, although I do have to say that your mind will probably need to get a little twisted around to get used to the OWL way of doing things. But that was true when HTML came in, too, and we all got used to that. With OWL, you can express your vocabulary with quite a bit of what is called "expressiveness", you can convert it into other forms, such as HTML documentation without much effort, and you are using a standard. Now I won't claim that RDF and OWL processing - today - will necessarily add that much, but in the near future, as the RDF databases and query languages and logical reasoners evolve (which is happening rapidly), the value will start to emerge. In the meantime, if you are going to create file formats and vocabularies anyway, no harm done if you do it this way. So potentially, sites can be better organized and especially navigated (navigation links can often be provided right out of a topic map if there is one for the data a site is built from), keywords and categories can be better managed, searching can be improved (even though we don't know the best ways to accomplish this yet), and it can be easier to aggregate information. For example, if we know that Python is a computer language, then a search for computer languages would turn up hits about Python even if we did not explicitly ask for it. Yes, that can be done today without RDF, etc., if you want to do it enough to take the trouble. But technologies like RDF, Topic Maps, and OWL give you a leg up because they are standardized, and so you only have come up with the data model and not all the rest of the machinery as well. JavaRanch:What needs to happen in order for my smart PDA to arrange my travel plans? Will the future Semantic Web agents require any data they use to be described in RDF and OWL? Thomas: That's unclear at this point. Certainly many very visible people think (or at least talk as if they think) that mostly it will be RDF and OWL. However, I see more and more people writing about the importance of natural language techniques and other text processing to handle the vast amount of data that will never be marked up or be in RDF/OWL. Of course, the output of such processing may be RDF. JavaRanch: Thanks for the interview, Thomas! Thomas Passin is Principal Systems Engineer with Mitretek Systems, a non-profit systems and information engineering company. He has been involved in data modeling and created several complex database-backed web sites and also became engaged in a range of conceptual modeling approaches and graphical modeling technologies. He was a key member of a team that developed several demonstration XML-based web service applications, and worked on creating XML versions of draft standards originally written in ASN.1. He graduated with a B. S. in physics from the Massachusetts Institute of Technology, then studied graduate-level physics at the University of Chicago. He became involved with XML-related work in 1998, with Topic Maps in 1999 and developed the open-source TM4JScript Javascript topic map engine. Thomas Passin is the author of the book, "Explorer's Guide to the Semantic Web", Manning Publications, March 2004. Return to Top |
||||||||||||
Embrace Writing Script-less JSPby Bear Bibeault More and more as of late in the JavaRanch JSP Forum, I've been encouraging people to embrace writing script-less JSP pages; something much easier to do under JSP 2.0 than ever before. Many have come to a similar conclusion as myself, that this is A Good Thing™; others are, as yet, unconvinced. And still others would like to believe, but get frustrated when they find themselves stumped by something they can't figure out how to do using the JSTL and the EL. This article is aimed primarily at this latter audience. I'm not going to say I've given up on trying to convince the former segment, but I don't think that anything I could write in a journal-sized entry would do much in the way of convincing. Most of the frustrations I field seem to stem from some "wrong thinking" about JSP 2.0, the JSTL and the EL. This "wrong thinking" can be summarized by: "Given the data structures available to the page, I can't get the JSTL and EL to do such-and-such." The "correct thinking" should be: "How should the servlet controller1 set things up so that I can easily do what I want on the page?" This is a different way of thinking about things than back in the Ice Ages when we put Java in the JSPs willy-nilly. Back then, even when we used servlet controllers, they were usually relegated to database access and not too much attention was paid to the formats of the data that got sent to the page. After all, we could use the full power of Java to access the data in any way that we wanted. Then came the JSTL and, in particular, the EL, and things have changed. Not radically mind you, but enough to make us look at the controller/view interface in a slightly different manner; what I call a "30-degree shift" in thinking. The EL is deft at handling certain types of data, but not others. It's great with Java Beans and collections, but not so good with plain-old unpatterned classes. It behooves us, therefore, to put the "smart thinking" in the servlet controller where we have maxium flexibility, and to make sure that we pattern the data that we are going to send to the page in such a way that the page can be as simple as possible. Let's look at one concrete example. In a JSP Forum topic post, one member complained that he wanted to list out all the application-level scoped variables and their values, and claimed that the JSTL was useless because it could not handle this task easily. Wrong thinking. Wrong, because he was thinking of how to make the page conform to the data, rather than the other way around. The problem stems from the non-EL-friendly pattern exposed by the ServletContext (and repeated by the other context scopes) for obtaining this data. In Java code, showing these values might look something like:
Enumeration e = servletContext.getAttributeNames();
while (e.hasMoreElements()) {
String name = (String)e.nextElement();
Object value = servletContext.getAttribute( name );
System.out.println( name + "=" + value );
}
In a scriptless JSP this is a problem because even though we can obtain the names of the scoped variables as an EL-friendly enumeration (using ${pageContext.servletContext.attributeNames}), you must make a call to a method that takes the name as a parameter in order to obtain the value. And that is something that the EL cannot do.2 So, if it is a requirement that the page show this information, "correct thinking" is to make it the controller's responsibility to set up the data in an EL-friendly manner. The set of name/value pairs of the scoped variable to be displayed is a natural fit to a Map, so in the controller I would collect and expose the data as such:
Map attributeMap = new HashMap();
Enumeration e = servletContext.getAttributeNames();
while (e.hasMoreElements()) {
String name = (String)e.nextElement();
attributeMap.put( name, servletContext.getAttribute( name ) );
}
request.setAttribute( "applicationVariableMap", attributeMap );
And in the JSP page, rendering this data is incredibly simple, easily readable, and easily maintained as:
<c:forEach items="${applicationVariableMap}" var="entry">
${entry.key} = ${entry.value}<br/>
</c:forEach>
With about half a dozen lines of code in the controller, we have made this seeming on-page headache just go away. To summarize: "Ask not what your page can do for you, but what your controller can do for your page." 1 If you are not using a Model 2 pattern with servlet controllers, you are (in my opinion) doing it wrong. 2 Someone is sure to point out that with JSTL 1.1 it is possible to define functions that can be accessed from the page. To me, that is an action of last resort, and would involve more, and certainly less straight-forward, code than what I am proposing here. Return to Top |
||||||||||||
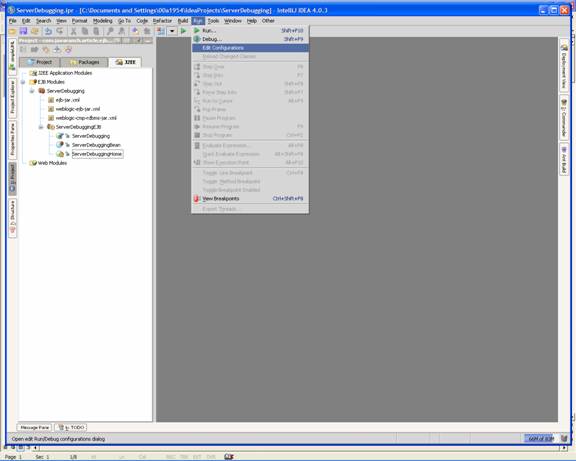
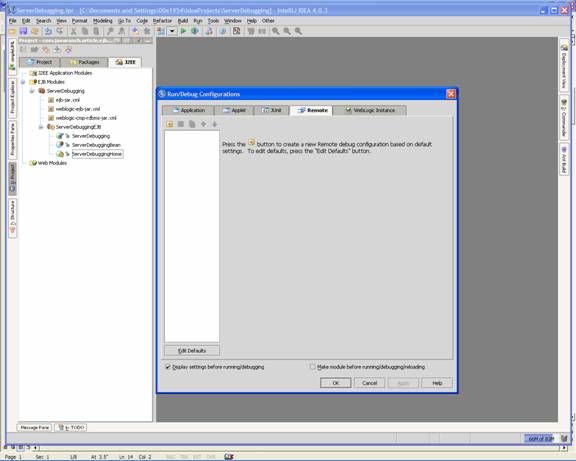
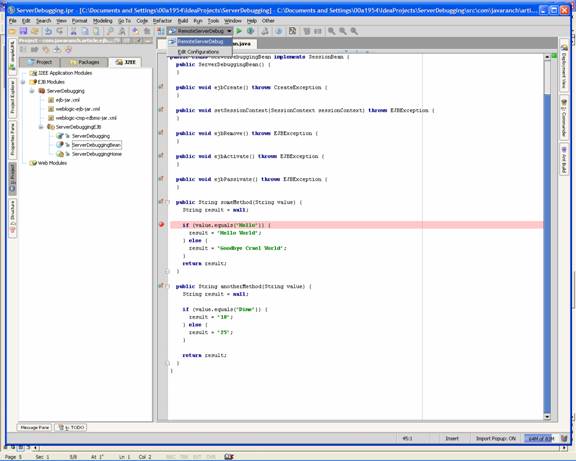
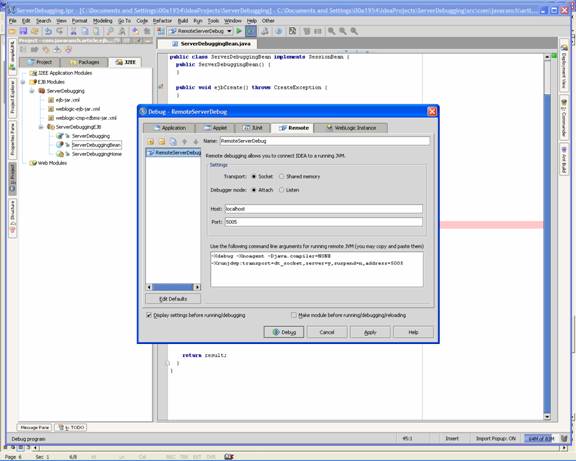
Debugging Server-side Code through IntelliJ IDEA with BEA Weblogic 8.1by Mark Spritzler In order to debug server-side code you must start your (app) server in debug mode, and you must have your IDE connect to the remote JVM through a Remote Server Debug configuration (That's what it is called in IDEA). Other IDE's should have something very similar to this that will allow it to "hook" into the remote JVM and find out the calls that are being made, and to stop the code when it hits a breakpoint that you have set in the IDE. How to create a "Remote Server Debug configuration".
This command line is what is needed to start the Application Server in debug mode, see "To set the server to startup in debug mode."
To set the server to startup in debug mode.
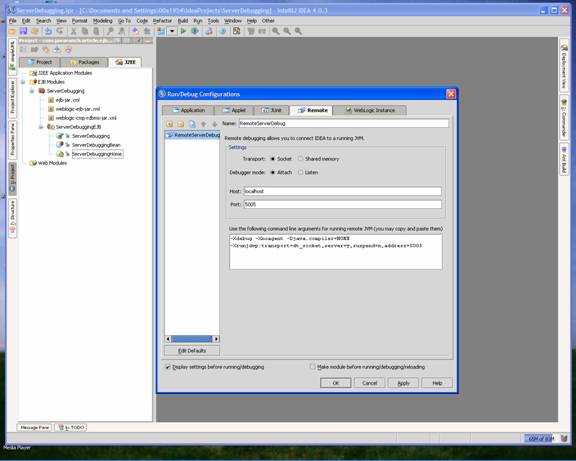
-Xdebug -Xrunjdwp:server=y,transport=dt_socket,address=5005,suspend=n This code is a little different than what you get from IntelliJ, but when I was setting up my machine, I ran into a problem and using the above worked for me. However, I would try using what you get from IntelliJ IDEA first, as that is what should be in the JAVA_OPTIONS. Example of the commEnv.cmd file where JAVA_OPTIONS is listed set JAVA_OPTIONS=%JAVA_OPTIONS% -Xverify:none -Xdebug -Xrunjdwp:server=y,transport=dt_socket,address=5005,suspend=n After changing the file, start or restart your App Server. When it restarts it will be in debug mode. Setting a breakpoint and watching IntelliJ IDEA stop the code in action. J
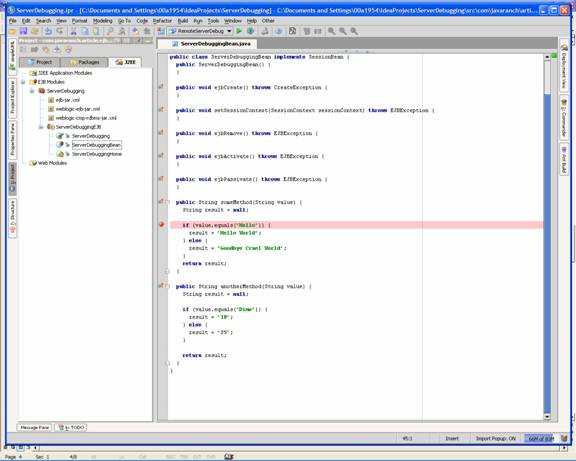
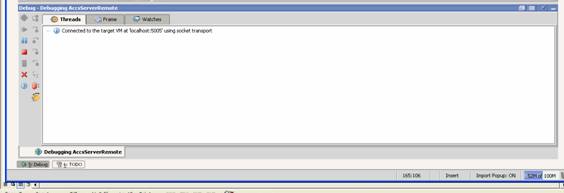
As you can see the red ball/dot on the left of the code is a breakpoint.
Congratulations, see now wasn't that simple. J Debugging on other IDEs. Now that we have covered how to set up and start a debugging session with IntelliJ IDEA and Weblogic server, lets talk about the other IDEs, like Eclipse, and Netbeans, and other Web Servers like JBoss and Websphere. These are just as simple. The configuration is almost identical. The only difference is what names they call their debugging configuration, in the case of the IDEs and which text configuration file the App server stores the call to the java command to start their server, and then include the ?X parameters to that line. In Eclipse, their debug configuration is called "Remote Java Application" which you will see after clicking the Green bug button on the toolbar. And just like in IntelliJ IDEA< you just give it a meaningful name. In IntelliJ IDEA, their Java_options for the server uses port 5005, but in Eclipse it is set for port 8000. Don't worry about this, as it is just a formality, and the only worry would be that you choose a port that is already in use. Either one of these ports will work fine for your configuration, they just have to match from on both sides. Restart your app server, set a breakpoint, and run your program in a DOS prompt, and bingo, you are stepping through code. For more information on your IDE or App Server, please check their respective websites and other documentation. Now that you know the basics, it shouldn't be hard to find more specific information. It is one of Murphy's law, that you can't find the information you want when you need it, but after you figure it out, you find the information everywhere. Good Luck and happy debugging. May all your bugs be easy to find. Return to Top |
||||||||||||
|
Mosey on in and pull up a stool. The JavaRanch Big Moose Saloon is the place to get your Java questions answered. Our bartenders keep the peace, and folks are pretty friendly anyway, so don't be shy! Question: Package-private and protected access, who needs 'em?Over in the OO, Patterns, UML and Refactoring forum, Jeanne Boyarsky (after some provoking from J. B. Rainsberger) opened a bottle of worms with this thread starter:
Now, mosey on o'er, see what folks are saying and chime in with some thoughts of your own. |