
Hacking JUnitAdding a simple extension to the JUnit test frameworkby E.J. Friedman-HillJUnit, if'n you don't know, is a popular unit-testing framework for Java (See http://www.junit.org/.) Using JUnit, you can easily write automated tests for individual Java classes and methods. A typical large project may have thousands or tens of thousands of individual JUnit tests. Here at the Ranch, we use JUnit for testing durn near everything. We like to run our tests often, to make sure our code is alive and kickin'. Many projects that use JUnit run their automated test suites as part of a nightly build process on multiple machines. Testing on multiple platforms is obviously a good idea, because it helps you find platform-dependent problems. Most projects should test on Windows, Linux, and Solaris as a bare minimum. For some software, testing on workstations from SGI, HP, and IBM makes sense, too -- and perhaps multiple versions of all of these operating systems, as well. Not every project can afford a whole herd of dedicated test machines, however. Often, test machines are shared between projects, and sometimes test machines are simply desktop or server machines that have some other primary purpose. In this situation, it may not be possible to set up all the test machines with an ideal testing environment. Indeed, some of the tests might not pass on all the machines, for predictable reasons. This is the problem Tex was facing. Pull up a camp stool and let me tell you about it. Tex was worried about his herd. He was riding out on the range, rounding up the scruffy herd of test servers. Every one was different, and truth be told, they didn't even all belong to him. He had to beg, borrow, and steal time on many of these machines so that he could test his Java software on many different platforms. His prize cattle, ah, servers, had ideal test environments set up. But the others -- the rare exotic breeds like the IRIX and HP-UX servers -- didn't have the right JDK versions. Other little dogies were missing some of the external software his application used -- it was just too durn expensive to buy for every machine in the herd. As a result, some of his JUnit tests failed on each machine. All the failures were expected, and due to the variation between the different breeds. But he was always scratchin' his head trying to keep all of these pecadillos straight. I'm fixin' to help Tex out. Saddle up and come give us a hand, as we extend JUnit so that each test case gets to tell JUnit whether or not it should be run on any given heifer, err, server. How JUnit worksTo write a test in JUnit, you extend the junit.framework.TestCase class and implement one or more methods named testXXXX, where XXXX describes the functionality under test. By default, the JUnit framework will create one instance of your class for each testXXXX method, and invoke these methods via reflection. Each invocation represents a single test. The TestCase class also contains methods called setUp and tearDown. You can override these to set up and dismantle a test scaffold for each test; JUnit will call them immediately before and immediately after calling testXXXX, respectively. Your class will inherit a fairly large API from TestCase. The inherited methods fall into two categories: methods that let you make testing assertions, which are documented elsewhere (see the book JUnit in Action,) and the lesser-known methods which let you extend the functionality of JUnit itself. We'll look at one such method here: public void run(TestResult result); JUnit calls this method to run the TestCase. The default implementation turns around and calls a method public void run(TestCase test); on the TestResult object. The TestResult arranges to record the success or failure of the test, keeps track of the number of tests actually run, and then turns around and calls public void runBare() throws Throwable; on the TestCase. This method, finally, is the one that actually calls the setUp method, invokes the testXXXX method by reflection, and calls tearDown. Customizing JUnitThis sequence of calls is complicated, but it give us lots of chances to stick in our own customized code. Because JUnit is so flexible, it's surprising how little code you need to write to add your own features. What we want to do is, somehow, help Tex out by having JUnit ask each TestCase object whether or not it should be expected to pass in the current environment. Let's extend TestCase to provide our own customized base class for tests. We'll add a method canRun which returns true or false according to whether the test should be run or not. We also need to provide a constructor that takes a test name as an argument; JUnit needs this constructor to put the tests together. package com.javaranch.junit;
import junit.framework.*;
public class JRTestCase extends TestCase {
public JRTestCase(String s) {
super(s);
}
public boolean canRun() {
return true;
}
}
Now, when you write a JUnit test case, you can extend this class and override canRun. Here's a test case that only makes sense when run under Windows: package com.javaranch.junit;
public class WindowsOnlyTest extends JRTestCase {
public DemoTest(String s) {
super(s);
}
public boolean canRun() {
return System.getProperty("os.name").
toLowerCase().indexOf("win") != -1;
}
public void testWindowsFeature() {
// Should run this test only on Windows
}
}
That's great, but of course JUnit doesn't yet care that we've defined the canRun method, and will run these tests on all platforms anyway. We can make running a test conditional on the result of calling canRun by overriding the run method from TestCase in JRTestCase: public void run(TestResult result) {
if (canRun())
super.run(result);
}
That's it! Now if we run this test on Windows, we'll see C:\JavaRanch> java -classpath .;junit.jar \
junit.textui.TestRunner com.javaranch.junit.WindowsOnlyTest
.
Time: 0.006
OK (1 tests)
But if we run it on Linux, we'll see [ejfried@laptop JavaRanch] % java -classpath .:junit.jar \
junit.textui.TestRunner com.javaranch.junit.WindowsOnlyTest
Time: 0.001
OK (0 tests)
You can use this test class as part of a TestSuite and run it on the whole herd of test servers, and the Windows-only tests will only run on the runty little calves. Fancying things upWhen you override canRun, you can make the implementation as complicated as you want. In particular, you can make it return true for some tests and false for others. The getName method of TestCase returns the name of the testXXXX method that a particular TestCase object will run. You might write a canRun method like this: public boolean canRun() {
if (getName().equals("testOracle"))
return OracleUtils.oracleIsAvailable();
else
return true;
}
Using this canRun method, the testOracle test method will only be run if the Oracle database is available; otherwise, it will be skipped. You can make all of your test classes extend JRTestCase, or only some of them. Because only JRTestCase itself knows about the canRun method, you can freely mix and match JRTestCase and TestCase objects in the same TestSuite. You can use JRTestCase only for those tests that are picky about when they should run. SummaryUsing JRTestCase, Tex can write tests that know about their external dependencies. His test suite will now pass at 100% on every server in the herd -- although on some servers, it'll be a mite smaller. Note that JUnit will report the actual number of tests run on each server. It's easy to add features to JUnit by taking advantage of the rich API provided by its framework classes, and especially by TestCase. This article is barely a drop in the bucket compared to what's possible. I hope I've got you fired up to have a look at the JUnit API documents and see what all else you might have a hankerin' to cook up. Download all of the code from this article. Return to Top |
||||||||||||||||||||||||||||||||||||||
A Case Against EJBby Chris MathewsThese days, it is becoming harder and harder for me to find cases where I think EJB is appropriate. However, that says as much or more about my personal changes in thinking and development practices as it does about EJB. This article will explore the reasons that are most often cited for using EJBs and discuss how practical they are in real-world solutions.
RemotabilityThis one is fairly easy to understand. However, most pragmatic developers now try to stay away from large distributed systems unless it is absolutely necessary. The reason is that they don't usually pay off. The perceived decoupling advantage never really pulls it weight and these systems always seem to perform like dogs. Martin Fowler had a nice article (requires registration) describing the evils of unnecessarily distributed systems in Software Development Magazine last year (from content in his PEAA book). Therefore, it is questionable how useful the distributed nature of EJBs actually is.
SecurityI don't know about you but I have never really considered J2EE Security a proper solution. There are huge gaps missing from the J2EE Specification for things such as user management and Single Sign-On (SSO). This all adds up to the fact that it is hard to pull off using J2EE Security for real-world solutions without pervasive use of vendor extensions. I thought the whole reason for including security in the spec was to allow for a portable solution. Unfortunately, reality tells a different story and, for that reason, most projects that I have ever worked on have relied third-party solutions such as Netegrity SiteMinder for security.
PersistenceDoes anybody actually like working with CMP Beans? I certainly do not. They are hard to develop (almost bearable if you are using XDoclet), hard to test (in-Container testing is the only option here), and not very flexible. Luckily, there are many other persistence options that are more than a match for CMP. My current favorite is Hibernate. This tool just rocks! It supports everything that was good about CMP and has none of the ugly warts that make using CMP such a pain. Sure you still have configuration files, but only one and it is easily managed. You can even use XDoclet to generate your Hibernate configuration file if you want. The best thing about Hibernate (and JDO for that matter) is that it works off of Plain Old Java Objects (POJOs) which make development and testing very easy.
CachingI actually think this one is a bit of a red herring, always tossed in by the big players to throw us off their trail. While some form of caching is implemented in any decent EJB Container... none of the major EJB Containers support a truly distributed cache out-of-the-box. Therefore, in a clustered environment, which is the norm for large EJB projects, a third-party solution is still required for good caching. Also consider that any good persistence tool supports some form caching as well, so EJBs still don't bring anything additional to the table. For example, Hibernate and most commercial JDO implementations also support distributed caching thru the use of third-party products such as Jakarta JCS, Tangosol Coherence, and EHCache. Whenever the JCache Specification is finally released (hurry up Cameron!) then I am sure that most will add support for that as well.
ScalabilityTo many people, EJB is synonymous with scalability. I am here to tell you that they are wrong! There is nothing about EJB that is inherently more scalable then any other technology. The real secret to scalability is that good software scales well and bad software scales poorly. This is universally true regardless of the technology that is used. An EJB Container can achieve scalability based on its ability to be clustered and load balanced. However, the same is true of most standard Servlet/JSP Containers and most other web technologies (Perl, PHP, and ASP) as well. Therefore, once again, EJB offers nothing in terms of scalability that cannot be achieved with a simpler solution. In fact, it is my experience that simpler solutions such as Servlet/JSP applications are much easier and cheaper to scale than full blown EJB applications. Remember, scalability is never free; you pay for it in the cost of designing good software.So far things aren't looking very good for our old friend EJB... but we now come to the light at the end of the tunnel: Messaging and Transactioning.
MessagingOne of the very good things to come out of the EJB 2.0 Specification was the addition of Message Driven Beans. MDBs are quite simply fantastic. This is one area of the specification that they really nailed! MDBs are easy to use, develop, and test (in this case they are easy to mock out). I don't think I ever want to work on a large-scale messaging project without the use of MDBs.
TransactioningPlain and simple - demarcating transactions in EJB is dead-easy. Using Two-Phase Commit in EJB is dead-easy. These two things hold a lot a weight for systems that have large-scale transactional requirements. In these cases using EJB makes a whole lot of sense, especially if you ever have to deal with 2PC and multiple transactional resources. I know that I am not about to try to reinvent the Transaction Manager wheel on any of my projects, it is just too risky. However, it is important to note that lightweight Frameworks such as Spring and even JBoss's Aspect Oriented Middleware are now showing up with transactional support similar to EJB that can be demarcated on POJOs. In these cases all you need is a JTA implementation and you are good to go. I don't think that this type of solution is quite ready for prime time in a high transactional volume system today but I have no doubt that at some point in the near future they will be. At that point, EJBs will lose their number one advantage.
ConclusionSo to recap... unless your project is making heavy use of transactions, messaging, or both then I think choosing EJB is a mistake. There are too many good alternatives out there to ignore. Even if EJB is chosen, I recommend keeping its use to a very limited capacity. Business logic should be encapsulated in POJOs and the persistence layer should be strictly decoupled from EJB (please no CMP). All of the above benefits of EJBs (with the exception of persistence and caching) can be easily achieved by using EJBs as a thin Decorator on top of POJOs. This type of architecture is easy to develop and test and takes full advantage of the services provided by EJB Containers.In its current form it looks to me that EJB is on its way out (except in a legacy capacity), though I admit that it is still too early to tell for sure. I guess we will just have to wait and see what is in store for us with EJB 3.0. Suffice it to say, the Expert Group has a lot of catching up to do and I just hope they have the vision and desire to do bring EJB back to the promised land. Discuss this article in The Big Moose Saloon! Return to Top |
||||||||||||||||||||||||||||||||||||||
Java Data Objects - An Introductionby Thomas Paul
The Story BeginsJava Data Objects (JDO) is a specification designed to provide a standardized way to make objects persistent in a database. JDO allows you to treat rows in your database as if they were Java objects. This is similar to other "object-relational mapping" implementations such as Hibernate and Jakarta OJB, however JDO is designed to do what these products do in a standard way.From an application developers point of view JDO serves the same role as JDBC
but it has two main advantages over writing programs using JDBC:
Coding JDOThere are actually two parts of mapping objects to rows in a database. The first part is the code that you write in your programs to create objects, get objects, update objects, and delete objects. The second part is the actual mapping of these objects to an actual database. JDO only provides implementation details for the first part. The second part is database specific and how you do the actual mapping will vary from implementation to implementation. JDO is a specification so "out-of-the-box" it doesn't actually support any database. The JDO reference implementation (JDORI), which we will take a look at, supports a pseudo-database that doesn't show how to implement with a real database but it will at least give us an idea of how to write code that uses JDO.JDO uses a datastore, which represents whatever is the source of the data that JDO will be using. This could be a relational or object database, for example. To access the datastore, JDO uses a class which implements the PersistenceManager interface. This class will be vendor specific. A class that implements the PersistenceManagerFactory interface is used to get the correct PersistenceManager for the datastore that you are accessing. Getting the correct PersistenceManagerFactory is dependent on properties that are supplied to the JDOHelper class. An example of the JDO properties (used in the example code):
javax.jdo.PersistenceManagerFactoryClass=com.sun.jdori.fostore.FOStorePMF javax.jdo.option.ConnectionURL=fostore:database/fostoredb javax.jdo.option.ConnectionUserName=root The example above specifies that the JDOHelper should find a PersistenceManagerFactory named com.sun.jdori.fostore.FOStorePMF, that it will access a datastore named fostoredb, which is found in the database directory, and that it should connect with the user id of root. The properties are passed to the getPersistenceManagerFactory( ) static method of the JDOHelper class in the form of a Properties object. An example:
PersistenceManagerFactory pmf =
JDOHelper.getPersistenceManagerFactory(properties);
A PersistenceManager can then be obtained from the PersistenceManagerFactory. An example:
PersistenceManager pm = pmf.getPersistenceManager(); JDO uses an implementation of the Transaction interface to control transaction flow for all of its functions so you will need to obtain a Transaction object in order to use JDO. A Transaction object can be created using the PersistenceManager.
Transaction tx = pm.currentTransaction();
Configuring JDORIBefore we continue, let's set up an environment that we can use to test some of these JDO commands. You will need to download the JDO reference implementation (JDORI).The download contains three jar files that you will need to add to your classpath:
In addition to these you will also need three other jar files to use the JDORI:
In order to create the datastore used in the examples, you will need to write a simple program that creates the datastore. If you are using a real implementation then you would not do this step and the properties you use to access the datastore will be different. Assuming that you have stored the properties listed above in a file called datastore.properties, your program would look something like this:
import java.io.*;
import java.util.*;
import javax.jdo.*;
public class CreateDataStore {
public static void main(String[] args) {
try {
Properties properties = new Properties();
InputStream stream = new FileInputStream("datastore.properties");
properties.load(stream);
properties.put("com.sun.jdori.option.ConnectionCreate", "true");
PersistenceManagerFactory pmf =
JDOHelper.getPersistenceManagerFactory(properties);
PersistenceManager pm = pmf.getPersistenceManager();
Transaction tx = pm.currentTransaction();
tx.begin();
tx.commit();
} catch (Exception e) {
System.out.println("Problem creating database");
e.printStackTrace();
}
}
}
Notice that we are importing the package javax.jdo. All programs that use JDO will import this package. Notice that in addition to the properties listed above we added one more entry to the Properties object that causes the datastore to be created. As per the javax.jdo.option.ConnectionURL entry in the datastore.properties file, the datastore will be created in a directory called datastore and will be given the name fostoredb.
Creating a Class to PersistNow that we have a datastore, we need to create a class that can be stored in this datastore. This class will represent a row in a table in a database. For our example, we will create a class called Book that will represent rows in a table called Book. The code for the Book class is similar to many simple JavaBean classes. The class must have a default constructor and it must have get and set methods for each of the instance variables of the class. Here is our sample class:
package com.javaranch.jdotest;
public class Book {
private String title;
private String author;
private String isbn;
private float price;
public Book() {}
public Book(String title, String author, String isbn, float price) {
this.title = title;
this.author = author;
this.isbn = isbn;
this.price = price;
}
public String getTitle() { return title; }
public String getAuthor() { return author; }
public String getIsbn() { return isbn; }
public float getPrice() { return price; }
public void setTitle(String title) { this.title = title; }
public void setAuthor(String author) { this.author = author; }
public void setIsbn(String isbn) { this.isbn = isbn; }
public void setPrice(float price) { this.price = price; }
}
Before we can use this class we need to run the class file through a JDO enhancer. The enhancer will add methods and variables to the class in order to make it manageable by the JDO implementation. Running through the enhancer can be done from the command line or as part of an ANT script. I will show the commands for each method. Before you can enhance the class file you will need to create an XML file that is used by the enhancer. This file identifies the classes that you will use and also allows you to specify special field requirements if required. The file should be stored in the same directory as the class file and should be named package.jdo. For our example, the file would look like this:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE jdo PUBLIC "-//Sun Microsystems, Inc.//DTD Java Data Objects Metadata 1.0//EN"
"http://java.sun.com/dtd/jdo_1_0.dtd">
<jdo>
<package name="com.javaranch.jdotest" >
<class name="Book" />
</package>
</jdo>
An entry must be placed in this file for each class you wish to enhance. Once you have created this file and compiled your source, you are ready to start the enhancement. Enhancement in JDORI is done using a class named com.sun.jdori.enhancer.Main. The enhancer in another implementation will be different (or may not be required). From the command line, you would do the following:
java com.sun.jdori.enhancer.Main -s classes
classes/com/javaranch/jdotest/Book.class
This assumes that we have stored our class file in a directory called classes. The result will be that the class file has been overwritten with an enhanced version. To do the same thing from an ANT script we would add an ANT task:
<!-- ===================================== -->
<!-- Enhance -->
<!-- ===================================== -->
<target name="enhance" depends="compile" >
<java fork="true" classname="com.sun.jdori.enhancer.Main">
<arg line="-s classes classes/com/javaranch/jdotest/Book.class" />
</java>
</target>
I have found that you need to run the task with fork="true" because of a problem with Xerces that causes the task to fail otherwise.
Persisting ObjectsNow that we have a datastore and an enhanced class to place in our datastore, we can write some code to get our PersistenceManager and create a Transaction object. Here is the code:
InputStream stream = new FileInputStream("datastore.properties");
Properties properties = new Properties();
properties.load(stream);
PersistenceManagerFactory pmf =
JDOHelper.getPersistenceManagerFactory(properties);
PersistenceManager pm = pmf.getPersistenceManager();
Transaction tx = pm.currentTransaction();
This code will be the same for any JDO implementation. The only difference will be the properties used to create the PersistenceManagerFactory. We can now look at some examples of using JDO. First, let's create a Book object and add it to our datastore:
Book book = new Book("Benjamin Franklin : An American Life",
"Walter Isaacson", "0684807610", 18.00f);
tx.begin();
pm.makePersistent(book);
tx.commit();
The makePersistent( ) method will cause the Book object to be stored in our datastore. Suppose we want to fetch this object from the datastore:
tx.begin(); Query q = pm.newQuery(Book.class, "isbn == \"0684807610\""); Collection result = (Collection) q.execute(); Book book = (Book)result.iterator().next(); q.close(result); A Query object is used to select objects from the datastore. Creating the Query object requires that we pass a Class object representing the table we wish to select from and a filter representing the criteria used to select objects from the datastore. JDO Query Language (JDOQL) is used to create filters. Notice that we did not commit the transaction. This was deliberate. Since we have the object, we can make changes to the object and when we commit, those changes will be persisted to the database. For example, suppose we want to update the title of this book:
book.setTitle("Paul Wheaton : An American Life");
tx.commit();
This change will be automatically written out to our datastore. Deleting our book is also simple. While we have an active transaction we can simply do this:
pm.deletePersistent(book); tx.commit(); In addition to the commit( ) method of the Transaction object, there is also a rollback( ) method that can be used to cancel any transaction.
ConclusionsJDO has several limitations that keep it from being a replacement for JDBC in all cases. The query language is implementation specific so it may not be as robust as SQL. DDL may or may not be supported. Many of the best features of JDO such as caching are also vendor specific and may or may not be available in the JDO implementation that you use. Also, JDO is still a new technology and has not been nearly as well adopted as JDBC. Will JDO take the Java world by storm? So far the verdict is still out but it is certainly a technology to keep your eye on.Return to Top |
||||||||||||||||||||||||||||||||||||||
The Coffee House |
||||||||||||||||||||||||||||||||||||||
Introduction to Code Coverage
Lasse Koskela AbstractYou might have heard of the term code coverage. If not, this article will introduce you to this fine subject. We'll also take a look at some of the tools available for Java developers and how these tools fit into a build process using Ant. What is code coverageCode coverage, in short, is all about how thoroughly your tests exercise your code base. The intent of tests, of course, is to verify that your code does what it's expected to, but also to document what the code is expected to do. Taken further, code coverage can be considered as an indirect measure of quality -- indirect because we're talking about the degree to what our tests cover our code, or simply, the quality of tests. In other words, code coverage is not about verifying the end product's quality. So, how does code coverage differ from other types of testing techniques? Code coverage can be classified as white-box testing or structural testing because the "assertions" are made against the internals of our classes, not against the system's interfaces or contracts. Specifically, code coverage helps to identify paths in your program that are not getting tested. It is because of this distinction that code coverage shows its usefulness when testing logic-intensive applications with a lot of decision points (versus data-intensive applications which tend to have much less complex decision paths). MeasuresAs always, there is more than one way to measure code coverage. We'll cover the essential measures under the broad scope of code coverage one by one, looking at where they're derived from and what do they tell to the developer. I have to warn you though: the list is long, and I have probably omitted plenty of existing code coverage algorithms out there. Furthermore, if you find my descriptions of the measures ambiguous or otherwise incomprehensible, I'm sure Google will help you in finding more thorough explorations on the details of each. Statement coverage, also known as line coverage, is a measure which indicates the degree to which individual statements are getting executed during test execution. The statement coverage measure is possibly the easiest to implement considering that it can be applied over bytecode, which is a lot simpler to parse than source code having a touch of human handiwork in it. Statement coverage is also probably the most used by developers because it is easy to associate with source code lines -- "ah, that setter really doesn't get executed when my test calls it likes this!" However, the simplicity comes with a cost: statement coverage is unable to tell too much about how well you have covered your logic -- only whether you've executed each statement at least once. Here's an example of that problem:
/**
* The statement coverage measure will report this method being fully covered
* as long as we always call the method with condition true. In fact, if our
* tests never call it with false, we have missed a serious runtime error
* even though our code coverage was at 100 percent...
*/
public String statementCoverageSample(boolean condition) {
String foo = null;
if (condition) {
foo = "" + condition;
}
return foo.trim();
}
There is a slight variation of the statement coverage measure called basic block coverage. Basic block coverage considers each sequence of non-branching statements as its unit of code instead of individual statements. This helps in overcoming such result-extorting scenarios where one branch of an if-else is much larger than the other -- statement coverage would easily report the coverage being close to 100% if the tests execute the significantly larger branch but never visit the smaller one.
/**
* Assuming that our tests invoke this method only with condition false,
* statement coverage would be approximately 98%, almost "perfect", if you will.
* Yet, we have missed a small but very important branch and possibly
* a source of lot of pain later on... Basic block coverage would consider each
* branch "equal" and report a 50% coverage, indicating that there's probably
* room for improvement in our tests.
*/
public void bigBranchSample(boolean condition) throws ApplicationException {
if (condition) {
System.out.println("Small branch #1");
throw new ApplicationException("You should have tested me!");
} else {
System.out.println("Big branch #1");
System.out.println("Big branch #2");
System.out.println("Big branch #3");
System.out.println("Big branch #4");
...
System.out.println("Big branch #98");
}
}
Decision coverage (also known as branch coverage) is a measure based on whether decision points, such as if and while statements, evaluate to both true and false during test execution, thus causing both execution paths to be exercised. Decision coverage is also relatively simple, which is both its pro and its con. The downside is that the measure doesn't take into consideration how the boolean value was gotten -- whether a logical OR was short-circuited or not, for example, leaving whatever code was in the latter part of the statement unexecuted.
if (amount > 100 || someCode() == 0) {
// Did someCode() get executed? Decision coverage doesn't say...
doSomething();
} else {
doSomethingElse();
}
This deficit of the decision coverage measure is tackled to some degree by condition coverage, which extends the boolean evaluation of decision coverage into the sub-expressions (separated by logical ANDs and ORs) as well, making sure each of them is evaluated to both true and false. However, condition coverage is not a true superset of decision coverage because it considers each sub-expression independently, not minding about whether the complete expression is evaluated both ways. But wait, there's more. We have a measure called multiple condition coverage, which also takes into consideration the whole expression as well as the sub-expressions. This, however, often causes the number of required test cases to explode if the code under test employs complex boolean expressions. Making multiple condition coverage high does lead to thorough testing, but one really must consider whether the line of decreasing returns has been reached already... Moving on, path coverage represents yet another interesting measure. Path coverage measures whether each possible path from start (method entry) to finish (return statement, thrown exception) is covered. Note that this is different from checking whether each individual decision is made both ways. Path coverage has its problems as well. For example, it is sometimes impossible to rate well with regard to path coverage if the code under test includes subsequent branching statements with such expressions that always evaluate the same -- it's impossible to test all theoretical combinations of those paths if the expressions have constraints with each other. The example below illustrates this problem. Another possible problem scenario is loops because they represent a huge range of possible paths (does this loop execute 0, 1, 5, or 1000 times?). There are some variations to the path coverage measure that try to tackle this problem, mostly by simplifying the problem to a manageable size, for example by considering loops to have only two possible paths; zero or more rounds (or one or more in the case of do-while).
/**
* Path coverage considers this method having four possible paths but because
* the branching is constrained into a single boolean, we can never execute
* "A1, B2" or "B1, A2"
*/
public void pathCoverageSample(boolean foo) {
if (foo) {
System.out.println("Path A1");
} // the else-branch would be "Path B1"
// ...
if (foo) {
System.out.println("Path A2");
} // the else-branch would be "Path B2"
}
Function coverage is a measure for verifying that each function (method) is invoked during test execution. In all its simplicity, function coverage is a very easy way to spot the biggest gaps in your code coverage. One of the more advanced code coverage measures I though I should mention is race coverage, which considers multiple threads executing code simultaneously, thus, helping detect shared resource access problems. These types of measures are seldom used in other than testing software such as operating systems. Still, we have relational operator coverage, which measures whether expressions with relational operators (<, <=, >, >=) in them are exercised with boundary values. For example, if the expression (a < 4) is executed with values of 2, 3 and 5, the relational operator coverage would report the expression as not covered -- the boundary value a == 4 was not tested. Yes, you guessed correct. This coverage was invented to catch those oh-so-common one-off errors... So, after listing some of the different algorithms out there, "what are the ones I need to know," you might ask. "Which of those should I use?" Let me post-pone answering that one until later, ok? Let us just move on to what existing tools have to offer to us, and we'll get back to that question in the wrap-up. ToolsToday, the developer community is in a relatively good situation regarding the availability of high-quality code coverage tools. We'll only take a look at a few, but there are lots more out there -- most are for sale, but some are free or even open source. First, let's start by looking at how code coverage measures are generally implemented. Implementation techniquesTo my knowledge, the implementations can be categorized into two distinct implementation approaches:
So, we have some idea how the code coverage tools at our disposal. Are you itching to find out what kind of features these tools typically boast? (Except for running those boring algorithms, of course) Typical featuresThe feature sets, quality and usability of code coverage products vary significantly. I have listed here some of the most essential features from the point of view of usability.
Now that we've covered some of the core features in modern code coverage tools, let's take a look at how they fit into our existing Ant build script and what does the outcome look like. Code coverage in action: samples with Clover, JCoverage and GroboUtilsSample applicationOur sample application is something I recently wrote on my spare time. The actual application, however, is of little importance. Our main focus is the structure of the project directory and the Ant build script, the build.xml file.
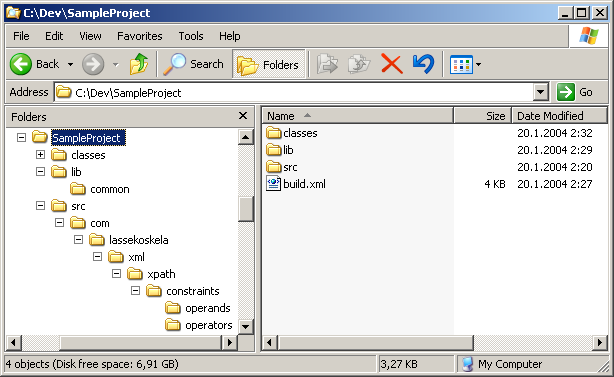
As you can see from the above screenshot, the project directory contains only three directories (of which "classes" is generated by the build) and one Ant script. The initial version of our Ant script, which we will extend by introducing three different code coverage tools, is listed below:
<project name="CodeCoverageArticle" default="all" basedir=".">
<property name="src.dir" value="src"/>
<property name="lib.dir" value="lib"/>
<property name="lib.common" value="${lib.dir}/common"/>
<property name="build.classes.dir" value="classes"/>
<path id="compile.classpath">
<fileset dir="${lib.dir}/common">
<include name="*.jar"/>
</fileset>
</path>
<path id="test.classpath">
<pathelement location="${build.classes.dir}"/>
<path refid="compile.classpath"/>
</path>
<target name="init">
<mkdir dir="${build.classes.dir}"/>
</target>
<target name="compile" depends="init">
<javac srcdir="${src.dir}" destdir="${build.classes.dir}" debug="true">
<classpath refid="compile.classpath"/>
</javac>
</target>
<target name="clean">
<delete dir="${build.classes.dir}"/>
</target>
<target name="all" depends="clean, compile, test"/>
<target name="compile.tests" depends="compile">
<javac srcdir="${src.dir}" destdir="${build.classes.dir}">
<classpath refid="test.classpath"/>
</javac>
</target>
<target name="test" depends="compile.tests">
<junit printsummary="true">
<classpath location="${build.classes.dir}"/>
<classpath refid="test.classpath"/>
<batchtest fork="yes" todir="${reports.tests}">
<fileset dir="${src.dir}">
<include name="**/*Test*.java"/>
<exclude name="**/AllTests.java"/>
</fileset>
</batchtest>
</junit>
</target>
</project>
Common integration stepsRegardless of which of the three demonstrated products are used, there are a number of similarities that can be handled uniformly, separating the minor details from the actual code coverage tasks. The common changes to our initial build.xml are as follows:
I've highlighted the changes in the following, extended version of our Ant script:
<project name="CodeCoverageArticle" default="all" basedir=".">
<property name="src.dir" value="src"/>
<property name="lib.dir" value="lib"/>
<property name="lib.common" value="${lib.dir}/common"/>
<property name="build.classes.dir" value="classes"/>
<property name="build.instrumented.dir" value="instrumented"/>
<property name="coverage.toolname" value="XXXXX"/>
<property name="lib.coverage" value="${lib.dir}/${coverage.toolname}"/>
<property name="reports.dir" value="reports"/>
<property name="coverage.report" value="${reports.dir}/${coverage.toolname}"/>
<path id="compile.classpath">
<fileset dir="${lib.dir}/common">
<include name="*.jar"/>
</fileset>
</path>
<path id="coverage.classpath">
<fileset dir="${lib.coverage}">
<include name="*.jar"/>
</fileset>
</path>
<path id="test.classpath">
<pathelement location="${build.instrumented.dir}"/>
<pathelement location="${build.classes.dir}"/>
<path refid="compile.classpath"/>
<path refid="coverage.classpath"/>
</path>
<target name="init">
<mkdir dir="${build.classes.dir}"/>
<mkdir dir="${build.instrumented.dir}"/>
<mkdir dir="${reports.dir}"/>
</target>
<target name="compile" depends="init">
<javac srcdir="${src.dir}" destdir="${build.classes.dir}" debug="true">
<classpath refid="compile.classpath"/>
</javac>
</target>
<target name="clean">
<delete dir="${build.classes.dir}"/>
<delete dir="${build.instrumented.dir}"/>
<delete dir="${reports.dir}"/>
</target>
<target name="all" depends="clean, compile, test"/>
<target name="compile.tests" depends="compile">
<javac srcdir="${src.dir}" destdir="${build.classes.dir}">
<classpath refid="test.classpath"/>
</javac>
</target>
<target name="test" depends="compile.tests">
<junit printsummary="true">
<classpath location="${build.instrumented.dir}"/>
<classpath location="${build.classes.dir}"/>
<classpath refid="test.classpath"/>
<batchtest fork="yes" todir="${reports.tests}">
<fileset dir="${src.dir}">
<include name="**/*Test*.java"/>
<exclude name="**/AllTests.java"/>
</fileset>
</batchtest>
</junit>
</target>
</project>
The only thing left to do is the tool-specific part, the proprietary Ant tasks for performing the instrumentation and reporting at suitable stages of the build process. This is what the following sections are focused on. Integrating CloverClover is a commercial code coverage tool, which has the market leader status. There was a time when Clover was light-years ahead of others, but the competition has gotten tougher lately. Clover is still very much a top dog when it comes to code coverage and it has had most of its rough edges removed within the past couple of years. (Although Clover is commercial, it is possible to apply for a free license if you're an open source project or another not-for-profit organization!) So, let's see what kind of additions was needed in order to get Clover up and running! The following snippet of build-clover.xml illustrates what this last step means in the case of Clover. I have commented the targets and tasks where I saw the need to.
<!--
- These definitions cause Ant to load the Clover Ant tasks and the types it uses
-->
<taskdef classpathref="coverage.classpath" resource="clovertasks"/>
<typedef classpathref="coverage.classpath" resource="clovertypes"/>
<!--
- This is the instrumentation step. Clover uses a data file ("cloverdata/coverage.db")
- for storing the coverage data collected during test execution, as well as
- a data directory ("cloverdata/history") for storing the historical traces needed
- for report generation.
-->
<target name="instrument">
<mkdir dir="cloverdata/history"/>
<mkdir dir="${build.instrumented.dir}"/>
<clover-setup initstring="cloverdata/coverage.db"
tmpdir="${build.instrumented.dir}"
preserve="true">
<files> <!-- instrument only application code, not test code -->
<exclude name="**/*Test.java"/>
<exclude name="**/AllTests.java"/>
</files>
</clover-setup>
</target>
<!--
- This is the reporting step. For the "current" task, Clover reads the coverage
- data file ("cloverdata/coverage.db") and produces a HTML report to the
- specified directory. For the "historical" task, Clover mines the history
- storage directory ("cloverdata/history") and produces a nice HTML graph
- to the specified directory.
-->
<target name="report">
<clover-historypoint historyDir="cloverdata/history"/>
<clover-report>
<!--
- Generate the "regular" code coverage report.
-->
<current outfile="${coverage.report}/coverage">
<fileset dir="${src.dir}">
<exclude name="**/*Test.java"/>
<exclude name="**/AllTests.java"/>
</fileset>
<format type="html"/>
</current>
<!--
- Generate a code coverage history report.
- Note that this step will fail until you have run the regular
- report at least twice (i.e. until you have enough data as
- the history)
-->
<historical outfile="${coverage.report}/history"
historyDir="cloverdata/history">
<format type="html"/>
<overview/>
<coverage/>
<metrics/>
<movers/>
</historical>
</clover-report>
</target>
<!--
- This is the "main" target to run when you want a code coverage report
- being generated. The sequence of dependency targets indicates the stage
- where each Clover-task is performed. Note that instrumentation is
- performed *before* compiling the sources!
-->
<target name="runcoverage" depends="clean, instrument, compile, test, report"/>
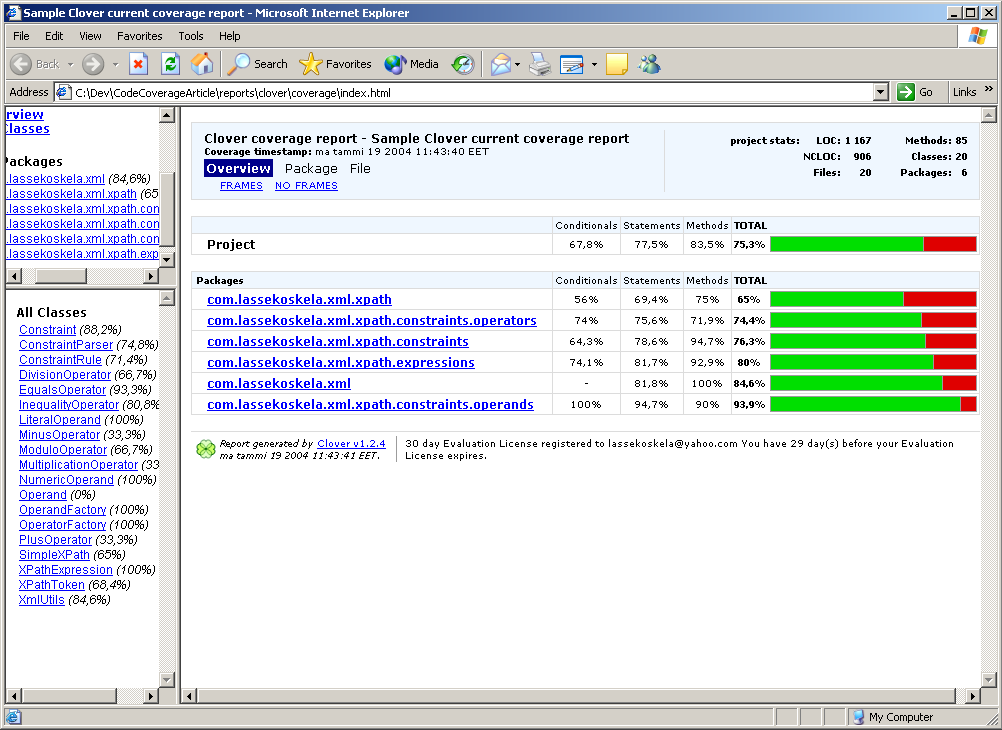
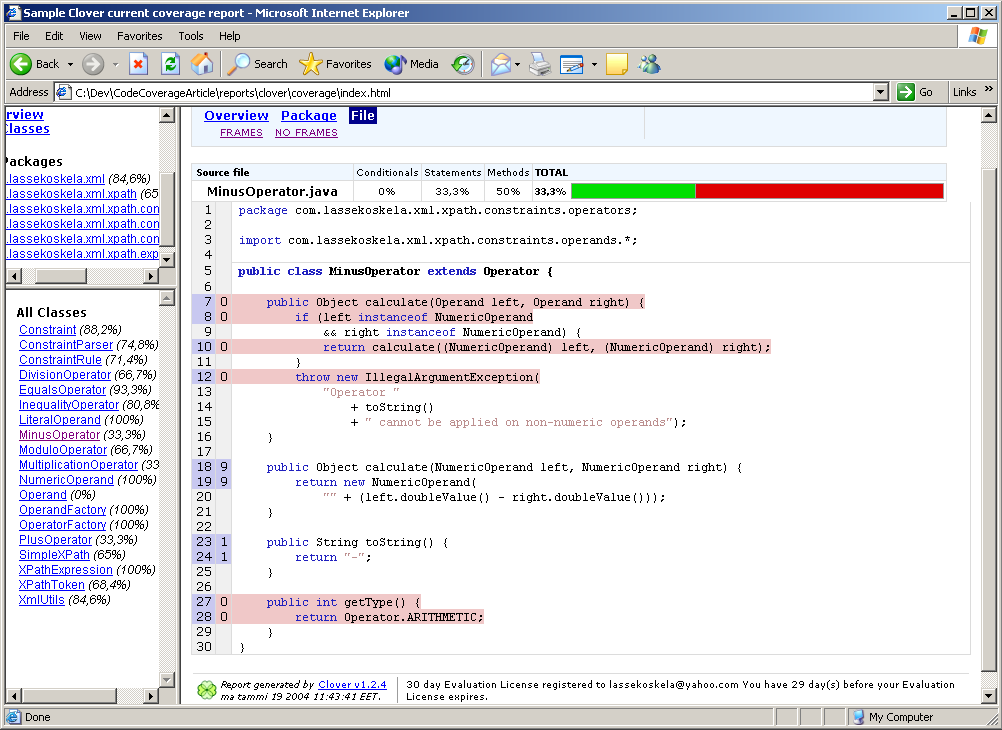
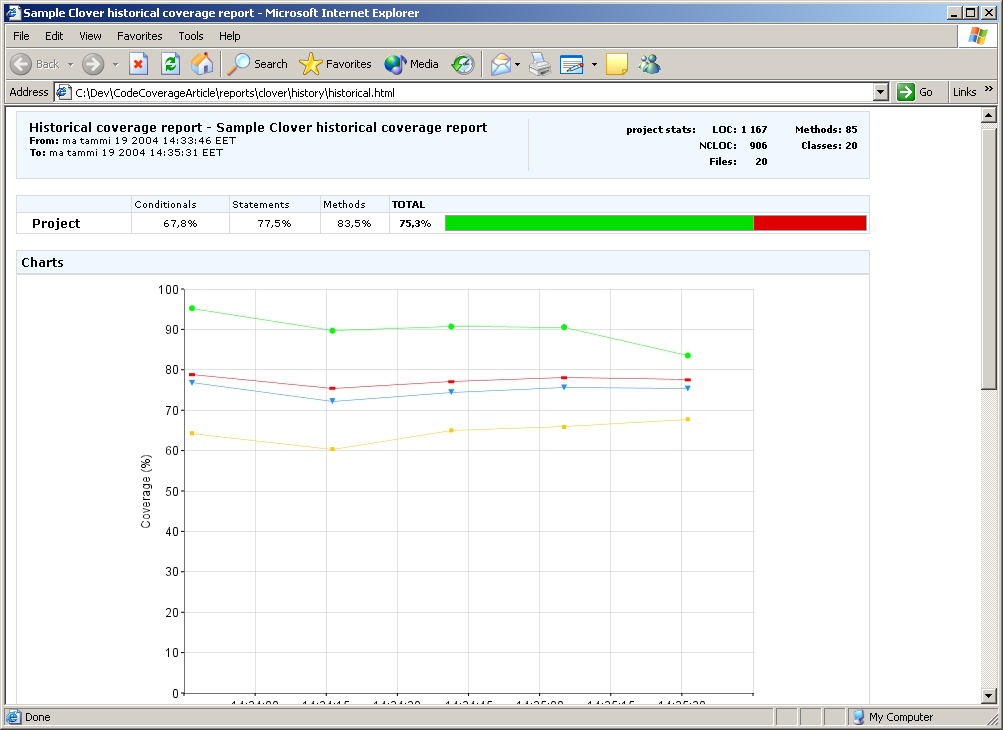
That's it. Not too complicated, is it? Finally, here's what the reporting target spits out:
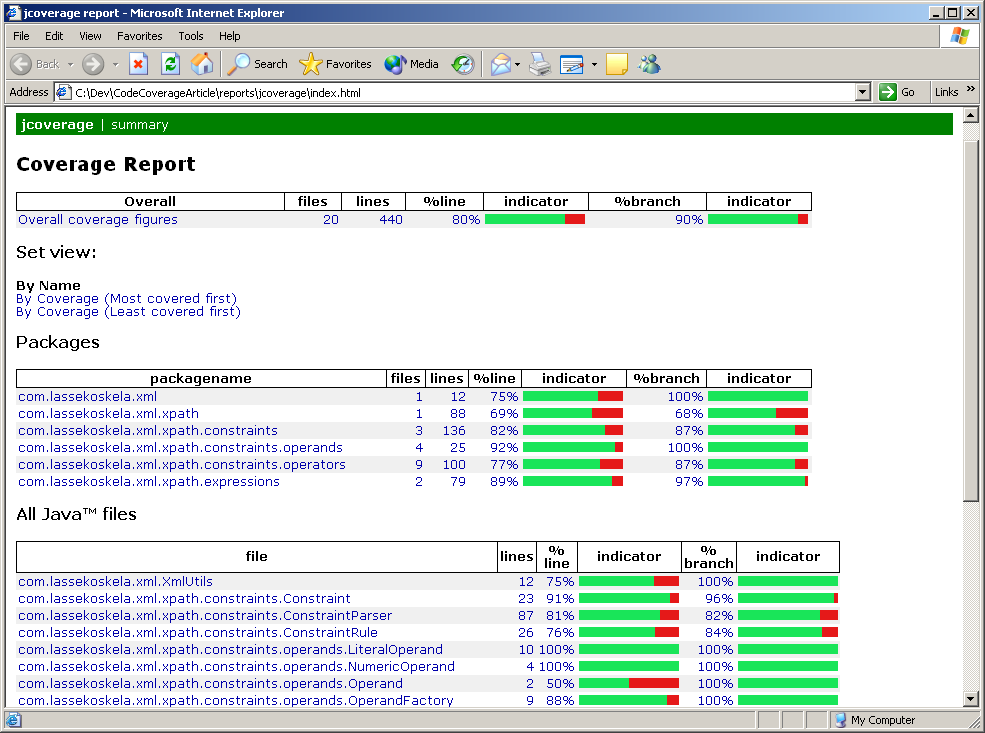
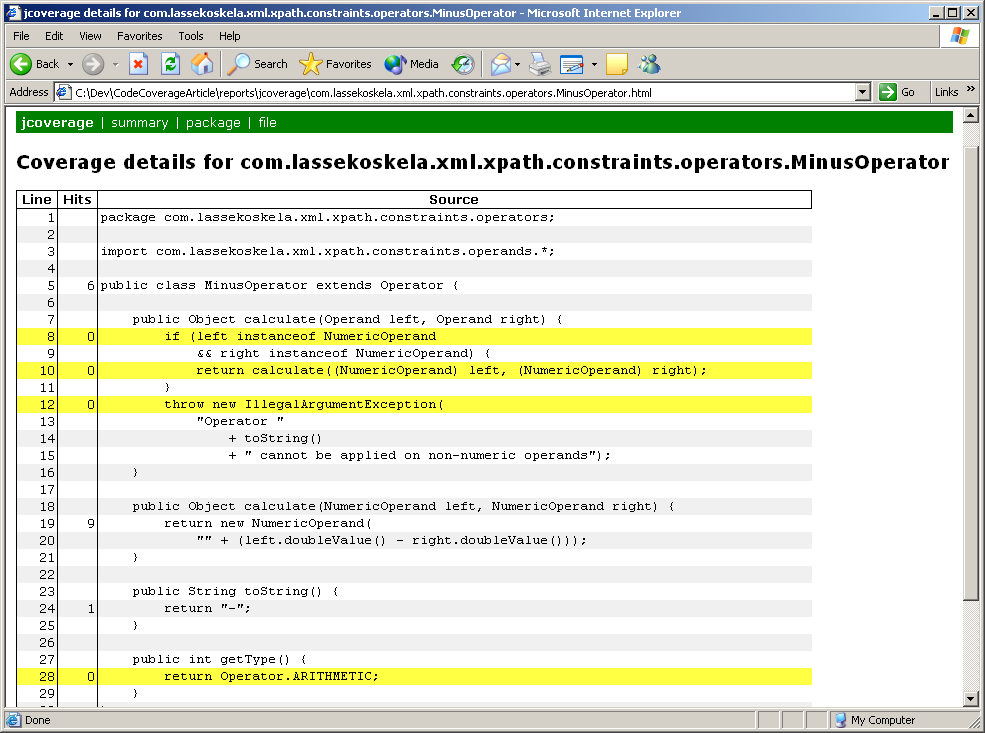
Integrating JCoverageJCoverage is a code coverage tool developed by a company with the same name. There are different editions of JCoverage, each of them adding some kind of "advanced" features over the core code coverage functionality, which is available with a GPL license. The feature set and usability of JCoverage is top-notch, which makes it a considerable contender against Cortex eBusiness' Clover -- especially with its GPL licensed version. Again, what follows is an annotated snippet of what needs to be added into our generic build script:
<!--
- These definitions cause Ant to load the JCoverage Ant tasks
-->
<taskdef classpathref="coverage.classpath" resource="tasks.properties"/>
<!--
- This is the instrumentation step. JCoverage uses a data file
- ("jcoverage.ser" by default) for storing the coverage data collected
- during test execution
-->
<target name="instrument">
<!--
- Instrument the specified files into the given directory.
-->
<instrument todir="${build.instrumented.dir}">
<ignore regex="org.apache.log4j.*"/>
<fileset dir="${build.classes.dir}">
<include name="**/*.class"/>
<exclude name="**/*Test.class"/>
<exclude name="**/AllTests.class"/>
</fileset>
</instrument>
</target>
<!--
- This is the reporting step. For the "current" task, Clover reads the coverage
- data file ("cloverdata/coverage.db") and produces a HTML report to the
- specified directory. For the "historical" task, Clover mines the history
- storage directory ("cloverdata/history") and produces a nice HTML graph
- to the specified directory.
-->
<target name="report">
<report srcdir="${src.dir}" destdir="${coverage.report}"/>
<report srcdir="${src.dir}" destdir="${coverage.report}" format="xml"/>
</target>
<!--
- This is the "main" target to run when you want a code coverage report
- being generated. The sequence of dependency targets indicates the stage
- where each JCoverage-task is performed. Note that instrumentation is
- performed *after* compiling the sources because JCoverage relies on
- bytecode manipulation!
-->
<target name="runcoverage" depends="clean, compile, instrument, test, report"/>
As you can see, JCoverage's Ant tasks are slightly easier to use than Clover's relatively complex tasks. Next, HTML reports a la JCoverage:
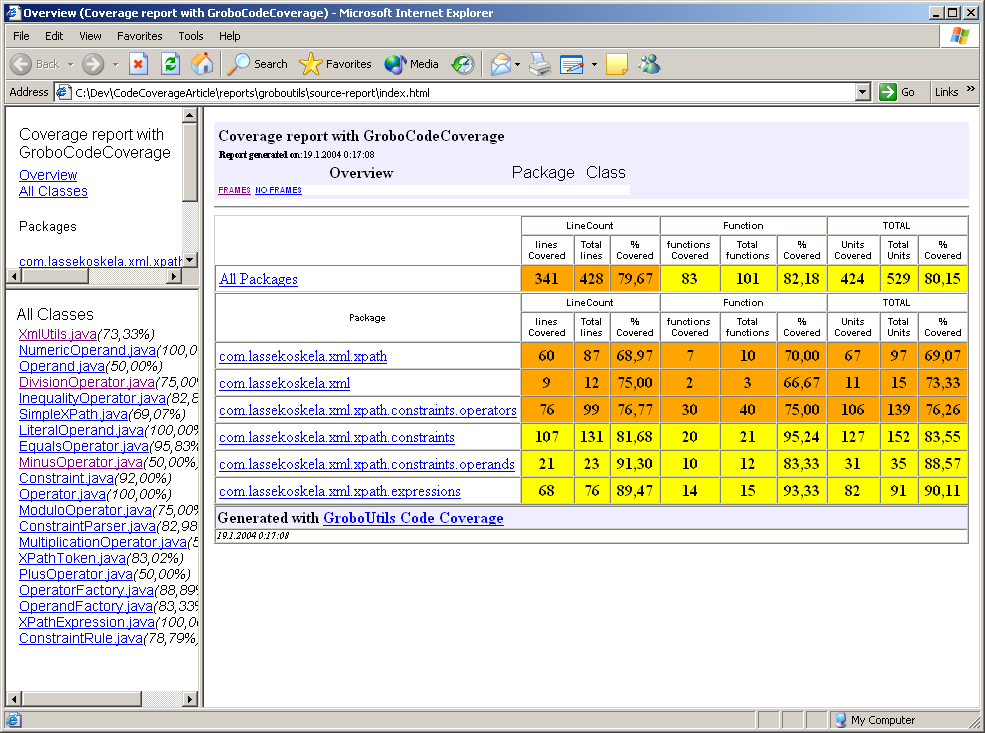
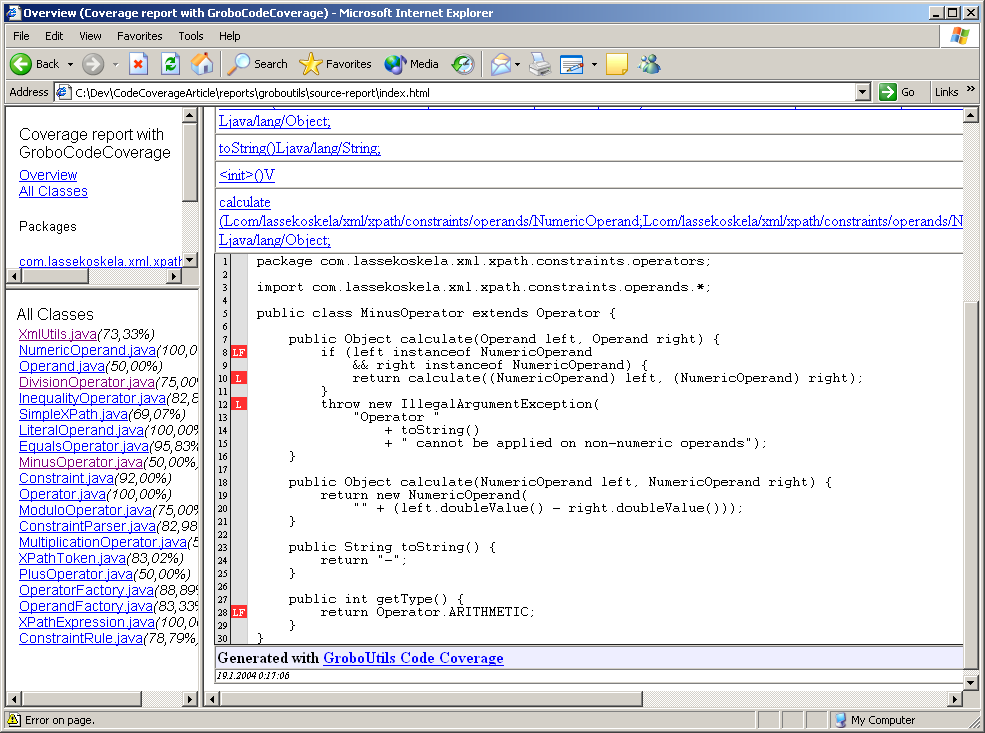
Integrating GroboUtilsThe third and last of our example code coverage tools is the code coverage module of the GroboUtils open source project hosted at SourceForge. GroboUtils is still a bit rough in the edges, but has gone through some major developments lately in the hands on the lead developer, Matt Albrecht. These rough edges show up as slightly more complicated Ant integration, a rugged look and feel of the generated HTML reports, and significantly slower execution of the build script. Regardless of these disadvantages, GroboUtils is likely to soon become a serious competitor and is something to keep an eye out for. First, here's the additional part to our Ant script:
<!--
- These definitions cause Ant to load the GroboUtils Ant tasks
-->
<taskdef resource="net/sourceforge/groboutils/grobocoverage.properties">
<classpath refid="coverage.classpath"/>
</taskdef>
<!--
- This is the instrumentation step. GroboUtils uses directories
- for storing the coverage data collected during test execution.
- The included coverage algorithms (linecount, function) are specified
- for the instrumentation task at this stage.
-->
<target name="instrument">
<mkdir dir="${coverage.report}/data"/>
<mkdir dir="${coverage.report}/logs"/>
<coveragepostcompiler datadir="${coverage.report}/data"
outclassdir="${build.instrumented.dir}">
<fileset dir="${build.classes.dir}">
<include name="**/*.class"/>
<exclude name="**/*Test.class"/>
<exclude name="**/AllTests.class"/>
</fileset>
<analysismodule name="linecount"/>
<analysismodule name="function"/>
<logsettings logdir="${coverage.report}/logs"/>
</coveragepostcompiler>
</target>
<!--
- This is the reporting step. GroboUtils reads the coverage data directory
- data and processes report generator XSL stylesheets in order to
- generate the report, which in our case happens to be the one that
- includes source code linking ("sourcestyle").
-->
<target name="report">
<coveragereport datadir="${coverage.report}/data"
logdir="${coverage.report}/logs"
outdir="${coverage.report}">
<sourcestyle destdir="${coverage.report}/source-report"
removeempty="true" srcdir="${src.dir}"
title="Coverage report with GroboCodeCoverage"/>
</coveragereport>
</target>
<!--
- This is the "main" target to run when you want a code coverage report
- being generated. The sequence of dependency targets indicates the stage
- where each GroboUtils-task is performed. Note that instrumentation is
- performed *after* compiling the sources because GroboUtils relies on
- bytecode manipulation!
-->
<target name="runcoverage" depends="clean, compile, instrument, test, report"/>
And here's what the outcome looks like:
SummaryWell, well. We've covered quite a bit of ground regarding code coverage tools for Java development. We've discussed some algorithms used to produce measures of code coverage and we have quickly enumerated the ways that code coverage tools are generally implemented. We also saw how a number of code coverage tools can be integrated to an Ant build script and what kind of reports these tools can produce. So, back to the question, "what are the code coverage measures I should use?" The answer is, I can't say. Each tool supports a different subset of the algorithms and each tool has its own little accent. The best advice I can give you regarding the use of code coverage as part of your development practices is, whatever you do, do it consistently. In other words, pick any combination that sounds good, and stick with them. You'll see everything you need to see by looking at how the green bar progresses -- how exactly is the length of that bar calculated is a minor detail. Code coverage analysis is not a silver bullet but simply an alarm bell. And sometimes it might ring without reason. I hope you enjoyed reading this. If you found code coverage analysis to be something you might benefit from, check out one of the tools I've listed in Resources and have a go at it. ResourcesAs I know you're itching to get started, I've gathered all the necessary links to spare you some time and let you get on with the scratching ;)
Discuss this article in The Big Moose Saloon! Return to Top |
||||||||||||||||||||||||||||||||||||||
How my Dog (almost) learned a Lesson about measuring Project Velocityby Dirk SchreckmannThe sun had been down about an hour and a half. Clover, the ranch dog, was sleeping in the back seat of the ol' JavaRanch pickup truck, and we'd just got on the highway headed back to the ranch. She was tired! It had been a long, fun and exhausting day of running around, making sure all of the different animals on the ranch played nice. I just about fell down myself, I was so worn out watching Clover chase after that cat and those mice playing that shifty game of theirs. Yep, Clover was dead to the world in the back of the truck. My head was feeling a bit numb, as well. We'd only been driving a few miles, when we were suddenly surrounded by bright flashing lights. Everything around was lit up all blue, red, and white. It wasn't the aliens this time, though. We were in luck - it was Officer Vick! I pulled the truck right over and waited eagerly. Me: "Howdy, Officer Vick! What can we do for you, tonight?" Officer Vick: "You got any idea how fast you were going back there?" Me: "Well, no sir. We weren't really paying that much attention. I know they say we should be, but I'm just not sure how that all -- " Officer Vick: "Save it. I've heard the excuses before. Too many folks around these parts just aren't paying attention to what's important. Ya'll just don't know how, and you must not understand how this information is useful." Me: "OK then, Officer Vick, how does this measuring of our velocity work?" Officer Vick: "It ain't too tough, really. Let's say you want to get from here on down to Pleasanton. If you look at your map, you'll notice that the trip has about forty or so different legs. Now, how long you think it would take you two to get there?" Me: "Shoot, I don't know. How many miles are we talking?" I asked as I got out my road map. Officer Vick: "Miles, nothing. Ain't much you can tell from the number of miles. If them's freeway miles, it's a whole different ride than if they're ol' unmarked backcountry dirt roads." Me: "Too true." Officer Vick: "Now, here's what ya gotta do. Don't try to guess how long the whole trip is going to take. You haven't driven down all of these roads before. You just don't know enough to estimate the whole trip very well. "As I was saying before, this here trip has about forty legs. What you should do is consider each leg, one at a time, and estimate about how much effort that leg will take you to complete." Me: "OK, that should be easy enough. This first leg, I'd guess it'll take about fifty minutes." Officer Vick: "No, dang nabbit! Forget time measurements. Like I was saying, you ain't never driven down most of these roads. Your time guestimates are gonna be about worthless." Me: "Well, how should I measure then?" Officer Vick: "What do you got a lot of sittin' around the ranch these days?" Me: "We just piled up a bunch of feed bags in the barn, the other day. Gettin' ready for -- " Officer Vick: "Feed bags will do just fine. We'll do the estimating in feed bags. Here's what you do. Consider an average leg of the trip to require about three feed bags of effort. Then a super easy leg should be about one feed bag, while the really hard parts would take up to five feed bags. Of course, the stuff in between 'really easy' and 'average' should be estimated at two feed bags, and the stuff in between 'average' and 'really hard' would be four feed bags." Me: "Well, OK. If I look at this planned route, and say I estimate that it'll take about a hundred and twenty feed bags of effort, just what good does that do us?" Officer Vick: "Perhaps not much at first. But soon after you get underway, you're gonna start to get a pretty good idea of things. "About how long would you say can Clover back there go before she needs a watering stop?" Me: "Two hours, I suppose." Officer Vick: "That'll work just fine. Now, every two hours along your trip, while Clover is out helping the local plant life, you'll want to add up just how many feed bags you completed since your last watering stop. After a couple of stops, you should have a pretty good idea of how much ground ya'll can cover during each two hour period. That's how fast you're going. With that information, you'll be able to estimate how much time you'll be needing for the rest of the trip, as well as for any new parts of the trip you decide to add. "Next time we meet, we'll get into a bit more about figuring how fast you're moving during a particular two hour period when compared to other periods, and a bit of the details on using all of this estimation information for figuring out things on your trip. Until then, let me leave you with one piece of advice to keep in mind. Pay special attention to your five feed bag estimates. Many a times I've seen that these 'really hard' efforts should really be considered as more than one effort. What I mean is, if it makes sense to break a five feed bag leg into more than one part, perhaps a two feed bag leg and a three feed bag leg, then do it. Sometimes you'll even find that the different parts should be estimated a bit higher, perhaps as two three feed bag legs, thus improving your overall estimating. "All right. Now, take care ya'll and drive safe." Me: "Good night, Officer Vick. Thanks for the lesson!" I turned 'round and asked Clover if she'd got all what Officer Vick had just taught us. I think she might have snored or something. Probably dreamin' about chasing after cats and mice. She was still out cold. Discuss this article in The Big Moose Saloon! Return to Top |
||||||||||||||||||||||||||||||||||||||
Announcing the JavaRanch Radio!Some of ya'll may have noticed it already. JavaRanch recently added a new feature - The JavaRanch Radio. It's the place to go to keep up to date on all of the new happenings around the Ranch. Things like announcing new book promotions, new book reviews, hot conversations in the Saloon, new Bartenders, and new editions of the JavaRanch Journal. So, check 'er out, and do let us know what ya think. See ya 'round the Ranch! Discuss the Radio in The Big Moose Saloon! Return to Top |
||||||||||||||||||||||||||||||||||||||
Discuss this book review in The Big Moose Saloon! Return to Top |
||||||||||||||||||||||||||||||||||||||
Following are the scheduled book promotions remaining in January and early February:
Return to Top |
||||||||||||||||||||||||||||||||||||||





 Enterprise Java Programming with IBM WebSphere, Second Edition
Enterprise Java Programming with IBM WebSphere, Second Edition Enterprise J2ME: Developing Mobile Java Applications
Enterprise J2ME: Developing Mobile Java Applications J2EE Web Services
J2EE Web Services Servlets and JSP: The J2EE Web Tier
Servlets and JSP: The J2EE Web Tier Developing J2EE Applications with WebSphere Studio: IBM Certified Enterprise Developer (IBM Certification Study Guides)
Developing J2EE Applications with WebSphere Studio: IBM Certified Enterprise Developer (IBM Certification Study Guides) Art of Java Web Development: Frameworks and Best Practices
Art of Java Web Development: Frameworks and Best Practices Pragmatic Unit Testing
Pragmatic Unit Testing